-
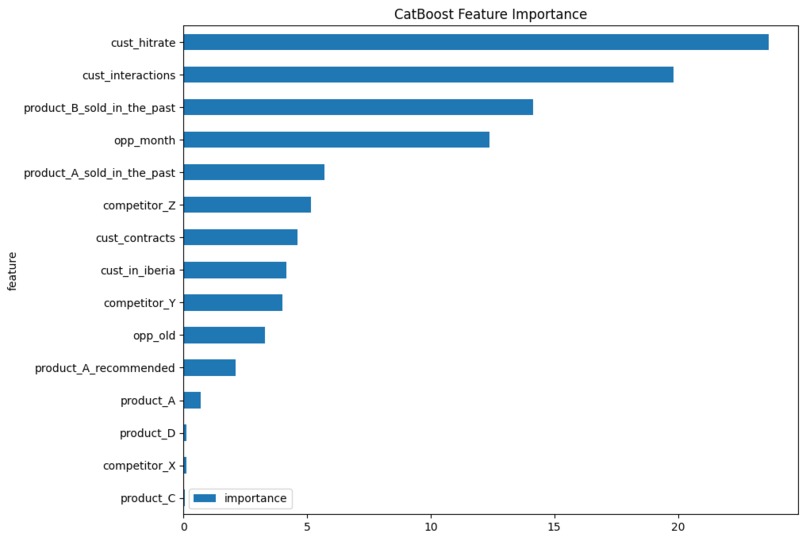
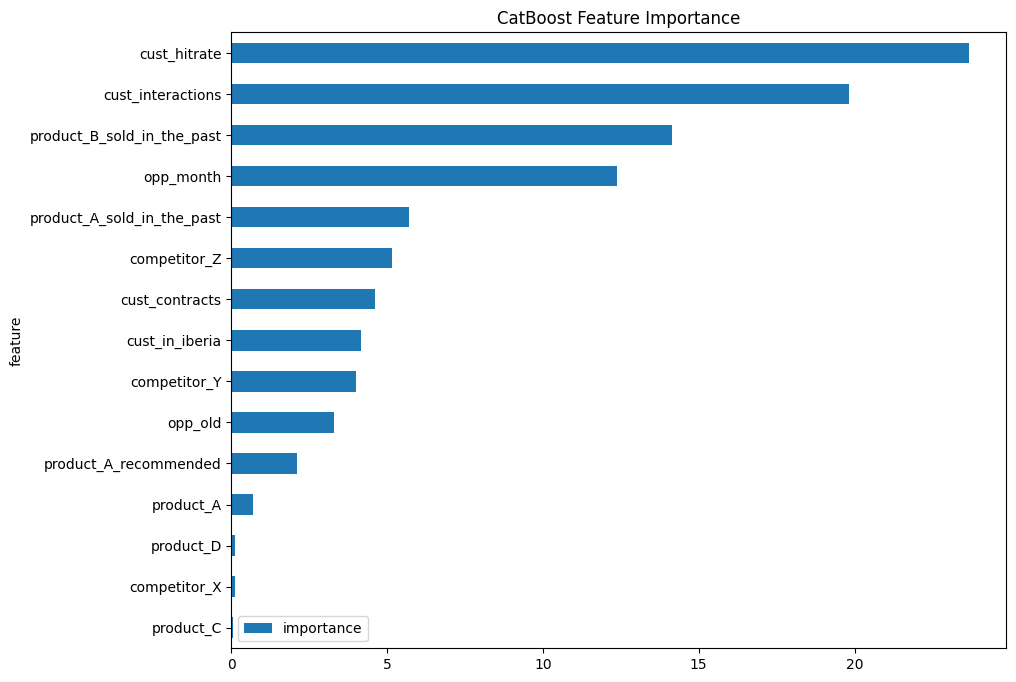
Feature importance of the CatBoost model calculated with built-in utilities.
-
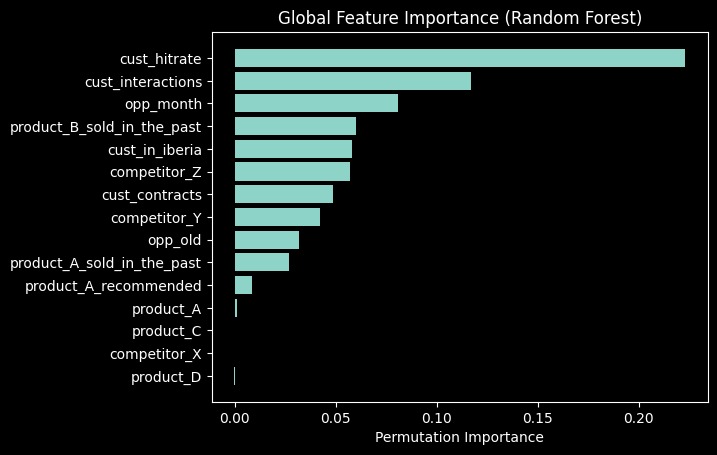
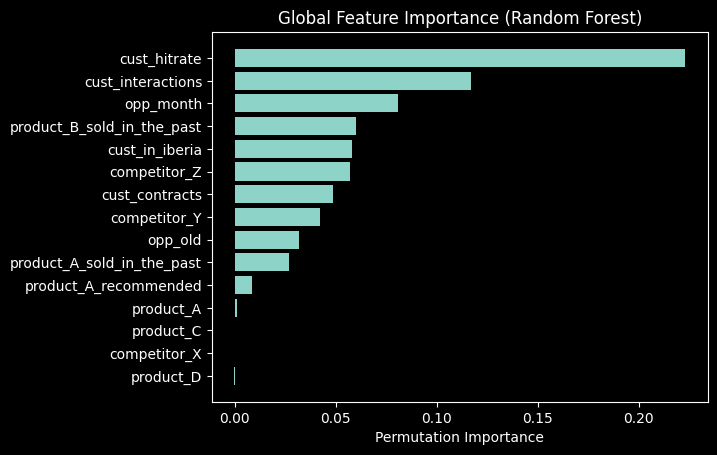
Feature importance of the Random Forest model calculated with permutation importance.
