-
-
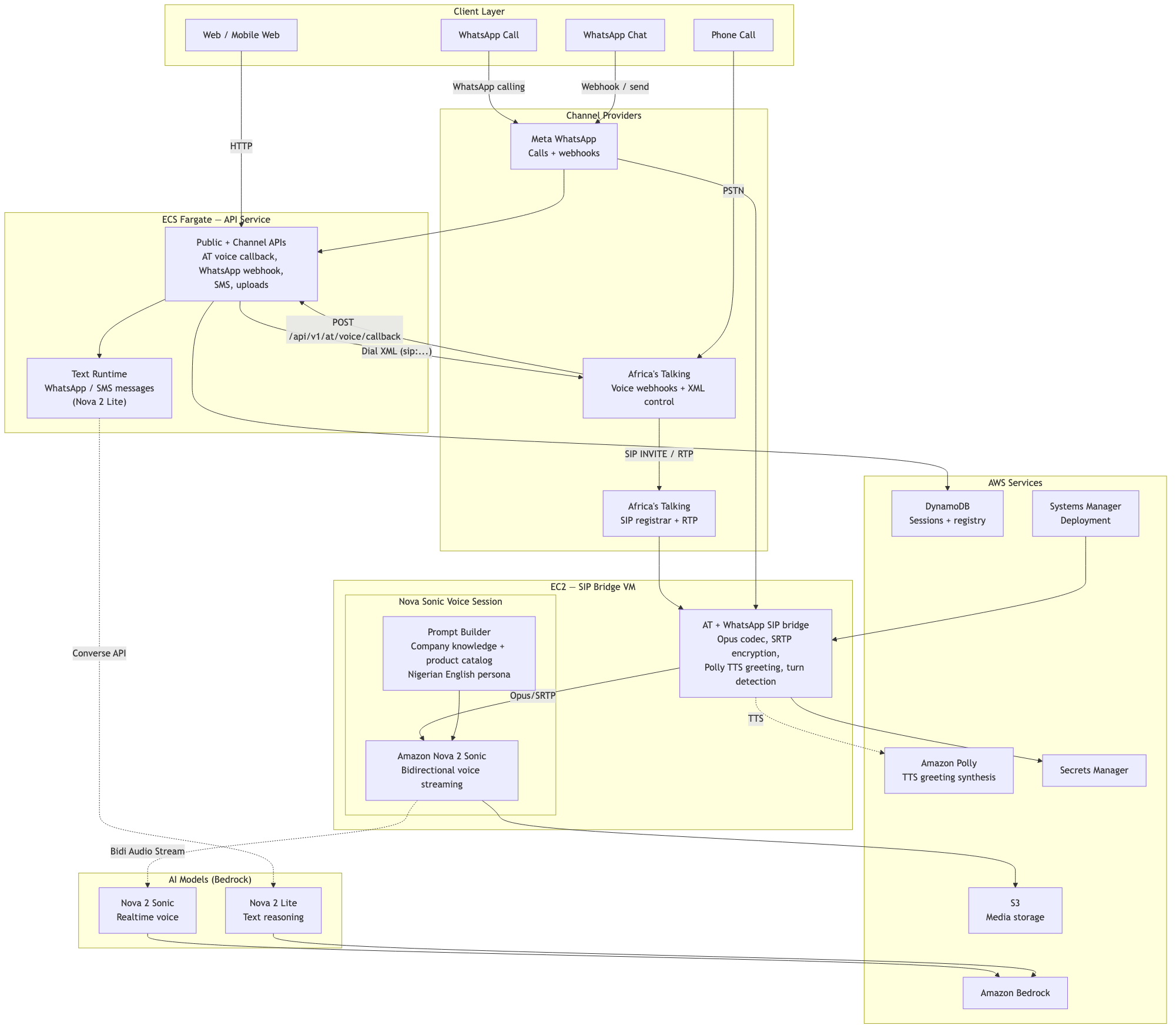
Ekaette-Architecture
Inspiration
Most customer service lines still rely on static recordings, long hold queues, and rigid call-centre routing. Customers spend significant time and airtime waiting to resolve simple requests, and urgent needs are delayed by generic queue systems that do not understand intent or priority. It is a frustrating experience that almost everyone recognizes: too much waiting, too little help, and no fast path for straightforward tasks.
