-
-
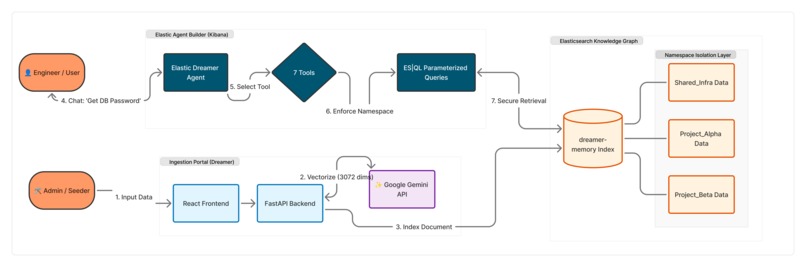
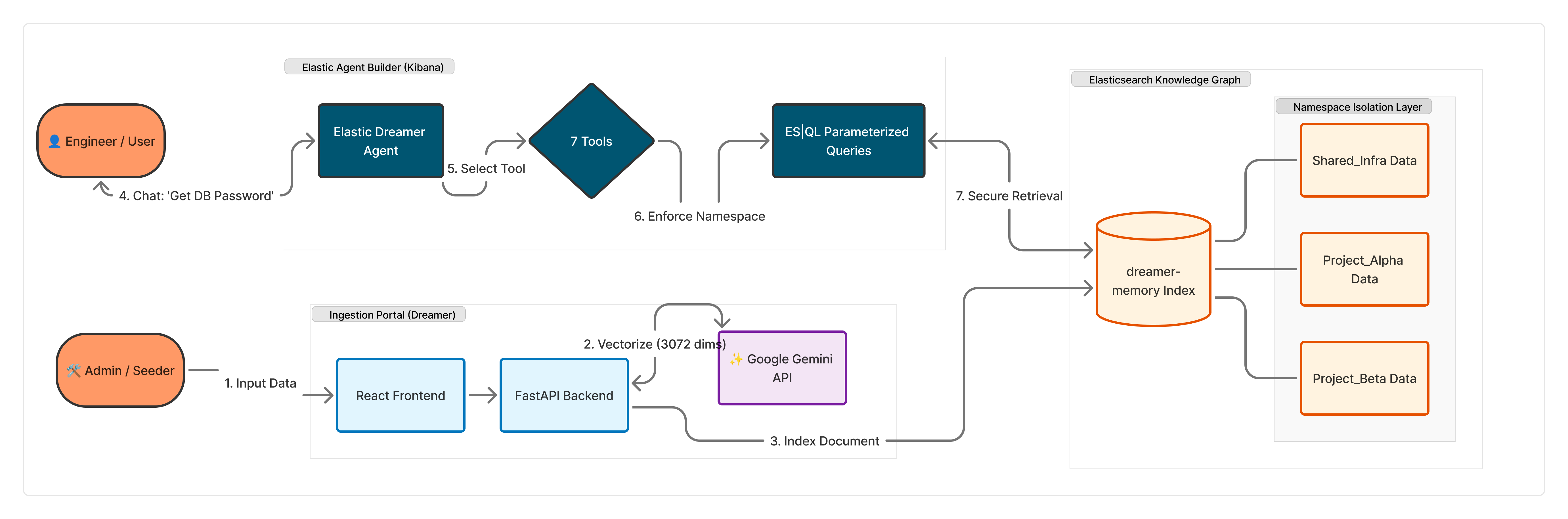
High-level Architecture: Showing the Namespace Isolation Layer and the 7-Tool Agent Builder workflow.
