Inspiration
Most AI benchmarks ask models to answer a question after all the information is already given. We wanted to test a harder and more realistic skill: can an AI figure out what information it needs to collect?
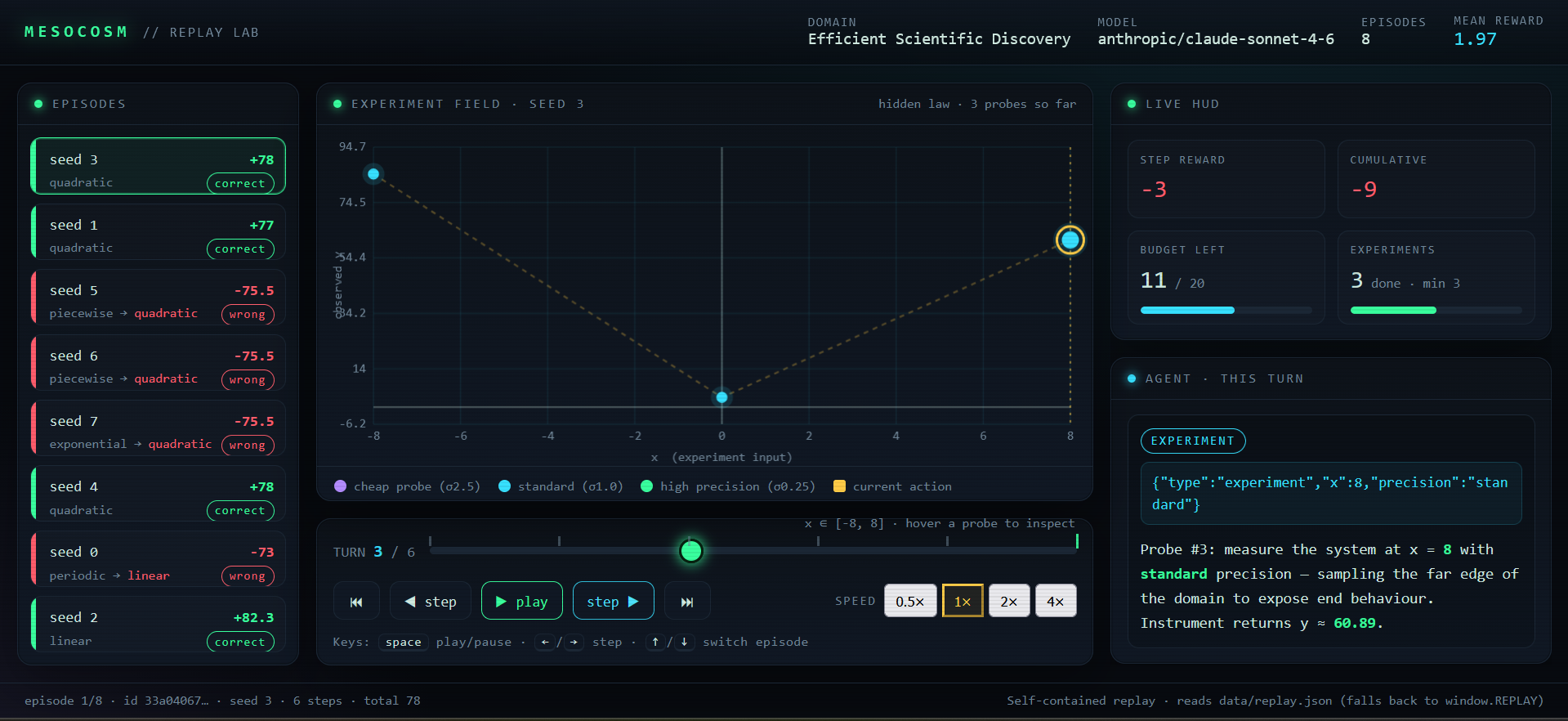
Efficient Scientific Discovery is a Mesocosm benchmark where an AI acts like a scientist trying to identify a hidden function family. The model does not know whether the world is linear, quadratic, exponential, periodic, or piecewise. It must choose experiments, spend a limited budget, observe noisy results, and submit a final hypothesis with confidence.
What it does
Each episode starts with a hidden scientific law and a budget of 20. The agent can run experiments by choosing an x value and a precision level. Higher precision costs more, while cheaper experiments are noisier. After collecting enough evidence, the agent submits a law family and confidence score.
The benchmark rewards correct discoveries, efficient budget use, and calibrated confidence. It penalizes wasted experiments, early submissions, invalid actions, and confident wrong answers.
Why it matters
This benchmark measures active scientific discovery, not passive question answering. In real research, scientists do not get unlimited perfect data. They must decide which experiment is most informative under uncertainty and cost constraints.
Our traces showed interesting model behavior. For example, GPT-4o ran multiple experiments but still misclassified a periodic law as quadratic. Claude Sonnet performed better on some seeds but still struggled with piecewise and exponential cases. This suggests the benchmark exposes meaningful differences in experiment design and reasoning.
How we built it
We built the environment in Python using Mesocosm’s four-endpoint benchmark structure. The environment includes hidden state, deterministic seeded episodes, noisy observations, budget constraints, action validation, scoring, and replay exports.
We also built a showcase viewer to visualize the model’s experiment trajectory, budget, selected x values, observed outputs, final guess, and true law.
Challenges
The hardest part was designing a benchmark that was simple enough to run but still meaningful. We had to balance noise, budget, experiment cost, and scoring so that models could not brute force the answer. We also found that models sometimes failed to follow the JSON action schema, which became an interesting benchmark failure mode itself.
What we learned
We learned that benchmark design is different from app design. The goal is not just to make something cool, but to create a task that produces useful model behavior data. Good benchmarks need hidden state, automatic scoring, reproducibility, and traces that reveal why a model succeeded or failed.

Log in or sign up for Devpost to join the conversation.