-
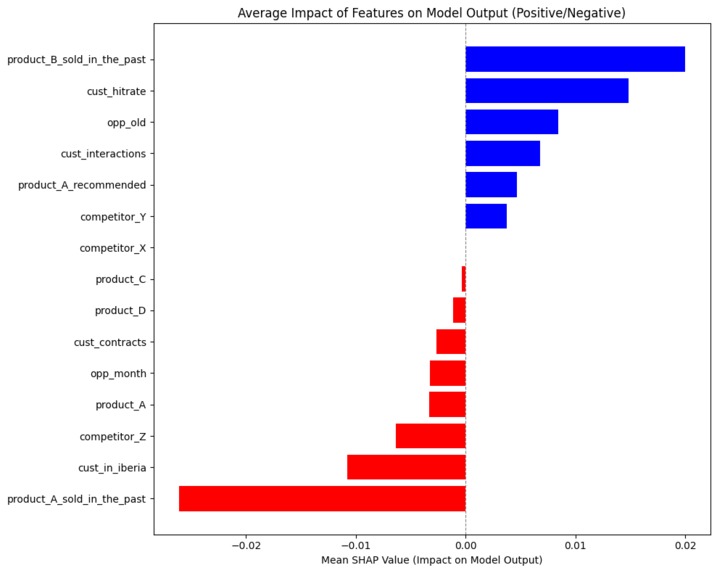
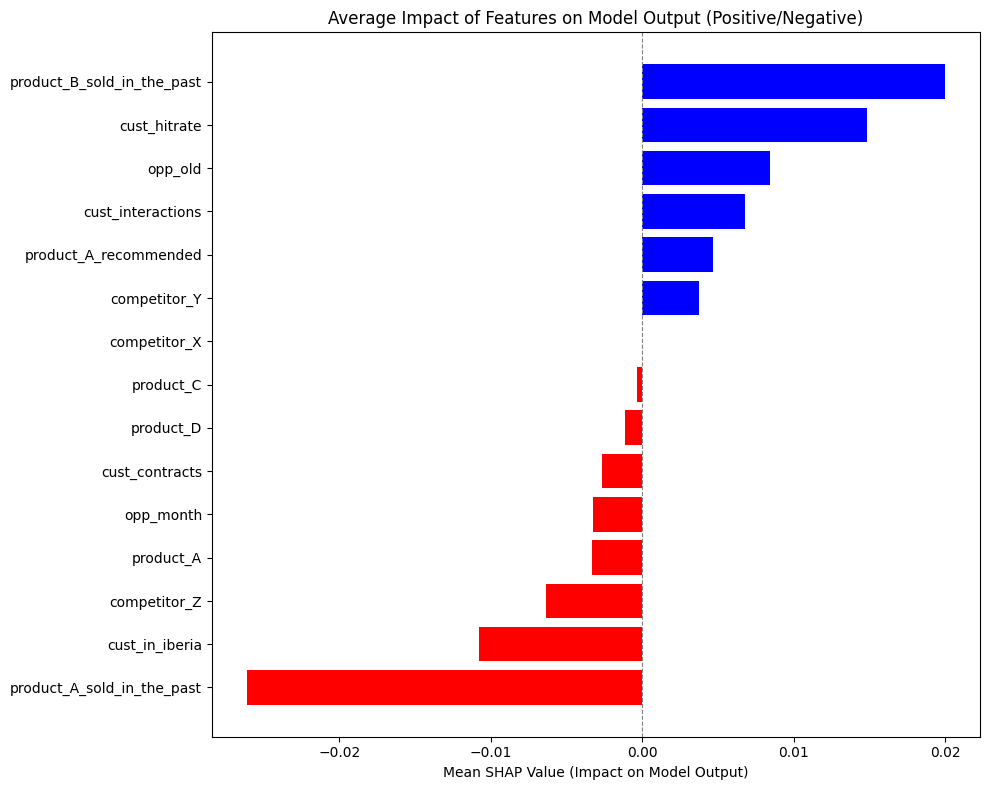
Average impact of features plot of the CatBoost model calculated with SHAP.
