-
-
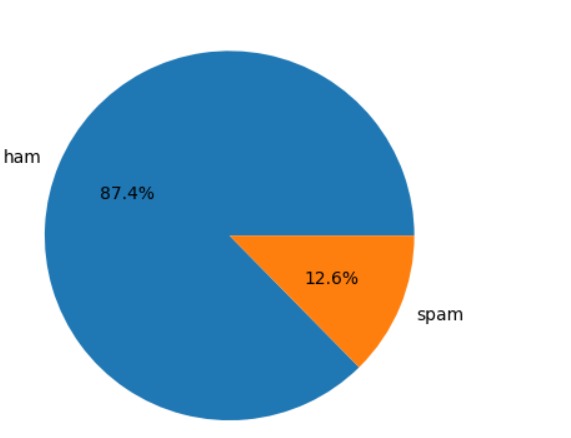
Data Visualization

About the Project
Inspiration
The increasing volume of spam messages inspired me to develop an AI-powered SMS Spam Detection system that accurately classifies ham (legitimate) and spam (unwanted) messages.
What I Did
I implemented Natural Language Processing (NLP) and Machine Learning (ML) techniques to build an efficient spam classifier. The key steps included:
- Data Preprocessing: Used NLTK, Regex, and feature engineering to clean and prepare the dataset.
- Exploratory Data Analysis (EDA) & Visualization: Analyzed data distribution and patterns.
- Feature Extraction: Applied Bag of Words (BoW) and TF-IDF for text representation.
Model Training & Evaluation:
- Gaussian Naïve Bayes with BoW achieved 88% accuracy.
- Gaussian Naïve Bayes with TF-IDF also achieved 88% accuracy.
- Random Forest with BoW achieved 97% accuracy.
- Random Forest with TF-IDF delivered the highest 98% accuracy.
- Gaussian Naïve Bayes with BoW achieved 88% accuracy.
Challenges Faced
- Selecting the best feature extraction technique for optimal classification.
- Handling imbalanced data to improve model performance.
- Fine-tuning ML models for better spam detection accuracy.
Conclusion
This project successfully demonstrates the effectiveness of ML and NLP in spam detection. Random Forest with TF-IDF provided the best results with 98% accuracy, while Random Forest with BoW achieved 97%, and Gaussian Naïve Bayes performed consistently with 88% accuracy for both BoW and TF-IDF. This highlights the impact of feature extraction and model selection in text classification.
Built With
- jupyternotebook
- machine-learning
- matplotlib
- natural-language-processing
- nltk
- numpy
- pandas
- python
- regex
- scikit-learn
- seaborn



Log in or sign up for Devpost to join the conversation.