-
-
AGENT PAGE
-
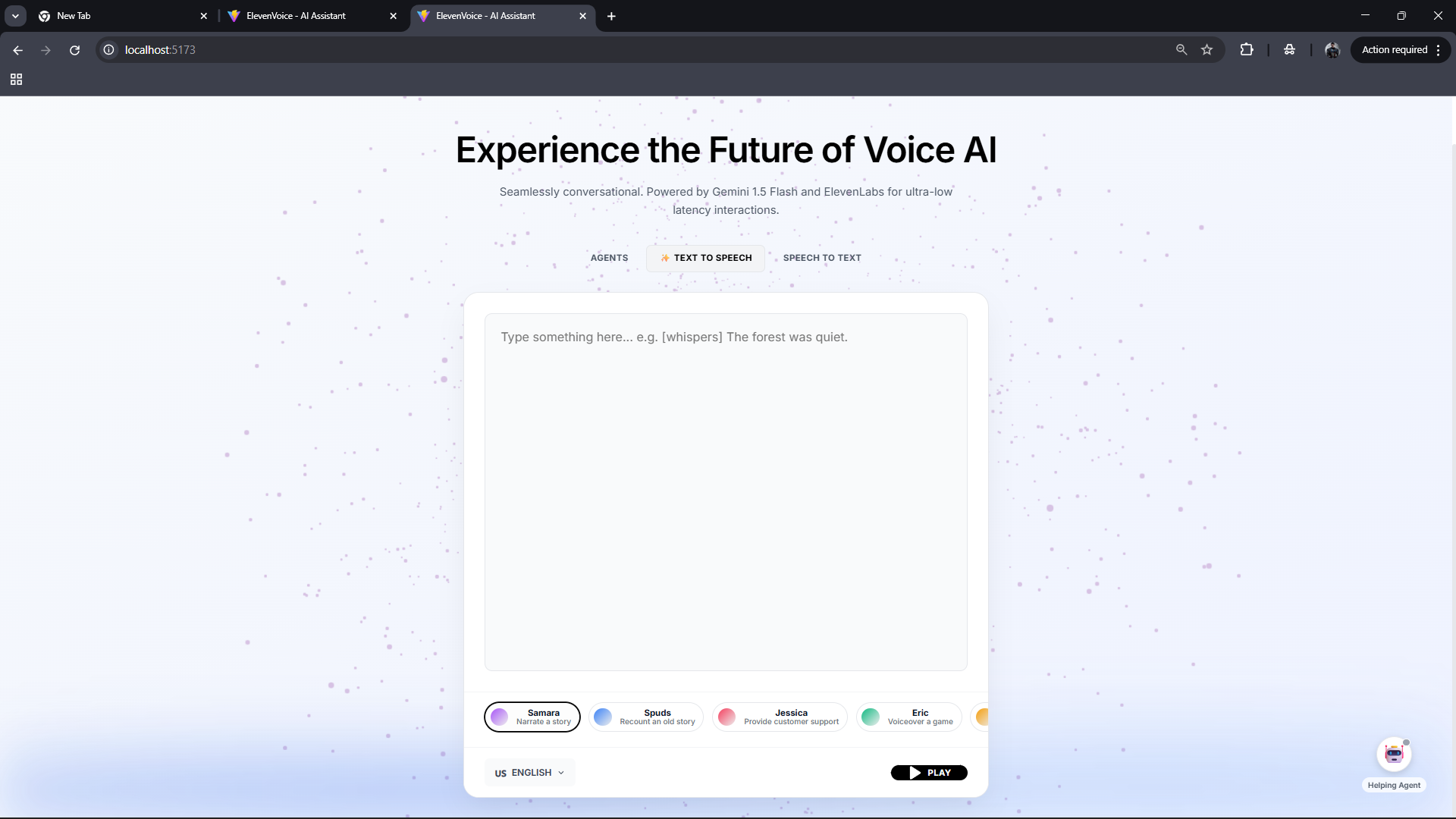
TEXT TO SPEECH CONVERTOR
-
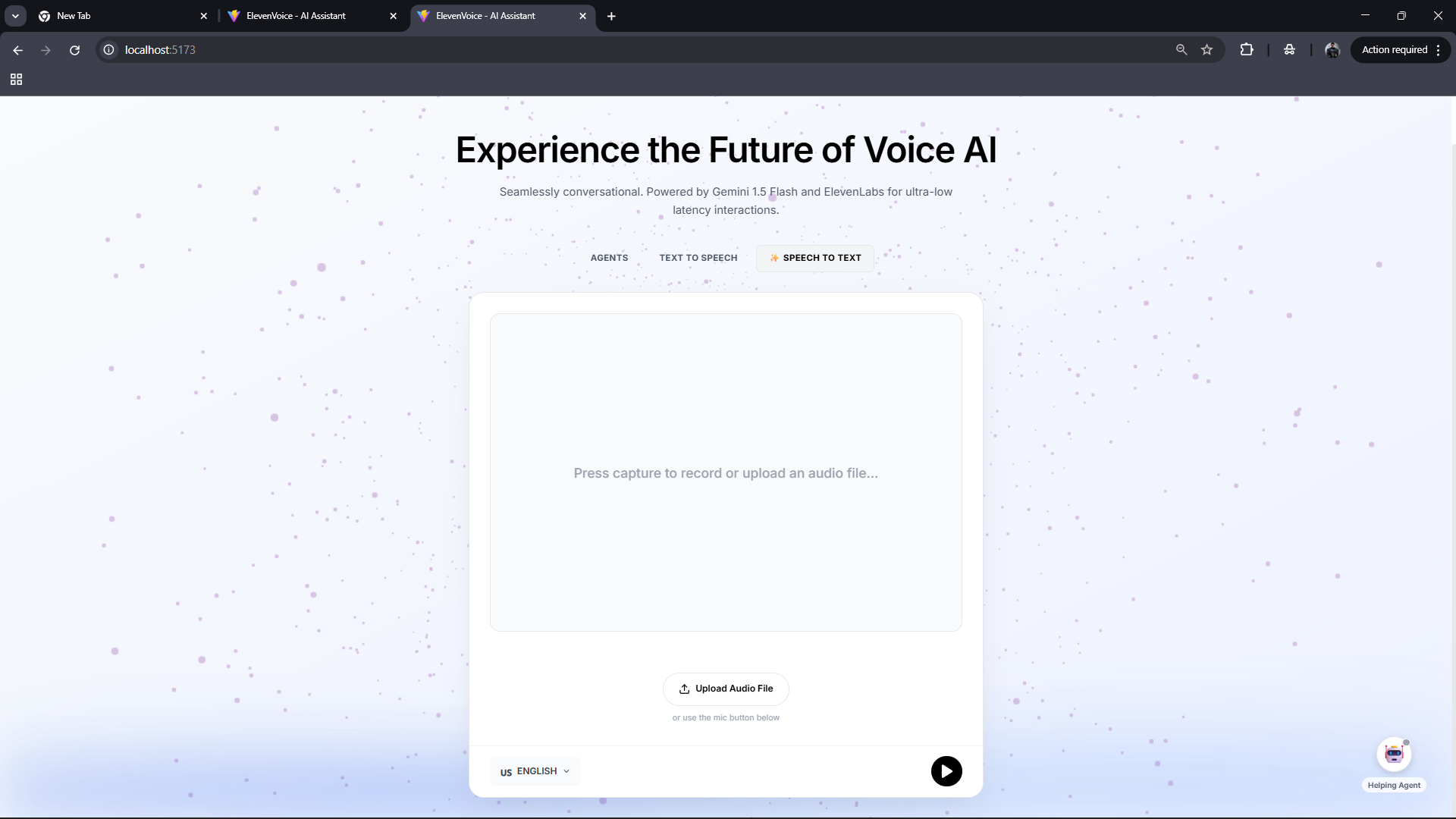
SPEECH TO TEXT CONVERTOR
Inspiration
Voice is the most natural way humans communicate, yet most AI systems still depend heavily on typing, buttons, and screens. We wanted to explore what a truly conversational AI experience could feel like—one that listens, responds quickly, and sounds natural instead of robotic. The idea was to reduce friction between humans and machines and make interaction feel more like a real conversation.
What it does
This project is a real-time Voice AI assistant that supports speech-to-text, text-to-speech, and conversational agent interactions. Users can speak naturally, upload audio, or type text, and receive fast, human-like voice responses. The system is designed for low latency and smooth interaction, making it suitable for use cases like virtual assistants, narration, customer support, and interactive voice experiences.
How we built it
The frontend is built using modern web technologies with a clean and minimal UI focused on usability. Audio input is captured directly from the browser and processed in real time.
We integrated Gemini 1.5 Flash for fast and accurate language understanding and response generation, and ElevenLabs for high-quality, natural-sounding voice synthesis. The system coordinates speech input, AI reasoning, and voice output to create a seamless conversational flow.
Challenges we ran into
One of the main challenges was managing latency between speech input, AI processing, and voice output. Even small delays can break the conversational feel. We also faced challenges in handling different interaction modes (speech-to-text, text-to-speech, and agents) while keeping the UI simple and intuitive. Fine-tuning prompts and synchronizing audio playback were key problem areas we worked through.
Accomplishments that we're proud of
We successfully built a fully functional Voice AI system with real-time interaction and natural voice output. The project demonstrates smooth switching between modes, clean UI design, and reliable integration of powerful AI APIs. Achieving low-latency conversational flow was a major milestone.
What we learned
This project taught us that voice-based user experience is fundamentally different from text-based systems. Latency, clarity, and conversational pacing matter more than raw feature count. We also gained hands-on experience integrating large language models with voice synthesis and learned how prompt design directly impacts the quality of spoken responses.
What's next for the project
In the future, we plan to add more voice options, multilingual support, and personalized conversational memory. We also aim to deploy the system at scale and explore real-world applications in education, accessibility, and customer service.
Built With
- css
- elevenlabs-api
- gemini-1.5-flash-api
- html
- javascript
- react
- web-audio-api


Log in or sign up for Devpost to join the conversation.