-

Fire Map used to generate dataset
-

Example from open-source dataset
-

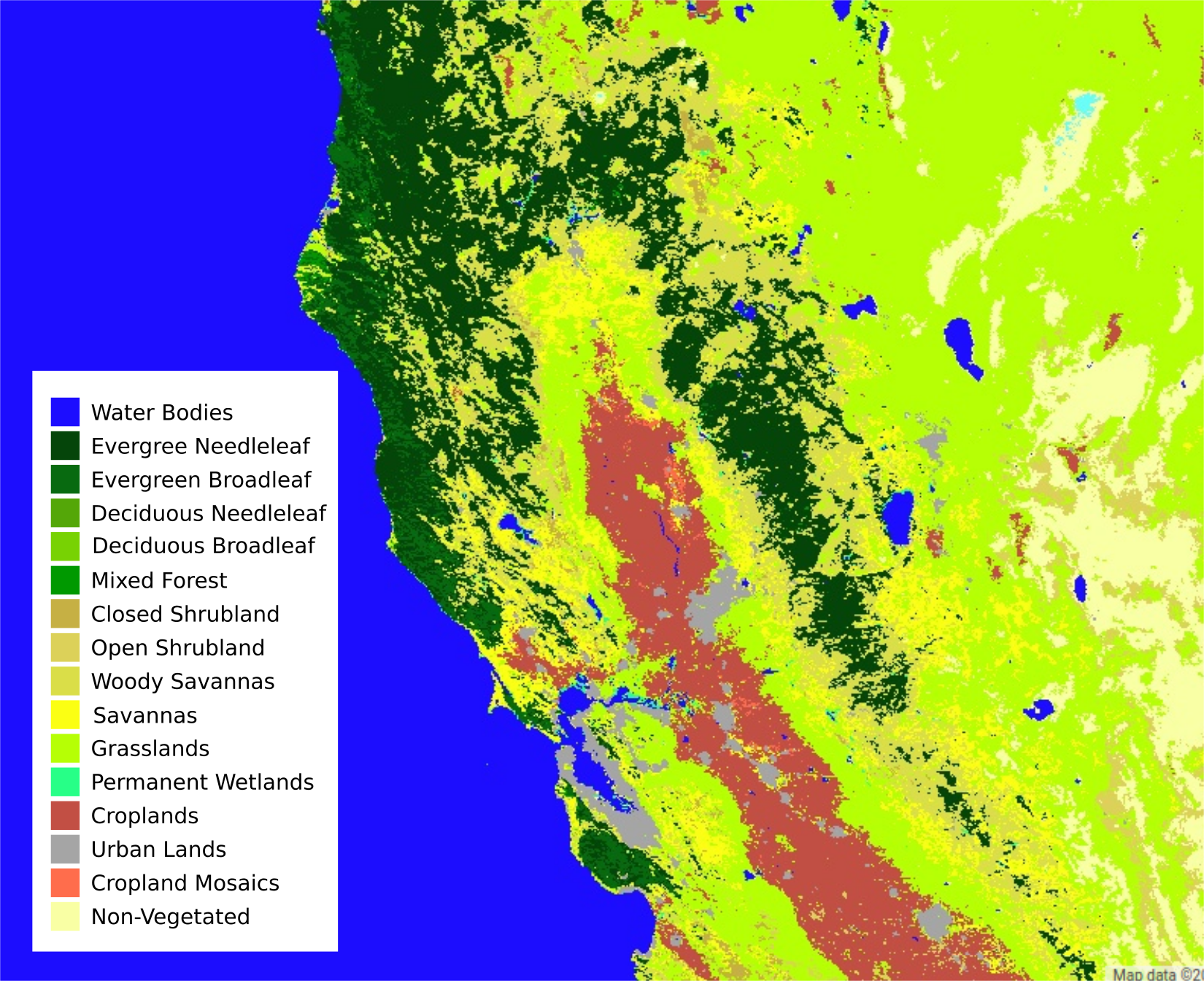
The lookup table we built for different land cover types at every coordinate
-

