-
-

V-GNOME: Mapping the 3D Evolution of the Genomic Galaxy
-
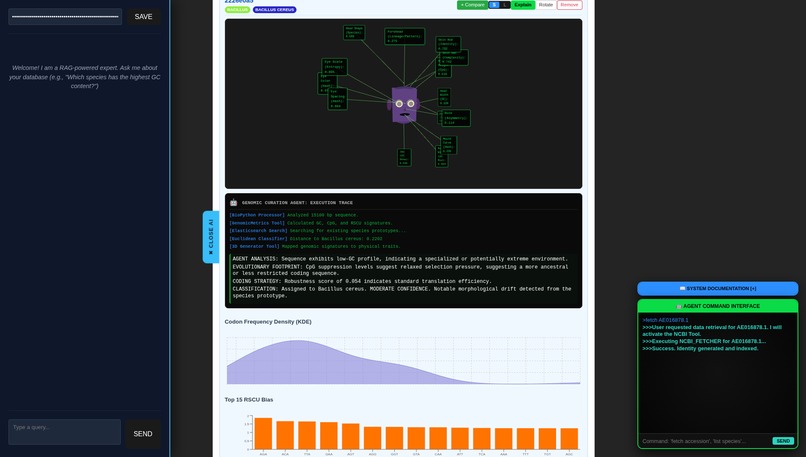
Fetching a Vivid 3D Genome
-
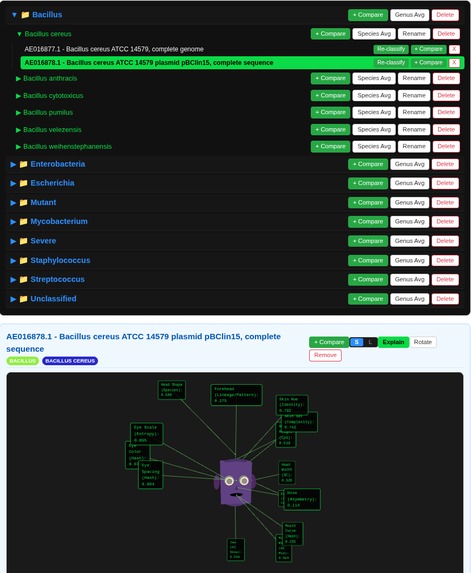
3D Genome in its World
-
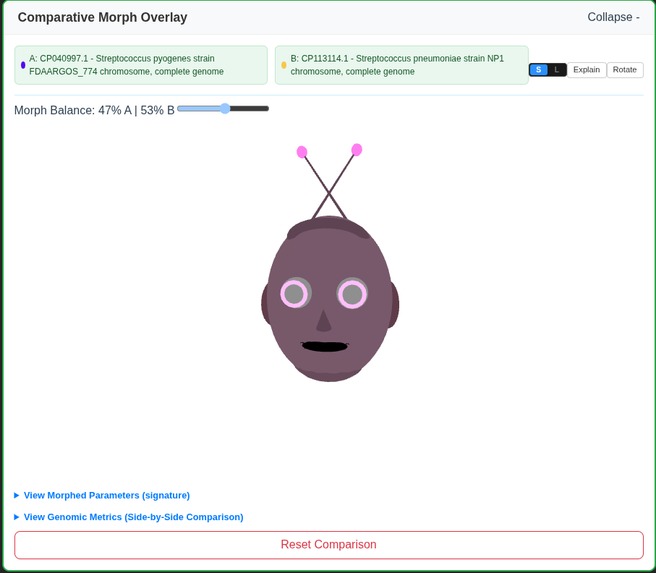
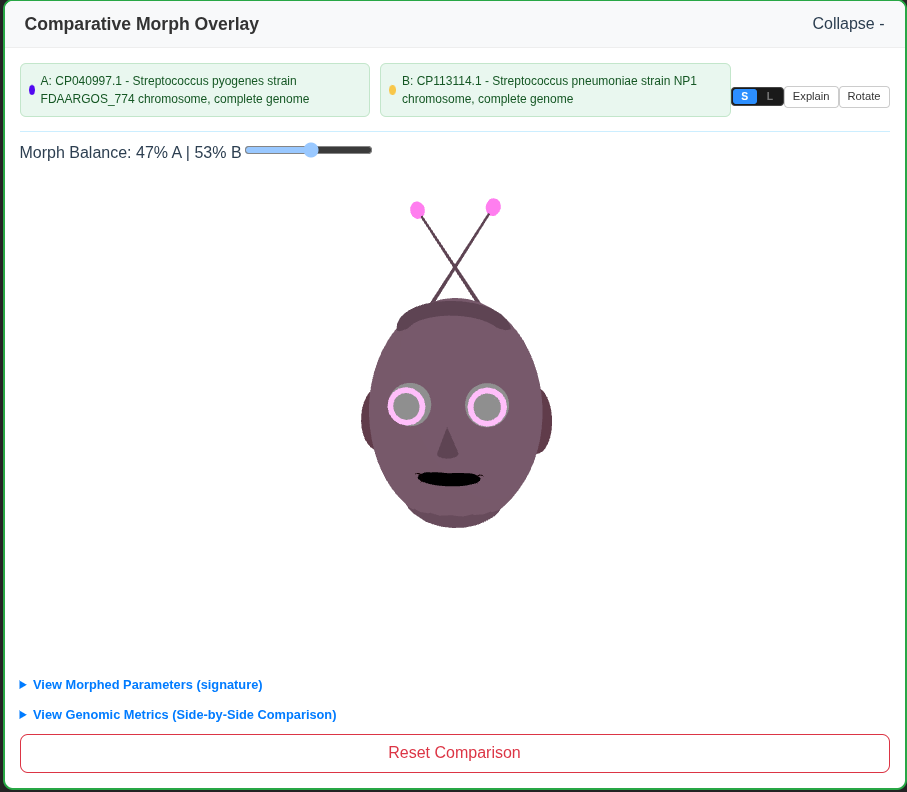
Morphing two 3D Genomes
-
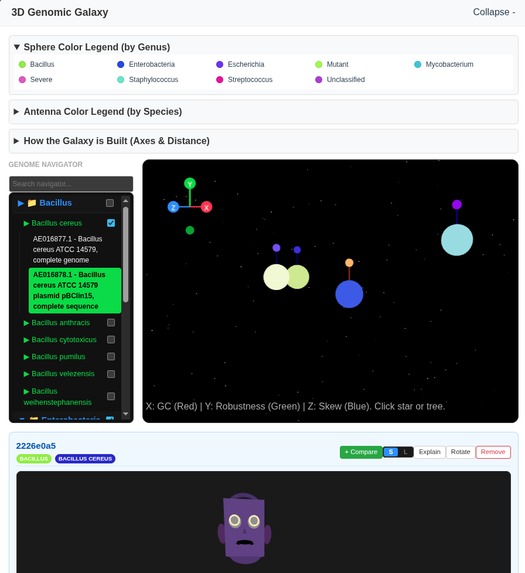
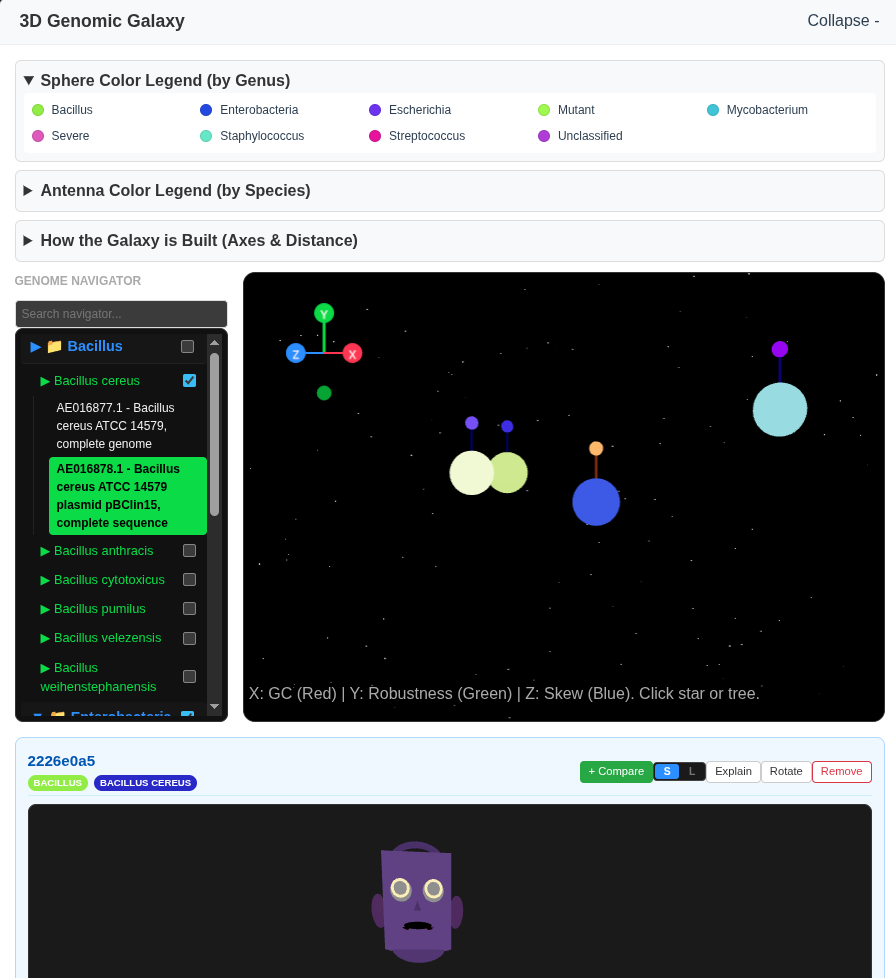
