-
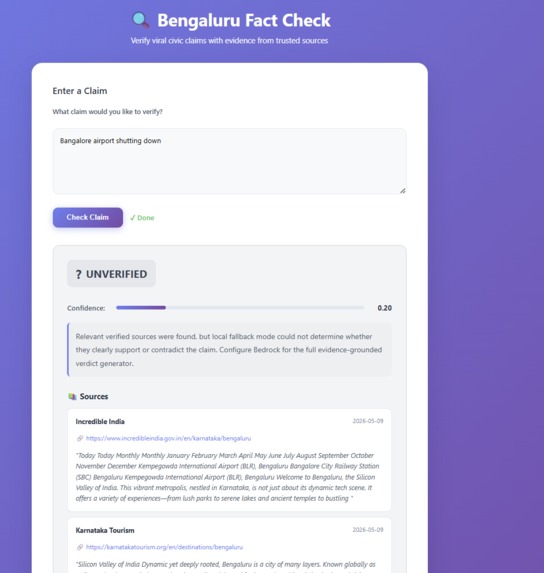
UI preview demo
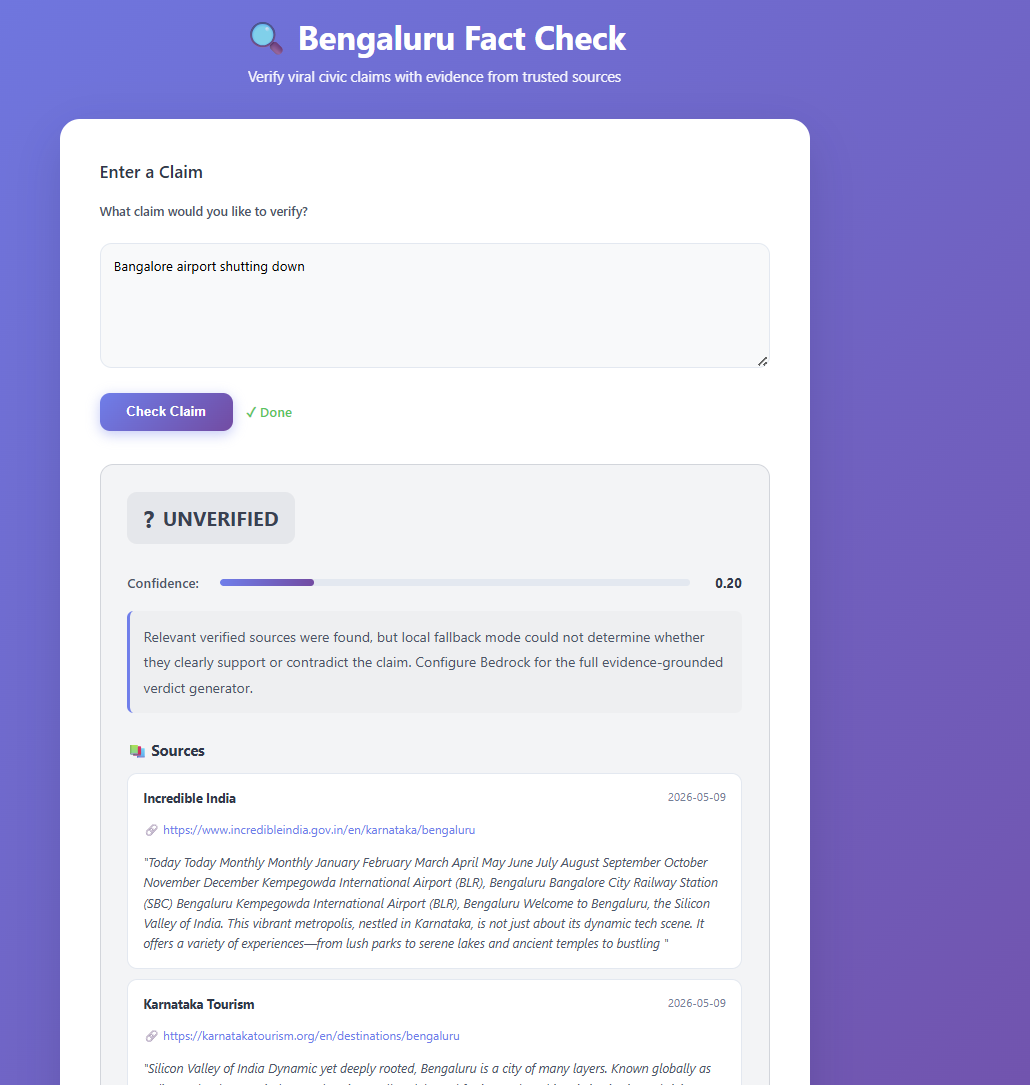
Inspiration
Misinformation spreads rapidly during city-level disruptions such as metro delays, water shortages, power outages, and government circulars. Most citizens rely on forwarded messages or fragmented social media posts without verification. We wanted to build a system that automatically checks claims against trusted Bengaluru public-service sources such as BMRCL, BBMP, BWSSB, and BESCOM.