What it does
Ekaette is a configurable multimodal AI voice and messaging assistant built on Amazon Nova and AWS Bedrock. It handles live phone calls, WhatsApp, and SMS for customer-facing businesses.
In a typical phone trade-in flow:
- Customer calls an Africa's Talking SIP number and speaks to Ekaette
- Ekaette detects the swap intent and asks the customer to send a photo/video on WhatsApp
- The photo/video arrives on WhatsApp, gets injected into the active voice session
- Background vision analysis runs (Nova Pro) while the assistant keeps the conversation moving
- The grounded analysis feeds into valuation, negotiation
- Agent upsells accessories and generates image options of how the phone cases look on the device for selection
- Customer decides, and the assistant generates an account number for payment and confirms the payment via webhooks
- Post-sale follow-up continues across channels with full context
The platform supports 6 industry templates (electronics, hotel, automotive, fashion, telecom, aviation) and is configurable per tenant and company without changing backend code.
How we built it
Agent architecture: A root orchestrator agent delegates to 5 specialized sub-agents (vision, valuation, booking, catalogue, support). All agents in the voice pipeline use Nova Sonic v1 for bidirectional audio streaming via Bedrock Runtime. Text channels (WhatsApp, SMS) use Nova 2 Lite for reasoning. Vision analysis uses Nova Pro for device grading and condition assessment. The voice and text pipelines are intentionally separate — Nova Sonic handles real-time bidirectional audio while Nova 2 Lite handles standard request-response reasoning.
Custom Bedrock voice integration: We built NovaBedrockVoiceSession — a custom boto3-based client that manages bidirectional audio streaming with Nova Sonic v1 through Bedrock Runtime. It wraps sessions in a RenewableVoiceSession that handles automatic reconnection and session continuity across interruptions, essential for maintaining call quality during long conversations.
EC2 deployment: The application runs on a dedicated EC2 instance hosting the FastAPI application, SIP bridge, and WebSocket gateway. Unlike short-lived HTTP services, voice calls require persistent connections — a single call ties up a process for the entire conversation duration.
Runtime vs. dialogue separation: The assistant controls tone and phrasing. The runtime controls what it's allowed to do. Tool capability guards check every tool call against the company's capability map. Transfer guards prevent agent handoffs before the greeting completes. Scoped queries enforce tenant/company data isolation at the database level. This separation lets the model be conversational without hallucinating business-critical actions.
4-tier memory: Session state, Memory Bank (cross-session recall), Global Lessons (per-company behavioural corrections), and Industry Knowledge (registry-driven products, booking slots, FAQs).
SIP bridge: A dedicated process converts Africa's Talking RTP/G.711 audio to PCM 16kHz for Nova Sonic and back, with echo suppression, noise reduction, and VAD. WhatsApp calling uses a separate SRTP/Opus pipeline with SIP digest auth.
Testing: 641 automated tests (pytest + Vitest), strict TDD — failing tests written before implementation, production failures converted into regression tests.
Challenges we ran into
Nova Sonic bidirectional streaming. Nova Sonic v1 uses a streaming interface through Bedrock Runtime that required building a custom
NovaBedrockVoiceSessionclass to manage the bidirectional audio protocol, including session renewal and reconnection.Nova Sonic function calling. Getting reliable function calling through a real-time audio stream required adapting our agent transfer mechanism and tool dispatch to work with Nova's tool use format, while keeping the same 5-agent architecture intact.
Duplicate responses after agent transfer. After multiple transfers and session resumption, the model can loop, repeatedly transferring to the same sub-agent. We built a dedup callback that fingerprints each transfer by agent name + content hash and suppresses duplicates within a 2-second cooldown.
Voice accent inconsistency. Without voice cloning, the assistant's accent would change unpredictably between turns — sometimes American, sometimes British, sometimes inconsistent mid-sentence. We solved this through careful system instruction tuning and phonetic spelling (
ehkaitayinstead of IPA notation, which audio models ignore). Reinforcing the pronunciation in both the system instruction and the greeting trigger made it consistent.Cross-channel media injection. Getting a WhatsApp photo into an active voice session required building a background media bridge. The photo arrives on a different service, gets stored, and is injected into the live session's tool context asynchronously while the voice conversation continues.
