-
-

Introduction
-
Architecture

Inspiration
My grandmother forgets her pills. Not because she doesn't care, but because managing five different medications with different schedules is genuinely hard when you're 82. She has a smartphone but barely uses it. The pill organizer helps, but she still misses afternoon doses because nobody is there to remind her.
I'd previously built LinguaLive, a language tutor that pairs real time AI model with a Reachy Mini robot for real-time voice conversations. That project taught me something important: voice is the most natural interface, especially for people who struggle with screens. When I saw Amazon Nova Sonic launch on Bedrock with bidirectional streaming and function calling, I thought: what if I took the same architecture and pointed it at a problem that actually matters to my family?
That's how ElderConnect started. Same pattern (real-time voice + robot + tool calling), different AI provider, different purpose. Instead of teaching French, it reminds Margaret to take her blood pressure pill.
What it does
ElderConnect is a voice care companion. The elder speaks naturally, and the system responds in real time with a warm, patient voice. Under the hood, it does a lot more than chat:
Medication management is the core feature. The system knows the full medication schedule (stored in DynamoDB), can tell you if you took your morning pills, remind you about upcoming doses, and log when you've taken something. All through voice. "Did I take my blue pill today?" gets a real answer, not a generic response.
Caregiver alerts let the system notify family members when something feels off. If the elder mentions dizziness, chest pain, or a fall, ElderConnect flags it and can send an alert to the designated caregiver. The urgency level determines whether it's an FYI or a potential emergency.
Cross-session memory using Mem0 means ElderConnect remembers things between conversations. If Margaret mentioned last week that her new medication makes her nauseous, it remembers that context the next time she calls. This makes the interaction feel less like talking to a machine and more like talking to someone who knows you.
Family dashboard is a FastAPI web interface where caregivers can see today's medication adherence, upcoming appointments, and any health concerns the system flagged during conversations. Peace of mind for family members who can't be there every day.
Robot embodiment on Reachy Mini adds a physical presence. The robot nods when listening, looks concerned when you mention pain, and gives a gentle wave when saying goodbye. The gestures are deliberately slow and soft, designed for comfort rather than entertainment.
How we built it
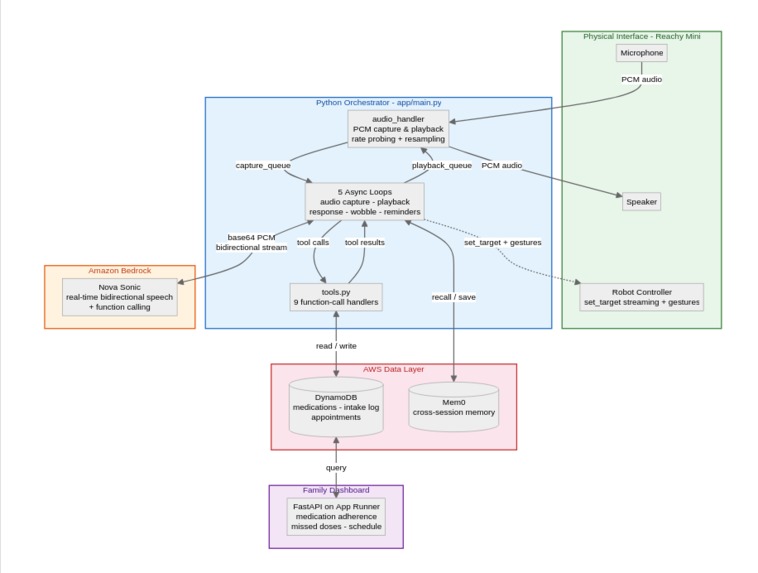
The architecture follows four concurrent async loops, same pattern I used in LinguaLive:
- Audio capture loop grabs PCM audio from the microphone and streams it to Nova Sonic as base64-encoded chunks over an HTTP/2 bidirectional stream
- Audio playback loop takes Nova's audio responses and plays them through the speaker, with automatic sample rate conversion (Nova outputs 24kHz, but many devices like Reachy Mini don't support that natively)
- Response loop processes all events from Nova: audio chunks go to playback, tool calls get dispatched to handlers, transcripts get logged and checked for health concerns
- Wobble loop synchronizes the robot's head movement with speech output at 25Hz for natural-looking animation
The Nova Sonic integration uses aws_sdk_bedrock_runtime, not boto3. This is an experimental smithy-based Python SDK that supports the bidirectional streaming protocol Nova requires. The session protocol is event-based JSON: you send a sequence of session/prompt/content events to set up the conversation, then stream audio in and receive audio, text, and tool calls back.
We defined 9 function-calling tools that Nova can invoke mid-conversation: check medication status, log intake, get today's schedule, find missed medications, check upcoming reminders, get appointments, contact a caregiver, set a reminder, and trigger robot emotions.
The infrastructure is fully automated with Terraform (DynamoDB tables, IAM roles, ECR, App Runner) and a 6-stage GitLab CI/CD pipeline that goes from lint and test through terraform plan/apply to container build and deployment. AWS authentication uses OIDC federation, no long-lived credentials.
Challenges we ran into
Nova Sonic's SDK is experimental. The documentation is sparse and the Python SDK (aws_sdk_bedrock_runtime) behaves differently from boto3 in subtle ways. The biggest gotcha was that inputSchema.json in tool definitions must be a JSON string, not a dict. We spent hours debugging silent tool call failures before figuring that out.
Audio sample rates caused headaches. Nova outputs 24kHz audio, but 24000 Hz is not a standard ALSA rate. Reachy Mini and many other devices reject it outright. We had to build a rate probing and resampling pipeline that detects supported hardware rates and converts on the fly using numpy interpolation. We borrowed this approach from LinguaLive where we'd already solved the same problem with Gemini.