Discovering the 3D Galaxy
-
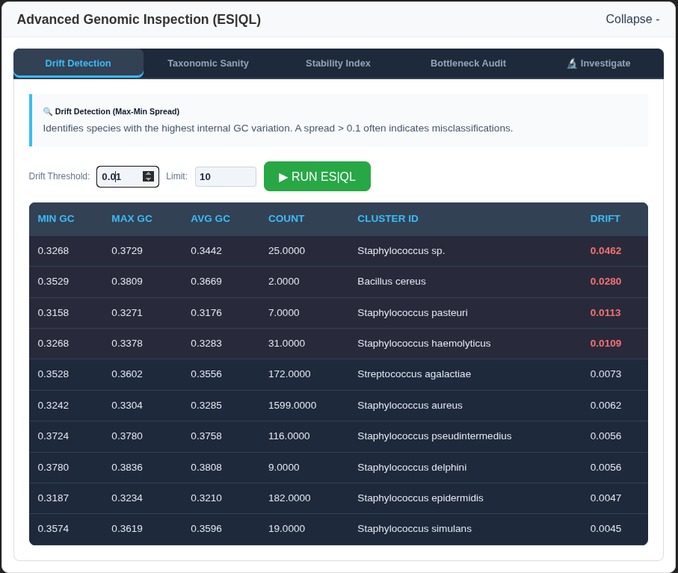
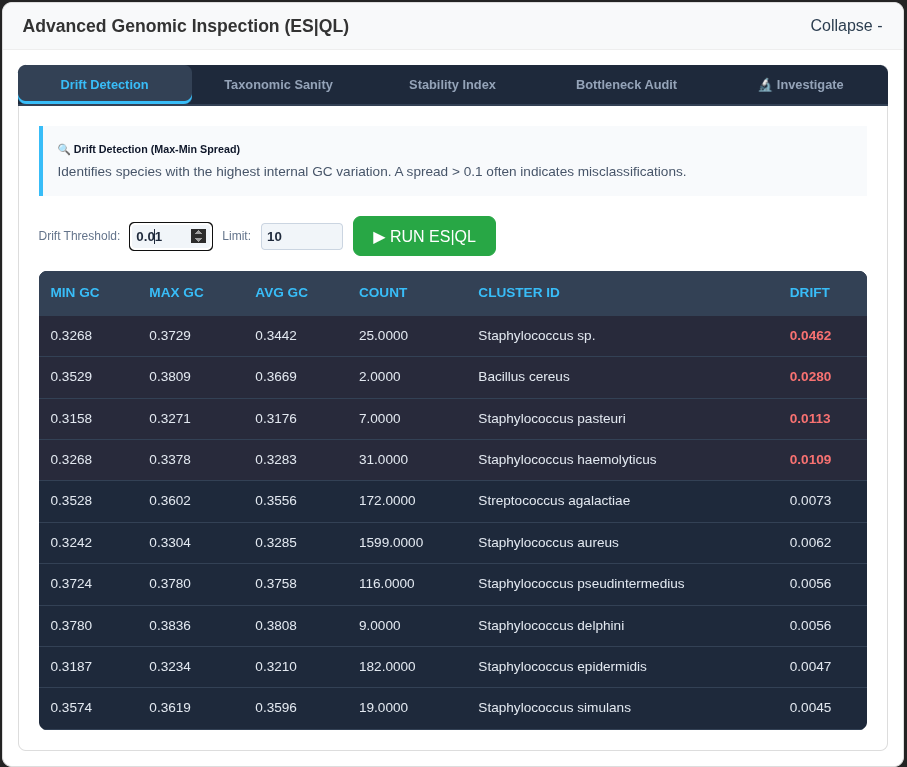
Advanced Genomic Investigation
-
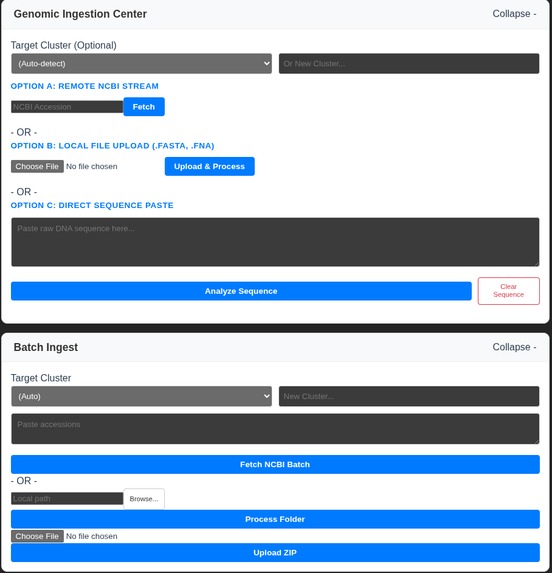
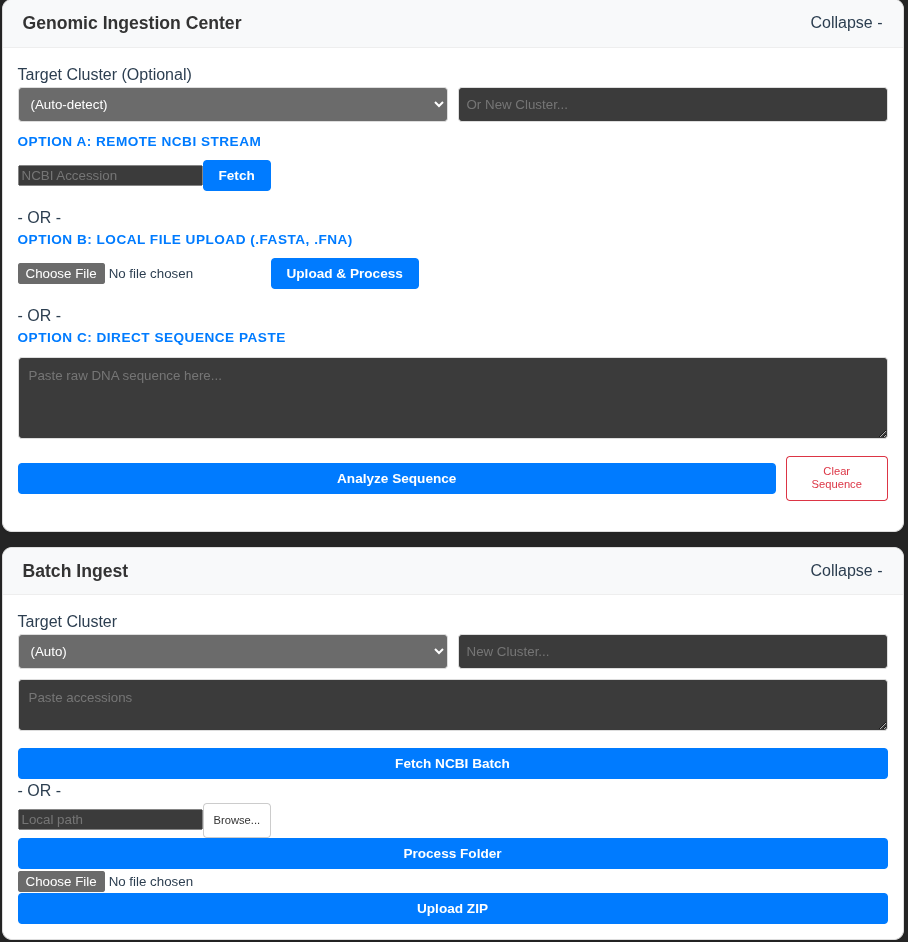
Genomic Ingestion


Inspiration
When I first heard about DNA in school, I didn't just see a string of letters; I imagined faces. I saw unique identities