-
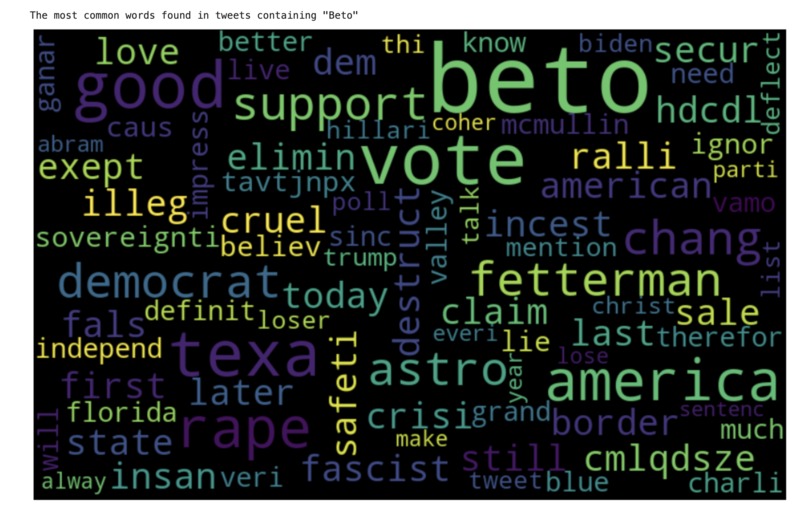
Beto analysis of most frequently used words
-

Preprocessing Function
-

Twitter API Configuration



Table 3
Inspiration
I was inspired by the upcoming election and how close the two candidates are. This is a very important election for Texas and I wanted to see if there were frequent changes in the public's opinions.
What it does
This code extracts recent tweets from twitter containing the words "abbott" and "beto" and aims to sentiment analyze to determine the public's current opinion of the two. The machine learning is still in process (and is almost completed), but it does display the most common words in the tweets of those two categories.
How I built it
I built it in python using the typical steps for machine learning.
Challenges I ran into
The biggest challenge was not having access to a Twitter Elevated Development account since those take 48hrs-2 weeks to process. This meant that I was unable to pull tweets more than 7 days back or sort by geographical area. My original idea was to analyze every day of tweets annd look at how certain important dates (like speeches, debates, etc.) change the public's opinions of the candidates. Another issue I had with the Twitter API was the very confusing documentation and limited amount of tutorials for unelevated access. An issue I had unrelated to the Twitter API was that with my machine learning feature extraction. For some reason, the bag of words function I originally created makes the dimension of the dataframe super inaccurate which prevented my extracted twitter dataset from being analyzed. This error took about 3 hours to fix and wasn't fixed until right at the deadline. Which means I was able to fix the function, but unable to calculate the total number of positive tweets and compare against the negative tweets. 10 more minutes and my project would have been finished!
Accomplishments that I'm proud of
I am proud that it is my first time to successfully submit something at a hackathon! Nevertheless, alone while doing it. It was my first time using an API/pulling any information from the web, and I thought it was a great accomplishment. Furthermore, I am proud that I was able to get the machine to learn itself. I could have taken the easy option and used a pre-trained model and would have for sure finished my project, but I felt I could learn more by training the model myself-- and I did.
What I learned
I learned many things like sklearn, nltk (I had previously only used BERT), how to use an API, Twitter development account statuses, and most importantly that I can do anything I put my mind to!
What's next for Election Sentiment Analysis Project
Going forwards, I would finish calculating the total number of positive tweets and negative tweets for both "beto" and "abbot and would create a graph to represent that. Then, I would (hopefully) receive my Twitter API elevated access and be able to calculate per day. I would also continue fine-tuning the model to increase its f1, precision, recall, and accuracy as they are all hovering around 70% which is not optimal. 95%+ is desired.


Log in or sign up for Devpost to join the conversation.