-
-
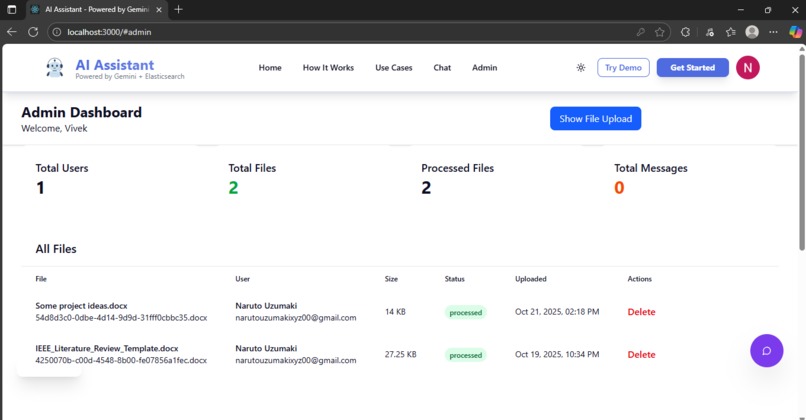
Admin Panel
-
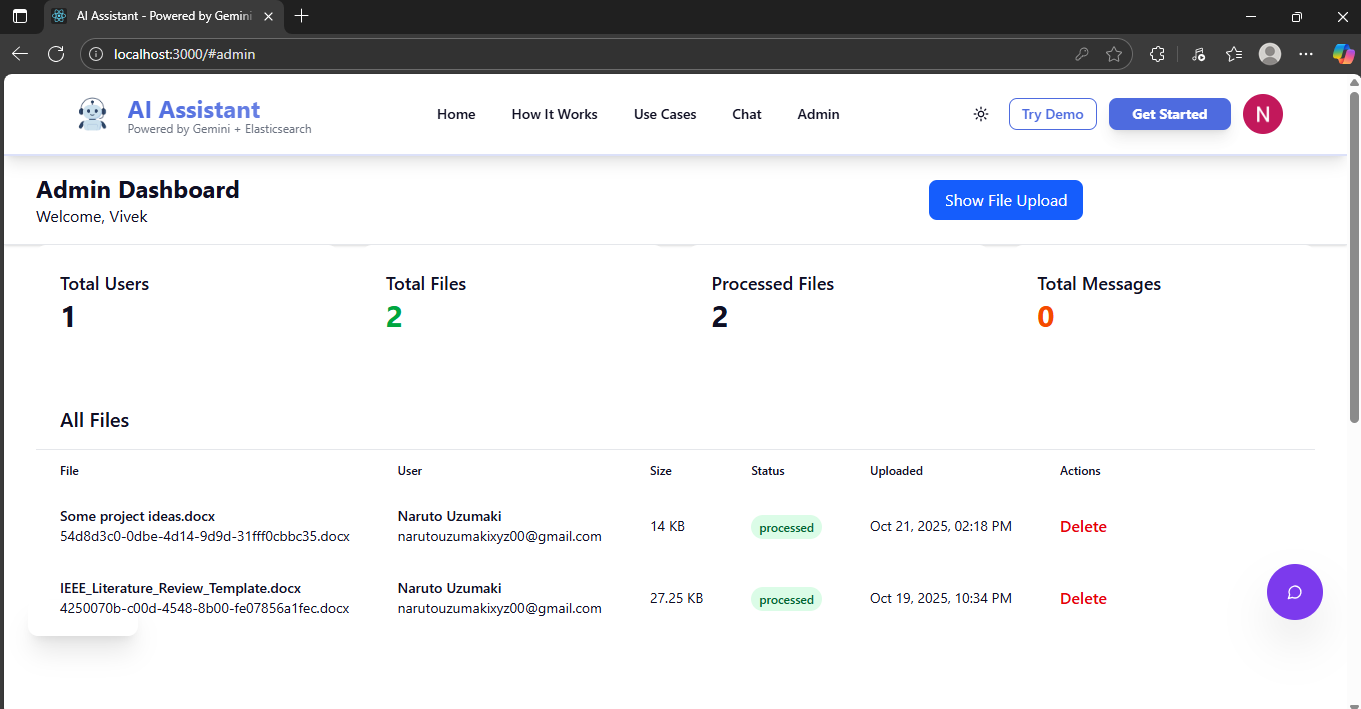
Dashboard
-
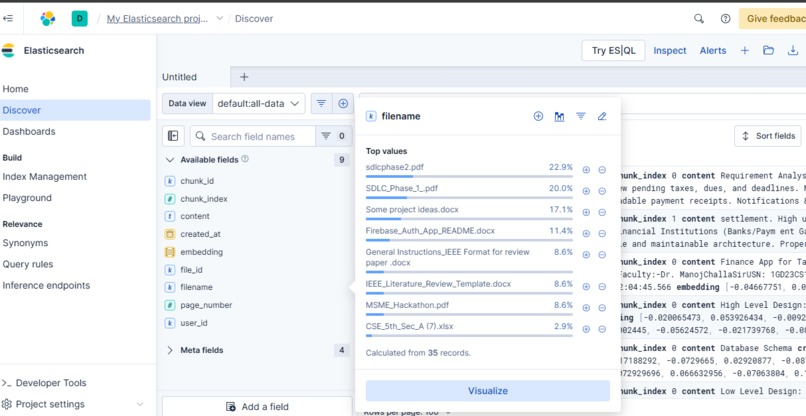
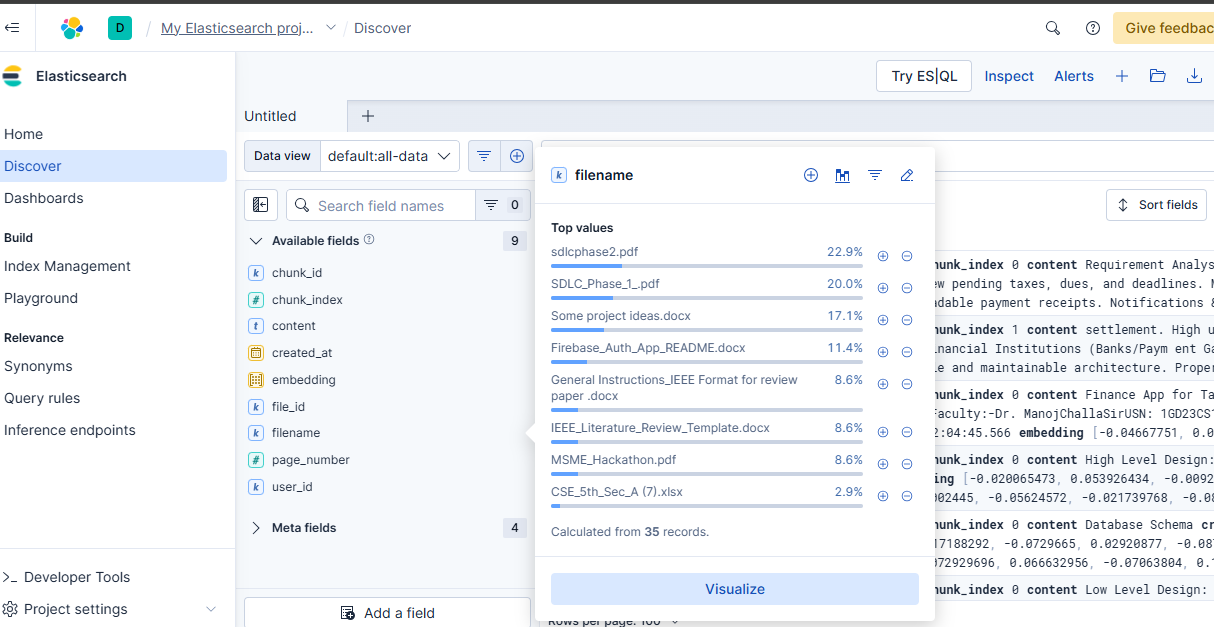
ElasticSearch
-