Our goal was to create a lightweight AI-powered fact verification layer that combines real-time crawling, semantic search, and LLM reasoning into a single workflow.
What it does
ELASTSEARCH is an AI-powered misinformation verification platform focused on Bengaluru civic information.
The system:
- Crawls trusted government and utility websites
- Indexes documents into Elasticsearch Cloud
- Performs hybrid retrieval using BM25 + semantic ranking
- Uses AWS Bedrock LLMs to analyze evidence
- Returns a fact-check verdict with supporting sources
- Provides both CLI and web interfaces
Users can enter claims such as:
“BMRCL is shutting Purple Line tomorrow”
and receive evidence-backed responses generated from live indexed data.
How we built it
We built the project using:
Backend
- Python
- FastAPI
- Uvicorn
Search & Retrieval
- Elasticsearch Cloud
- Hybrid retrieval pipeline
- BM25 search
- Semantic reranking
AI Layer
- AWS Bedrock
- Claude models via Bedrock inference
Data Ingestion
- Custom crawler using BeautifulSoup and Requests
- Retry handling
- SSL fallback logic
- Structured document extraction
Infrastructure
- Docker
- GitHub
- VS Code + WSL
The crawler continuously gathers public information from official Bengaluru civic websites and stores normalized documents in Elasticsearch. The FastAPI server retrieves the most relevant evidence and sends it to the LLM for reasoning and verdict generation.
Challenges we ran into
We encountered several real-world infrastructure and data engineering problems:
- SSL certificate failures on government websites
- HTTP 500 errors from BBMP sources
- Timeouts from BESCOM pages
- Bedrock permission and IAM configuration issues
- Legacy model deprecations in AWS Bedrock
- Elasticsearch hybrid retrieval failures
- Environment configuration issues in WSL
- Dependency conflicts caused by externally managed Python environments
We also had to debug crawler reliability and retrieval ranking mismatches while ensuring the application stayed usable for non-technical users.
Accomplishments that we're proud of
- Successfully integrated Elasticsearch Cloud with live crawling
- Built a functioning AI fact-checking pipeline end-to-end
- Deployed a working FastAPI web interface
- Integrated AWS Bedrock with live inference
- Created a resilient crawler capable of handling broken public websites
- Implemented semantic retrieval over civic datasets
- Built the system from scratch while learning several cloud technologies during development
What we learned
Through this project we learned:
- Elasticsearch indexing and hybrid retrieval pipelines
- Semantic search architecture
- AWS IAM and Bedrock permissions management
- FastAPI deployment workflows
- Web crawling and document normalization
- Error handling for unreliable public infrastructure
- Building AI systems that combine retrieval with reasoning
We also gained practical experience working with cloud APIs, Docker, GitHub workflows, and production-style backend architecture.
What's next for ELASTSEARCH
We plan to extend the platform with:
- Real-time continuous crawling
- Multi-language support for Kannada and English
- Social media claim ingestion
- Mobile app deployment
- Credibility scoring
- Source trust ranking
- Public dashboards and analytics
- Push alerts for misinformation spikes
- Broader coverage beyond Bengaluru civic infrastructure
In the future, ELASTSEARCH could evolve into a city-scale public verification infrastructure for combating misinformation in real time.

Log in or sign up for Devpost to join the conversation.