-
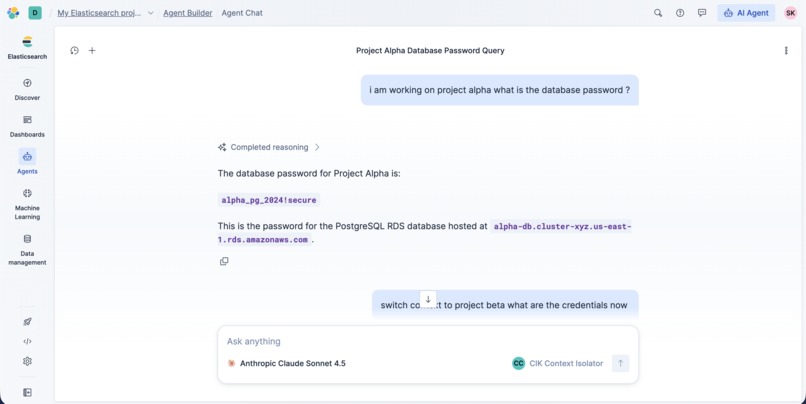
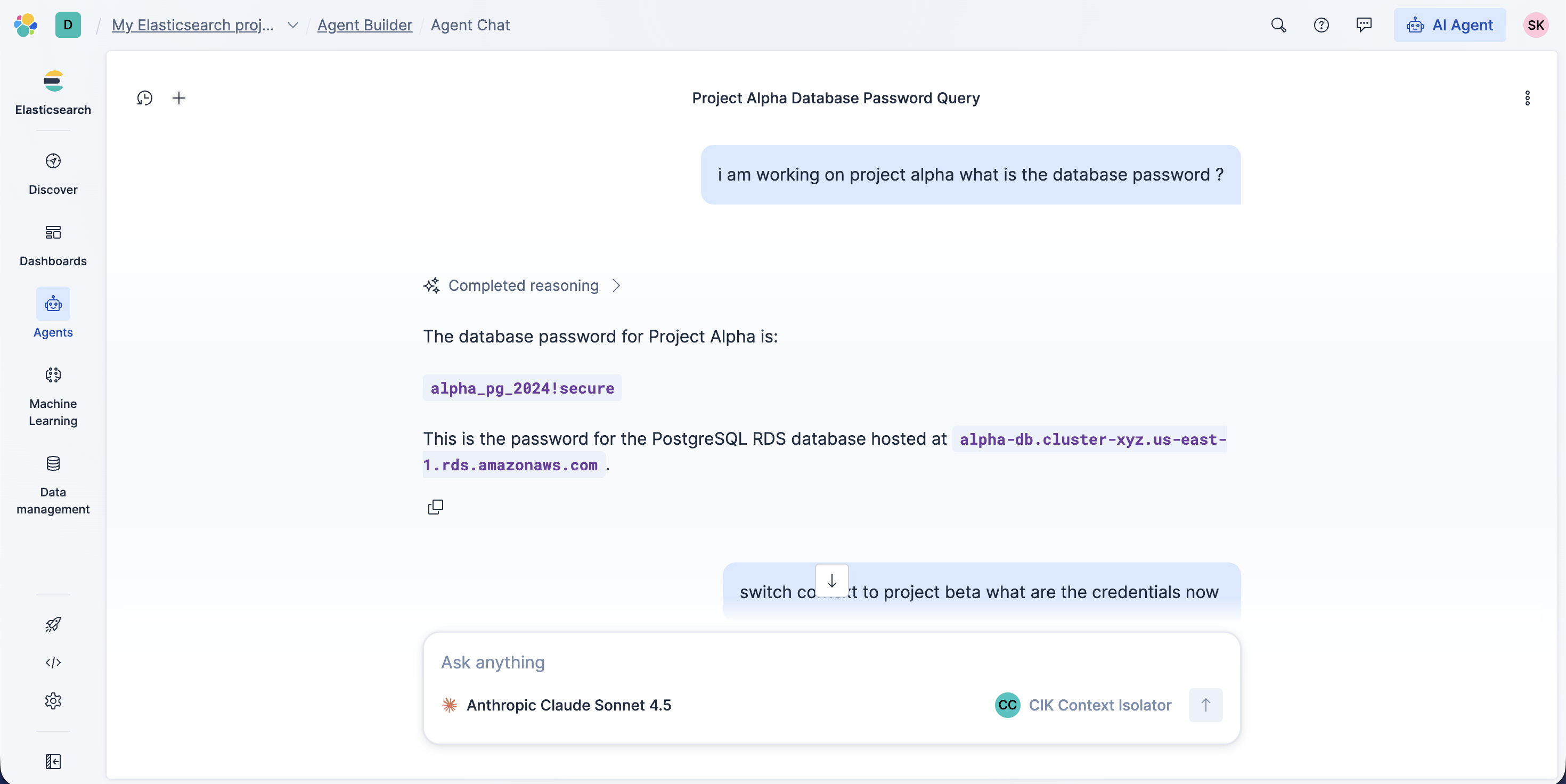
Multi-step reasoning in action: The agent strictly isolates data by project namespace using ES|QL tools.