Duplicate transcripts were confusing. Nova sends assistant text twice: once as a "speculative" early transcript while audio is still streaming, and again as the "final" version after audio completes. Without filtering, every response showed up twice in the logs and memory. We had to detect the generationStage field in contentStart events and skip the final duplicate.
Barge-in handling needed careful coordination. When the elder speaks over the assistant, Nova sends an interrupt signal. We need to immediately flush the audio playback queue so stale audio stops, but also not lose the new user input that triggered the interruption. Getting the timing right between the response loop, playback queue, and audio capture took several iterations.
Balancing safety with autonomy. The caregiver alert system needs to be sensitive enough to catch real concerns ("I feel dizzy") but not so trigger-happy that it calls family every time someone says "I have a headache from this crossword puzzle." We settled on keyword detection as a first pass with urgency levels, knowing that a production system would need something more nuanced.
Accomplishments that we're proud of
The voice interaction feels genuinely natural. There's no "press a button to talk" flow. You just speak, and it responds. The barge-in detection means you can interrupt mid-sentence and it adapts, just like a real conversation.
The medication tracking actually works end to end. You can say "did I take my morning pills?" and get back a specific answer based on real data, not a canned response. When you say "I just took the blue one," it logs it with a timestamp. The family dashboard shows the same data in real time.
We got the full CI/CD pipeline working with OIDC-based AWS authentication from GitLab. No hardcoded credentials anywhere. Terraform manages everything from DynamoDB tables to App Runner services.
The Reachy Mini integration adds something that's hard to quantify. Having a physical robot nod along while you talk and look concerned when you mention pain creates a sense of presence that a speaker or screen can't match. The slow, gentle gesture vocabulary was designed specifically for elderly users who might find fast robot movements startling.
Cross-session memory means ElderConnect gets better over time. It remembers preferences, past concerns, and medication reactions. That context enriches every future conversation.
What we learned
Voice-first design is fundamentally different from screen-first design. You can't show a list of medications in voice. You have to decide what information matters most and present it conversationally. "You have three pills left today, and the next one is your blood pressure medication at 2 PM" works. Listing all nine medications with dosages and times does not.
Working with experimental SDKs means a lot of trial and error. The official samples were the only reliable reference. When in doubt, we went back to the AWS sample code and worked outward from there.
Elderly users need a different kind of patience in the AI. The system prompt tuning was as important as the code. We needed the voice to be warm but not patronizing, helpful but not pushy, and willing to repeat things without sounding annoyed.
Building on a previous project (LinguaLive) was a massive accelerator. The audio pipeline, robot controller, head wobbler, and async orchestration pattern were all adapted rather than written from scratch. Having solved problems like ALSA rate conversion and barge-in handling before meant we could focus on the care companion features instead of infrastructure.
What's next for ElderConnect
Proactive check-ins. Right now ElderConnect waits for the elder to initiate conversation. We want it to reach out: "Good morning Margaret, it's time for your morning pills. How are you feeling today?"
Richer caregiver notifications. Moving from log-based alerts to real SMS/push notifications via SNS or Twilio, with a summary of flagged concerns and medication adherence for the day.
Appointment integration. Connecting to actual calendar systems instead of demo data, so ElderConnect can remind about upcoming doctor visits and help prepare questions.
Multi-elder support. Right now it's single-user. A care facility would need voice identification to distinguish between residents and maintain separate medication schedules and memory profiles.
Emotion detection from voice. Nova Sonic gives us the audio stream. We could analyze tone, speech rate, and pauses to detect when someone sounds distressed, confused, or unusually quiet, and adjust the response style or escalate to caregivers accordingly.
Offline resilience. If the internet goes down, ElderConnect should still be able to play cached medication reminders at scheduled times rather than going completely silent.
Built With
- amazon-web-services
- bedrock
- dynamodb
- gitlab
- mem0
- nova
- oidc
- pollenrobotics
- python
- reachy-mini
- relatime
- robotics
- sonic2
- terraform


Log in or sign up for Devpost to join the conversation.