Scaling the VM for concurrent calls. We started on an EC2 micro instance, but audio processing (codec conversion, noise reduction, echo suppression) caused latency spikes under load. We moved to an EC2 small to handle multiple simultaneous calls without audio degradation.
SIP bridging hidden state. SRTP libraries maintain internal crypto state across packets — filtering packets before the library processes them corrupts that state silently. RTP extension headers from WhatsApp/Meta break naive payload parsing. These bugs are invisible in testing and only surface on real calls.
Accomplishments that we're proud of
- End-to-end voice commerce flow that works on a real phone call powered by Amazon Nova, not just a demo
- Cross-channel continuity — a customer can start on a call, send media on WhatsApp, and continue the same conversation without repeating anything
- A model-resolver abstraction that cleanly separates agent logic from model selection — swap model IDs in one place, not across every agent definition
- Production-grade guardrails — tool capability guards, agent isolation, tenant-scoped data, PII redaction, fail-closed behaviour throughout
- 641 automated tests built through strict TDD across 7 registry migration phases
- 2G accessibility — a customer on a basic phone can call an Africa's Talking number and interact with a Nova-powered assistant
- Multi-model orchestration — Nova Sonic for voice, Nova 2 Lite for text reasoning, Nova Pro for vision, all coordinated through one agent graph
What we learned
Nova Sonic is capable but requires custom integration work. There is no off-the-shelf agent framework equivalent for Nova Sonic's bidirectional streaming. Building the
NovaBedrockVoiceSessionwrapper taught us how to manage low-level audio streaming with Bedrock Runtime — session lifecycle, audio chunking, and error recovery all had to be handled manually.Model abstraction pays off. The
model_resolverabstraction meant model IDs are resolved in one place, not scattered across agent definitions. This made the architecture genuinely provider-agnostic and kept agent logic clean.Most iterations to the model's behaviour had to happen in the runtime layer. Prompt engineering was not enough. Critical workflow decisions — which tools are allowed, when transfers happen, what data is visible — lived in the runtime layer. Nova was strongest when it controlled expression, not the business-critical state transitions.
Voice UX is unforgiving. A 500ms silence gap that's invisible in text feels like an eternity on a live call. We built voice fillers, non-blocking tool execution, context compression (80k → 40k tokens), and silence nudges to keep the conversation feeling natural.
Accent consistency requires engineering, not just prompting. Without voice cloning, we had to pin the voice configuration, use phonetic spelling for the assistant's name, and reinforce pronunciation across system instructions and greeting triggers. IPA notation is ignored by audio models across providers.
SIP bridging is full of hidden state. SRTP libraries maintain internal crypto state across packets — filtering packets before the library processes them corrupts that state silently. RTP extension headers from WhatsApp/Meta break naive payload parsing. These bugs are invisible in testing and only surface on real calls.
What's next for Ekaette
- Extend Capabilities to Instagram, messenger and Tiktok
- Voice cloning when Amazon releases custom voice support for Nova Sonic, replacing our phonetic workarounds with a consistent Nigerian-accented voice. We will also be able to create voices for international counterparts using the WAXAL Library (a new open dataset for African speech technology)
- Deeper AWS-native integration — SQS for async processing, DynamoDB for state management, CloudWatch for voice session analytics
- Conversation analytics for quality scoring, conversion tracking, and agent performance
- Ekaette can be used for multiple industries, but was only defined for the gadget industry for this demo
- More resilient voice behaviour under noisy real-world conditions
- Better memory and customer follow-up across longer time windows
Built With
- africa's-talking-sip/voice-api
- amazon-bedrock
- amazon-nova-2-lite
- amazon-nova-pro
- amazon-nova-sonic-v1
- amazon-web-services
- api
- aws-ec2
- aws-polly
- aws-secrets-manager
- aws-systems-manager
- boto3
- business
- fastapi
- opus-codec
- python
- react-19
- rtp
- sip/srtp
- tailwind-css-v4
- terraform
- typescript
- vite-7
- websockets

Log in or sign up for Devpost to join the conversation.