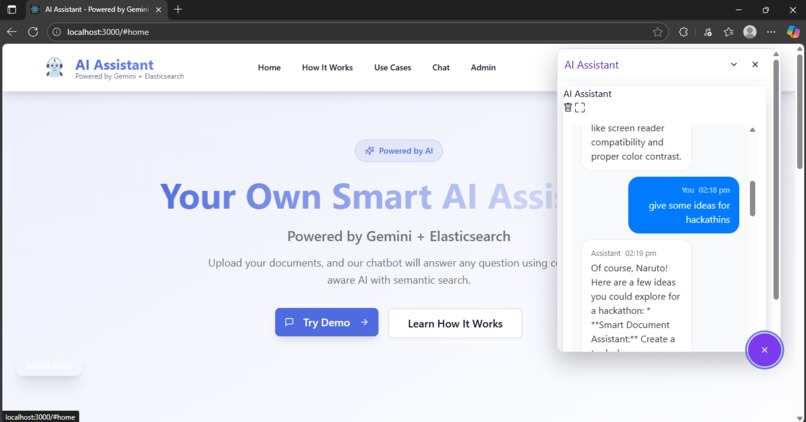
RAG-Chatbot
-
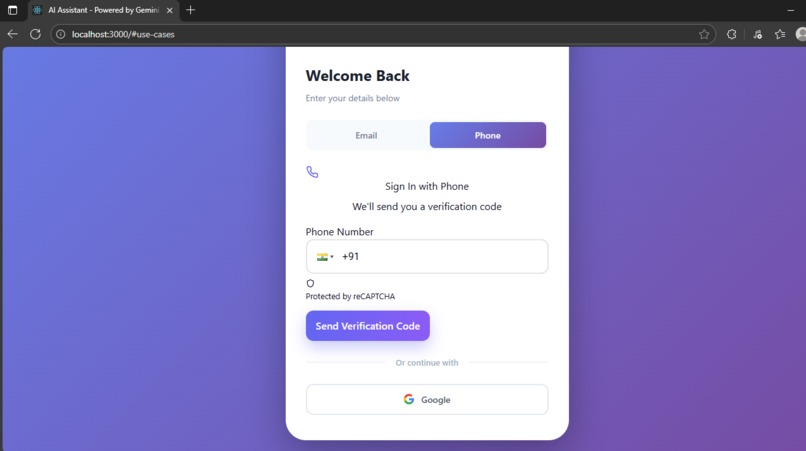
Auth-Firebase
Inspiration
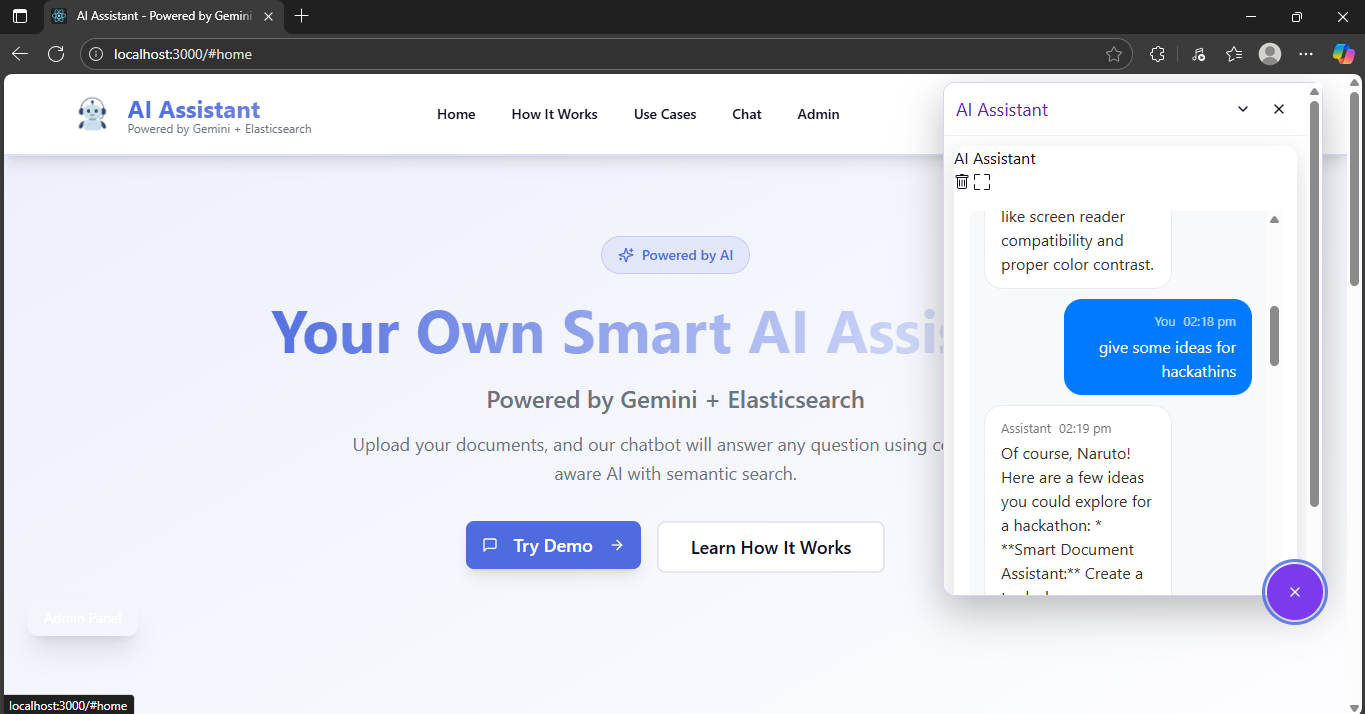
We wanted to build an intelligent assistant that combines Retrieval-Augmented Generation (RAG) with the Model Context Protocol (MCP) - creating a chatbot that doesn't just answer questions, but actually understands your documents through a modular, standardized architecture.