-
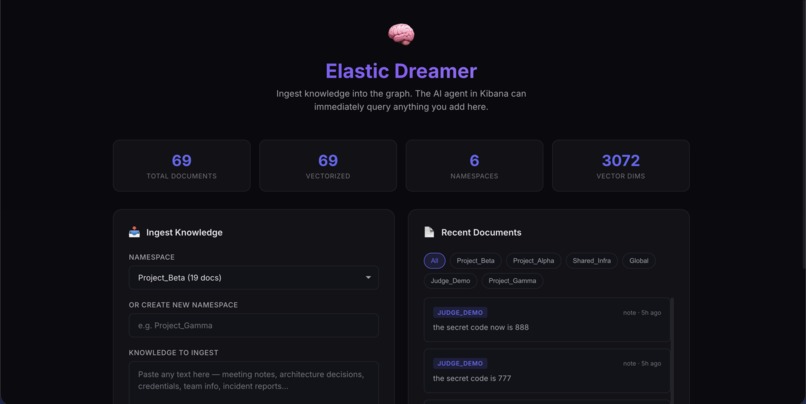
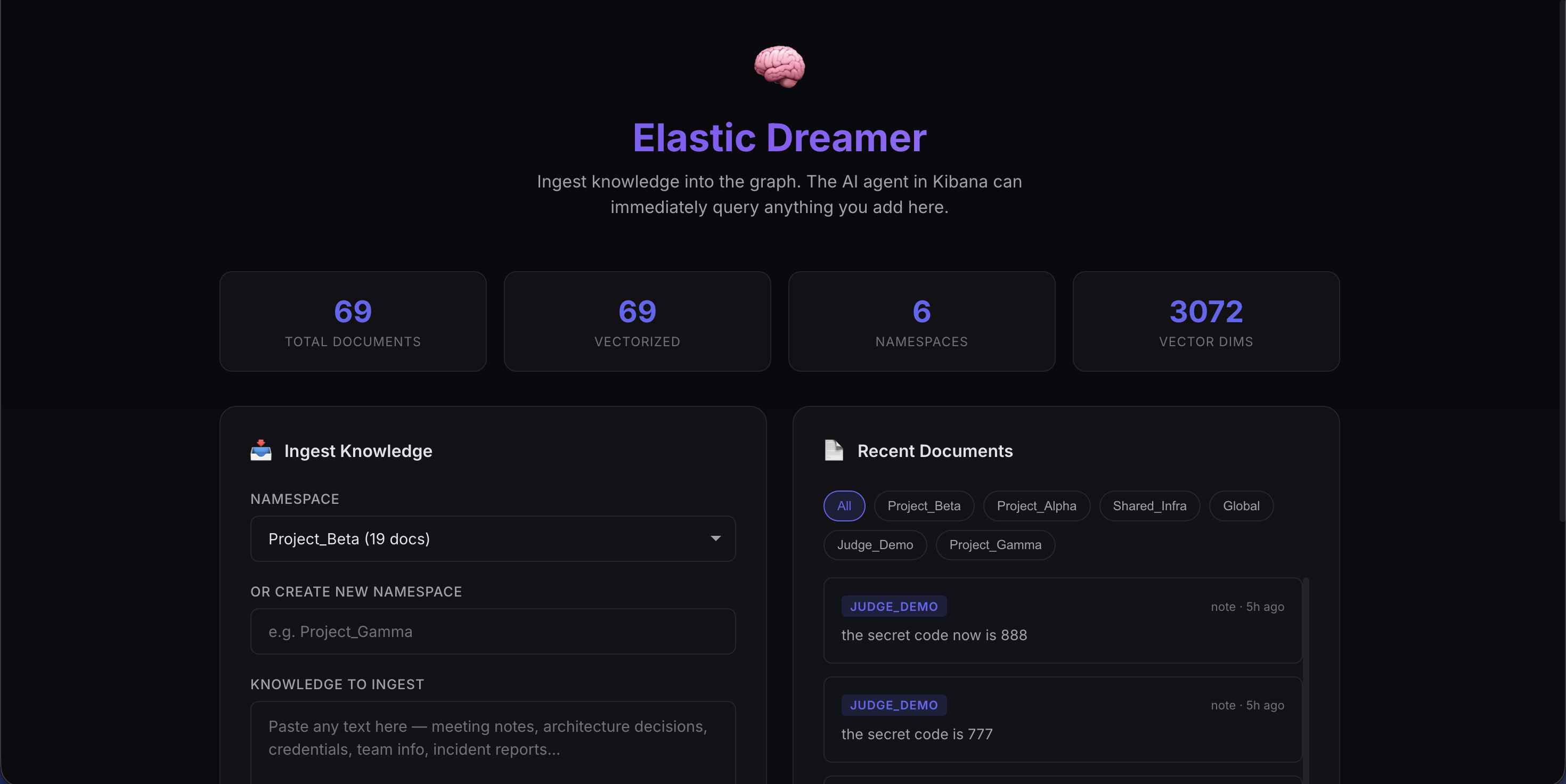
Real-time Data Ingestion Portal: Raw text is instantly vectorized ("dreamed") into knowledge graph triplets.
Inspiration
In enterprise environments, standard RAG pipelines create a critical security risk: Data Flattening. If an engineer working on Project Alpha asks an AI assistant, "What's the database password?", a standard vector search often retrieves credentials from Project Beta. We realised that traditional knowledge graphs (like Neo4j) are too complex for most teams, while flat vector stores are too insecure. We wanted the best of both worlds.
What it does
Elastic Dreamer is a secure Knowledge Graph Agent built entirely on Elasticsearch. It prevents cross-project data leakage by enforcing strict Namespace Isolation.
- Secure Retrieval: When a user asks a question, the agent uses ES|QL Parameterised Queries to lock the search scope to a specific project (e.g.,
WHERE namespace == 'Project_Alpha'). - Graph Reasoning: It uses graph traversal tools to understand relationships (e.g., "Who leads the team that manages the database?").
- Active Learning: It features a "Dreaming" engine—users can ingest raw text via a portal, which is instantly vectorised and added to the graph.
How we built it
We used the Elastic Agent Builder as the brain, orchestrating 7 custom tools:
- 4 ES|QL Tools: For graph traversal, namespace isolation, and analytics.
- 2 Elastic Workflows:
ingest_memory(to write new data) andlog_incident(to take action). - 1 Index Search Tool: Using Google Gemini embeddings (3072-dim) for semantic search.
- The Stack: Python (FastAPI) backend, React frontend, and Elasticsearch Serverless.
Challenges we ran into
The biggest challenge was teaching the LLM to write valid graph queries safely. We solved this by using ES|QL tools with hardcoded parameters. Instead of letting the LLM write raw SQL (dangerous), we force it to just provide the entity name, and the tool handles the logic.
Accomplishments that we're proud of
We are proud of the "Namespace Wall" architecture. Watching the agent correctly refuse to answer questions about "Project Beta" while logged into "Project Alpha" was a huge win. We also successfully implemented Write-Back capabilities, allowing the agent to log structured incidents directly into the index.
What we learned
We learned that Elasticsearch is a graph database if you treat it right. By structuring data as triplets (Head -> Relation -> Tail) and using ES|QL's powerful join and filtering capabilities, we achieved graph-like reasoning without needing a separate database.
What's next for Elastic Dreamer
We plan to add recursive depth-search to the ES|QL tools (allowing multi-hop reasoning in a single query) and integrate Role-Based Access Control (RBAC) so the namespace is determined by the user's login token automatically.
Built With
- docker
- elastic-agent-builder
- elasticsearch
- esql
- fastapi
- google-gemini
- kibana
- python
- react

Log in or sign up for Devpost to join the conversation.