hidden within the code of life, but I didn't know how to bring them to the surface. For years, I wondered how to turn that abstract biological blueprint into something human and relatable. This project was finally my opportunity to bridge that gap—to take those schoolroom dreams and use modern technology to give every genome a vivid, physical identity. I wanted to move beyond spreadsheets and text-matching to a world where we can “meet” our genomic ancestors face-to-face.
What it does
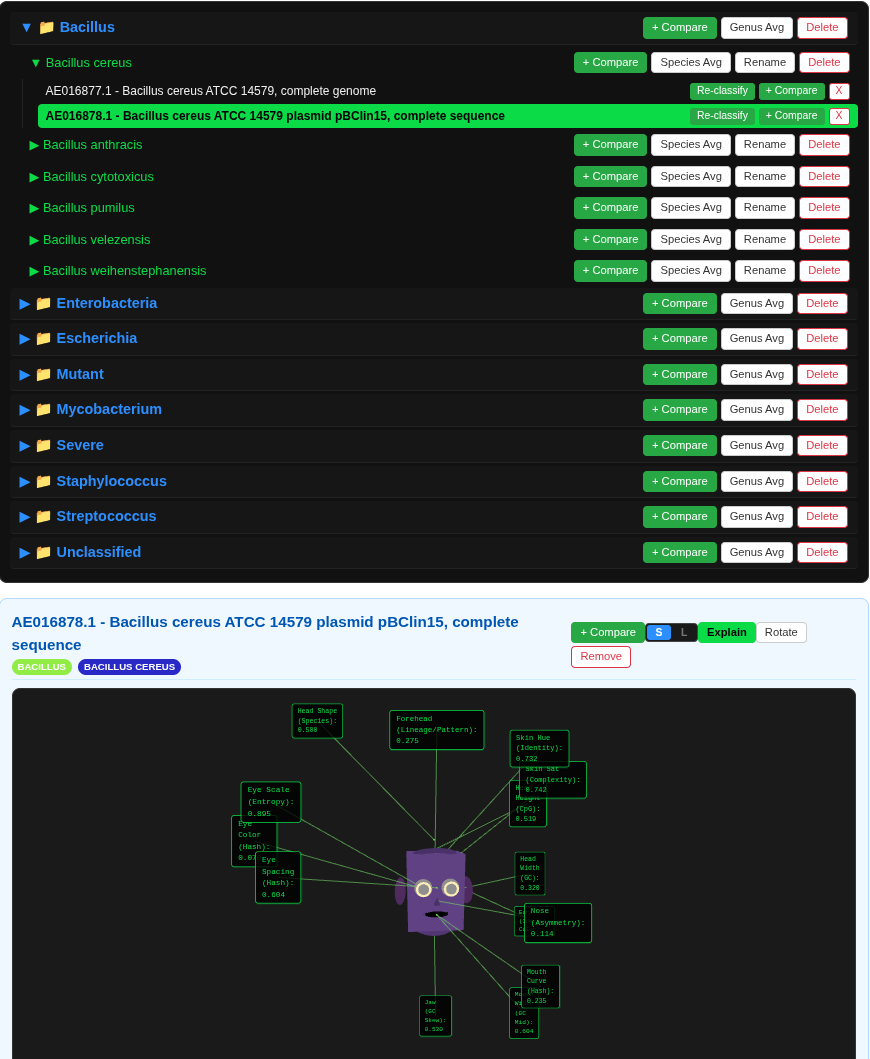
V-Gnome transforms raw DNA sequences into vivid 3D identities. A Genomic Curation Agent (or a human) can fetch genomic data, and complex metrics—like GC-content, codon usage (RSCU), and purine ratios— are instantly mapped to physical 3D traits. It doesn't just show individuals; it visualizes relationships. Using Phylogenetic Blending, the system calculates a "Prototype Ancestor" for each cluster and morphs individual faces to show their genomic distance. Users can explore a 3D galaxy of species, compare genomes side-by-side, and watch as their digital ecosystem evolves through real-time clustering.