What it does
- Upload PDFs, Word docs, Excel files, and images
- Ask questions about your documents in natural language
- Get AI-generated answers with relevant context from your files using RAG
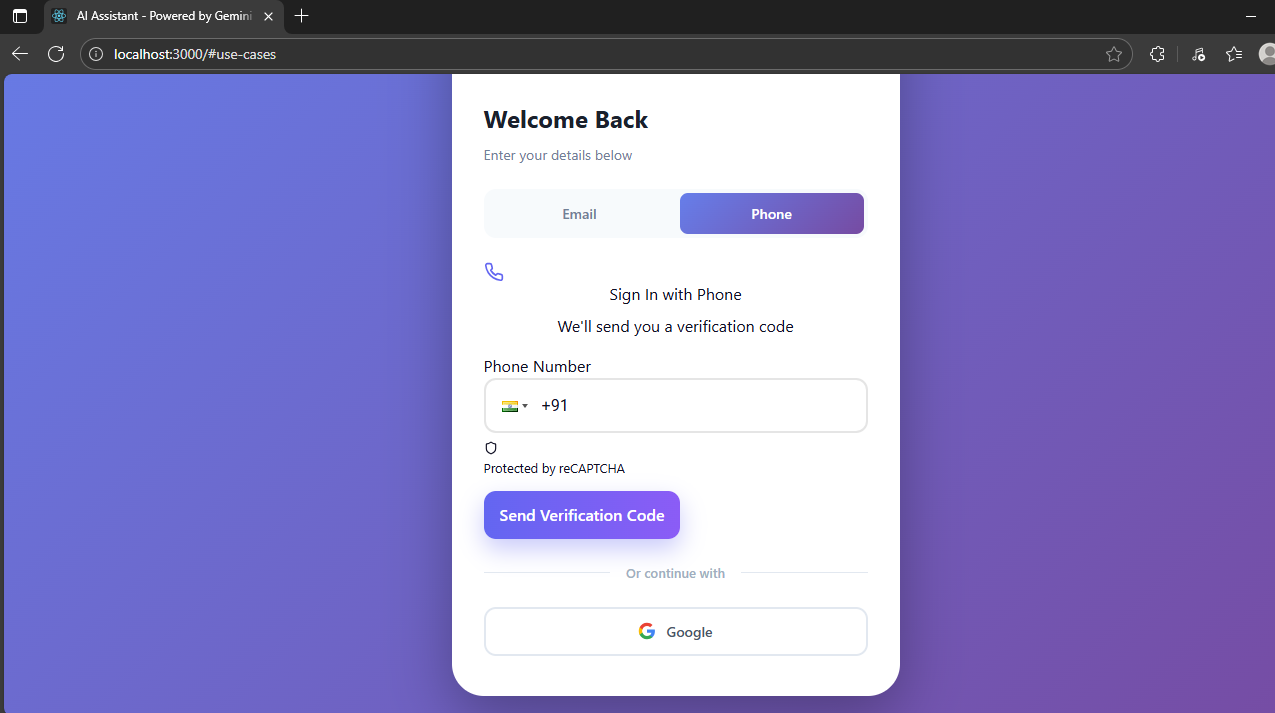
- Supports multi-user authentication (email, Google, phone)
- Real-time chat with conversation history
- MCP Server manages all document intelligence and AI operations
How we built it
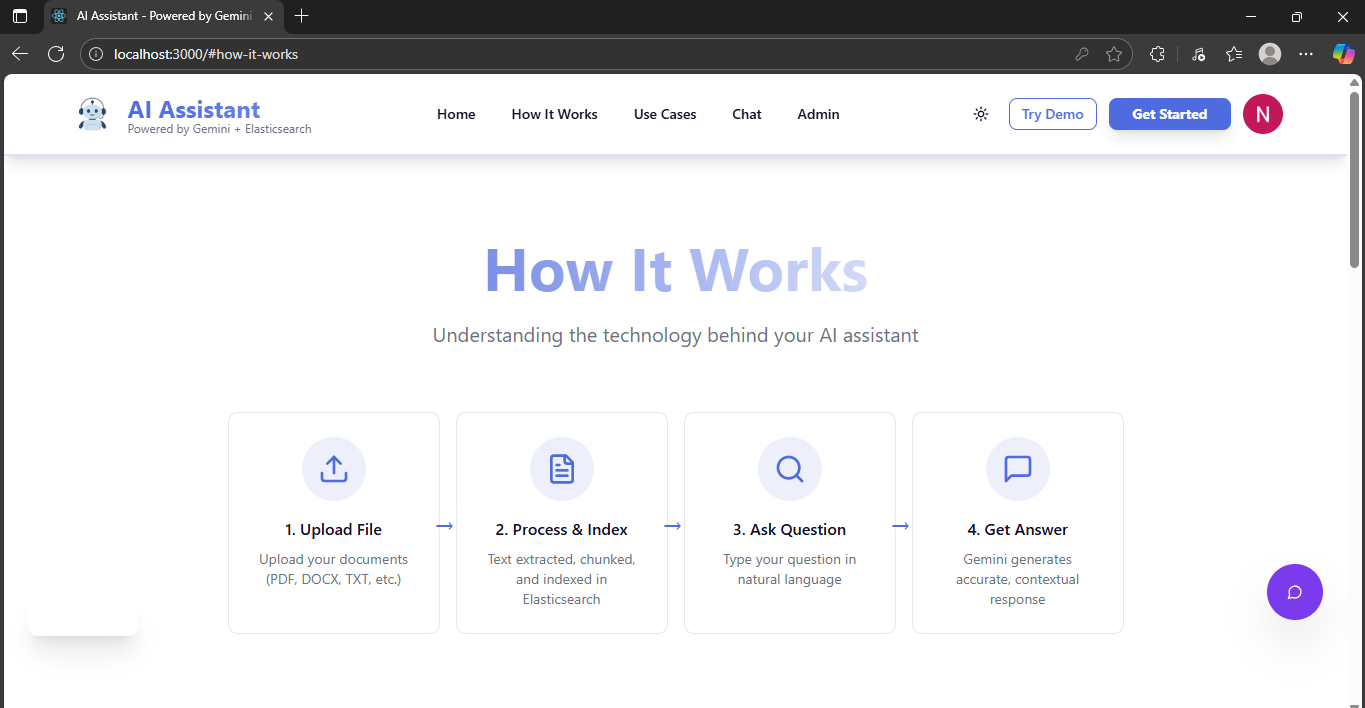
We implemented a 3-tier RAG architecture with MCP Server:
- Frontend (React): User interface for chat and document uploads
- Backend (Node.js): Handles authentication and routes requests
- MCP Server (Python): The RAG engine
- Processes documents and extracts text
- Generates embeddings using Sentence Transformers
- Stores vectors in Elasticsearch for semantic search
- RAG Pipeline: Retrieves relevant document chunks and augments Gemini AI prompts
- Returns intelligent, source-backed answers
- Processes documents and extracts text
The MCP Server follows the Model Context Protocol, making our RAG system reusable and allowing other applications to connect to the same AI capabilities through a standardized API.
Challenges we ran into
- Deployment headaches: Python 3.13 compatibility issues with PyTorch and scipy required downgrading to Python 3.11
- Dependency conflicts: Resolving version mismatches between transformers, sentence-transformers, and huggingface-hub