EVI Index for Vegetation Coverage
-

Leaf Coverage
-

Coverage are we looked at
-

Example of using Google Earth Engine





Inspiration
Recent droughts, weather anomalies, and aging electrical infrastructure has recently led to an increase in devastating California wildfires. Just last year, the November 2018 Camp Fire burned 153,000 acres and 14,000 personal homes. Not only was the loss of properly destructive, but over 85 lives were lost. As several of us are California natives, it is sad to see this type of destruction as these fires grow in intensity each and every year. The thought of having to evacuate at a moment’s notice with fear for your life is scary, and it is heartbreaking to see communities literally burned to the ground, forcing people to re-start somewhere new.
Currently, there is not a great way of alerting people of fire danger levels. To many, the PG&E power shut offs in late 2019 seemed confusing and random, and responses to fires are often marred by misinformation and chaos. Bringing automation to help better predict where these fires will pop up, and making this information easily accessible to both the public and first-responders could be a major force for good.
What it does
Ember Alerts is a predictive model that determines fire ignition likelihood and spread probability at a given location using recent weather conditions, land cover type, vegetation levels, and other factors. The system is trained on a dataset we built from scratch that found a historical fire locations and the model inputs at those locations. Ember Alerts provides a visual tool to improve the accuracy of fire prediction to keep communities safer and more alert.
How we built it
Gathering coordinates and dates from historical fire data in California from Google Earth Engine Creating a list of features relating to weather, and then making thousands of calls to the DarkSky API based on date, latitude, and longitude. In the end, we have a large CSV file with labeled data which we then used to train our Tensorflow model. Created a custom Tensorflow model using neural networks to output probability of fire based on weather conditions input to the model. Trained and tested the model for accuracy on over 4000 input examples Deployed model on historically active days in California fire history to see our predictions in action and display these probabilities visually on a map.
Challenges we ran into
Data Acquisition
The biggest challenge was data acquisition and preparation. With only a short amount of time and a lot of data needed to train our ML model, it took longer than we thought to fuse data from different sources, as there was no good single wildfire data source. For example, not only did we need to collect historical fire coordinate data and vegetation type from layers on Google Earth Engine, but we had to then use this information to make thousands of calls to the DarkSky API. This effort took a lot of time, and in the end we would have liked to add even more information to train on besides weather data, but simply didn't have the time.
Accomplishments that we're proud of
Data utilization from Google Earth Engine. Earth Engine provides an immense dataset that was difficult to manipulate and export. We spent quite a few hours collecting and assembling our active fire data set that included 1400 burns across 3 years in our area of interest. Ability to fuse data from various sources, creating an efficient method to gather data that is a solid base should we want to add more training data in the future to create better models We open sourced our existing dataset and codebase so others can try to improve prediction with even larger data sources. Tackling all major parts of the machine learning in a short amount of time, all the way from planning and data collection to model development, training, and testing
What we learned
From this project, not only did we learn new technical skills relating to the use of APIs such as Google Earth Engine and Dark Sky API, but we learned the process of creating and deploying a machine model from scratch. The machine learning process takes a lot of effort on the front end for planning of features to include as well as extracting and combining meaningful data from different sources. We learned as a team how to split off this process efficiently, and we are proud of what we were able to accomplish over the weekend.
What's next for Ember Alerts
The next step for Ember Alerts would be to train the model on more data, and to add more features of an application. For example, if given more time, we would have liked to collect and incorporate more types of information, including classification for type of vegetation at certain coordinates. Another factor we would have liked to include is using satellite imagery itself as another input to the model.
With regards to the application, we would like to build a fire prediction map that incorporates each city in California. The idea would be that this map could refresh every few hours and display probabilities on a map. This could be used by authorities, fire departments, and citizens of a local community to take precautionary measures and monitor high risk areas.
Social Impact Component and Ethical Considerations of the Platform
We want to consider both the social impact of how this product can serve society and also note how we can take measures to not inadvertently introduce biases and disparities.
Ethical significance and social impact.
- We attempt to directly serve a massive societal issue of uncontrolled wildfires, which have plagued places like California, Washington, and Australia. According to a NFPA report, in 2015, a total of 1.3 million fires occurred in just the US, resulting in $14.3 billion loss, 15700 civilian fire injuries, and 3280 civilian fire fatalities. Our product seeks to provide firefighters and forest managers with a huge information advantage, by using a variety of streams of data to help gauge risk-level and drive fire-prevention and fire-fighting strategy.
- Even a 5% improvement on current fire-fighting measures, for example, would yield massive social benefit. It is known that wildfires like all natural disasters, disproportionately affect those who are low income (NPR 2018). Whether these groups are communities of color or working class families, we believe this service could contribute to the larger goals and our “collective values” of social justice, equality, and human rights.
Ethics of the platform.
- We want to ensure that our service focuses on improved fire detection and early warning for all geographies and sectors of society. Our service may, however, still bias toward having better predictions in wealthier areas that have more weather stations and therefore better weather data. Better weather station data enables our model to perform better in these regions.
- We believe we reduce bias by randomly taking fire and weather data indiscriminately across a range of geographies, setting a large bounding box around all of the fiery regions of California.
- We further limit class bias, for example, by running training across all regions and applying predictive models on all regions as well. This hopefully gathers and distributes the model’s gains from training.
Ethics of user experience.
- It is important to consider how the product may affect end-users. Our end-user is fire department staff and forest managers. We don’t foresee adverse effects for them.
Built With
- dark-sky
- google-cloud
- google-colab
- google-earth-engine
- javascript
- python
- tensorflow

Log in or sign up for Devpost to join the conversation.