Key features include:
- Euclidean Biometric Distance: A novel, intuitive metric that calculates taxonomic relevance in real-time, visualizing search results as spatial proximity in a 3D Galaxy.
- Phylogenetic Blending: A real-time morphing engine that visualizes "Morphological Drift" by blending an individual's face with its ancestral species prototype.
- Advanced Genomic Auditing (ES|QL): A deep-inspection suite using Elasticsearch Query Language to detect genetic bottlenecks, calculate taxonomic sanity, and identify high-variance outliers across the entire database.
- Autonomous Curation & Command Interface: An agent-driven terminal where users can use natural language (RAG) to query the database or use direct commands (e.g., fetch, find anomalies) to orchestrate the backend.
- Live NCBI Streaming: Instant retrieval and 3D instantiation of genomes directly from the cloud via accession numbers.
How we built it
The project is powered by a FastAPI backend and an Elasticsearch "analytical brain". I leverage Elasticsearch not just for storage, but for complex statistical aggregations that calculate species prototypes on the fly. The frontend is built with React and Three.js, utilizing a custom-built 3D HUD that explains how genomic metrics shape each physical part. It maps the genomic robustness to functional 3D features. I implemented an Autonomous Agent Layer that parses natural language and orchestrates multi-step tool calls, connecting the NCBI API to the internal biometric classifier and finally to the long-term memory index in Elasticsearch. I integrated BioPython for sequence processing and implemented a custom "blending logic" that calculates the morphological drift between an individual and its common ancestor.
Challenges we ran into
One of the biggest hurdles was managing the massive scale of genomic indexing without sacrificing real-time performance. I had to optimize the Elasticsearch aggregation queries to handle real-time "Prototype" calculations without lag. Mapping abstract genomic features to intuitive 3D features also required significant iteration—balancing scientific accuracy with a visually compelling aesthetic so that a "stronger" genome actually looks more robust in the 3D space.
Accomplishments that we're proud of
I'm proud of the Novel 3D Genomic Identity, the Novel 3D Classification Engine and the "Novel 3D Genomic Galaxy". Seeing a 3D Facial Genome landing in the 3D Galaxy and immediately starts pulsing based on its mathematical distance to a cluster was a "eureka" moment. I also successfully implemented a multi-step AI Agent that acts. The agent autonomously coordinates fetching, analyzing, and re-classifying data, providing a full execution trace that makes complex bioinformatics accessible to anyone. I'm also proud of the Phylogenetic Blending engine that enables a 3D genomic face to physically "morph" as it moves between evolutionary clusters.
What we learned
I learned that data visualization is the ultimate form of storytelling. By building V-GNOME, I discovered how Elasticsearch’s aggregation powers can be used for biological simulations and as a "Semantic Memory" for biological ancestry. I also gained more experience in mapping multi-dimensional genomic metrics to 3D vertex displacements and material properties, proving that even the most complex data can be made "human" through thoughtful design.
What's next for V-GNOME
The next step for V-GNOME is Speciation Simulation. I want to allow users to "cross-breed" genomic identities, see the resulting 3D phenotypes and watch the genetic drift in real-time. I also aim to expand the agent's reasoning capabilities using the Elasticsearch Agent Builder framework more deeply, enabling it to suggest novel taxonomic discoveries by spotting anomalies in the 3D Biometric space.
Built With
- biopython
- elasticsearch
- fastapi
- react
- three.js


Log in or sign up for Devpost to join the conversation.