- Cross-service communication: Getting frontend, backend, and MCP server to work together across different domains
- Large ML models: Optimizing PyTorch and embedding models for production (800MB+ dependencies)
- CORS configuration: Managing authentication and requests across multiple deployed services
Accomplishments that we're proud of
- Successfully built a production-ready RAG system with MCP integration
- Enabled multi-user authentication with secure, real-time chat
- Deployed complex ML pipelines across multiple platforms
- Optimized embedding models for performance and scalability
What we learned
- How to implement RAG (Retrieval-Augmented Generation) from scratch
- Building production-ready MCP Server architecture
- Managing complex multi-service deployments (Render + Vercel)
- Handling large ML models in serverless environments
- Firebase authentication integration with microservices
What's next for ElasticMind AI — Context-Aware MCP - RAG Chatbot
- Add support for more document types (PowerPoint, CSV)
- Implement streaming responses for faster user experience
- Add document summarization and key insights extraction
- Multi-language support for international documents
Built With
- elasticsearch
- express.js
- fastapi
- firebase
- gemini-api
- google-cloud
- model-context-protocol
- node.js
- postgresql
- python
- pytorch
- react
- render
- sentence-transformers
- supabase
- tailwindcss
- typescript
- vercel
- vite
Log in or sign up for Devpost to join the conversation.