-
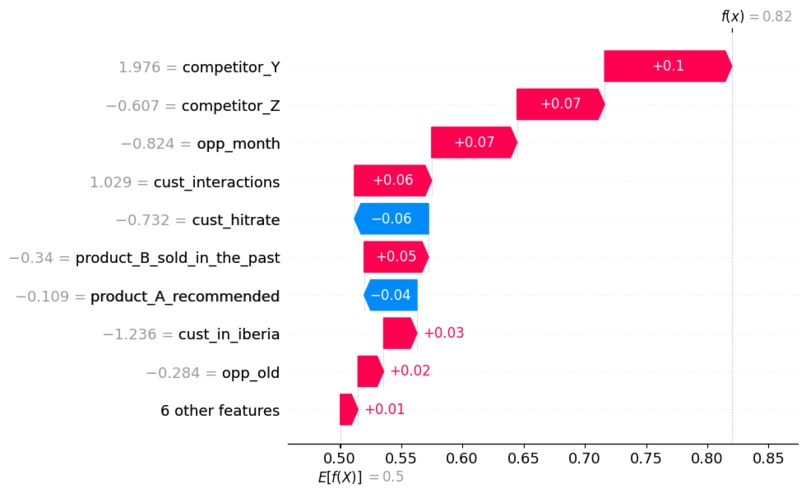
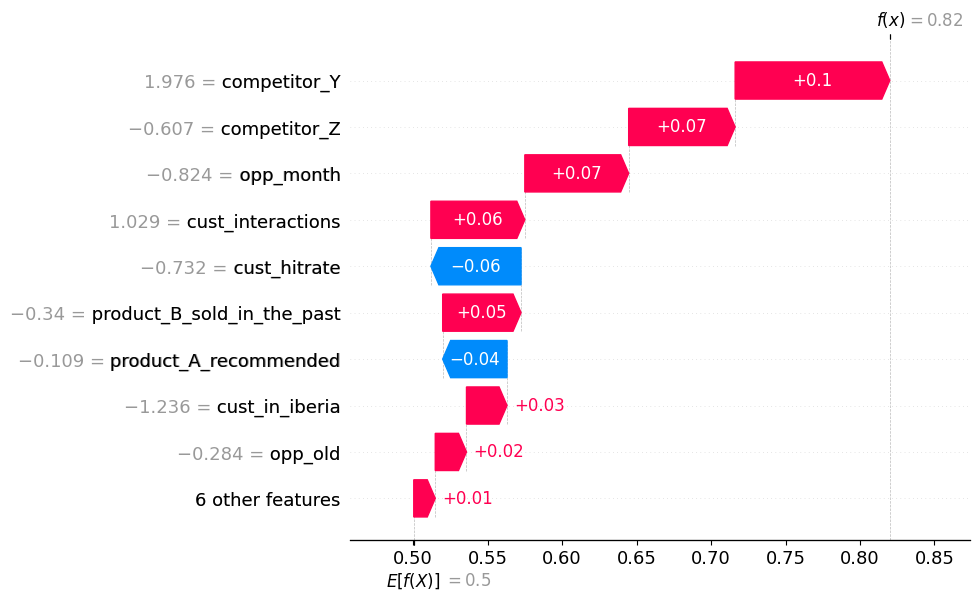
Waterfall plot of a single case using the Random Forest model, LIME and SHAP.
Inspiration
Given current development of business analytics, the weight of quantitatively justifed business decisions becomes increasingly valuable. As students deeply engaged with the active industry, we view this as an opportunity to put our technical abilities to the test in the real world.
What it does
The goal is to build a binary classifier that predicts whether a sales opportunity will be won (1) or lost (0) and, more importantly, to explain why the model makes each prediction. Not only does this help the company build its market strategy, it also empowers its business analysts to better understand the influence of several factors into the results of deals and sales.
How we built it
We strive to get the best: that's why we built 5 different models and compared their results and performance: StatsModels, XGBoost, LightGBM, Random Forest and CatBoost. Our CatBoost and Random Forest models, which were among the highest scoring models (up to 0.83 F1 score), gave very similar results and allowed us to make reasonable and confident conclusions.
Challenges we ran into
Our LightGBM model did not end up working, but that wasn't a considerable problem since the rest of the models worked correctly. Also, we weren't able to get an average impact plot for our Random Forest model because the library we used seemed to hang up; but we do have one for CatBoost, which performs similarly, and the rest of the plots (waterfall and feature importants) did see the light.
Accomplishments that we're proud of
Using our CatBoost and Random Forest models, we successfully found that the customer success rate in previous interactions and the number of those past interactions are the most important factors in winning or losing a deal. We also see that the amount of product to be sold doesn't contribute as much to the model's performance.
Together with our high-performing models, we've achieved the initial double goal: reasonably predict sales and explain those predictions.
What we learned and what's next
This has been our first hackathon and we're quite happy with both the results and our learning journey: during this weekend we investigated in depth how these machine learning models work and how we must interpret their results, exercising our critical thinking abilities as well. We can't wait for our next adventure!
Built With
- catboost
- python
- sklearn

Log in or sign up for Devpost to join the conversation.