BrownDatathon2018
A bit of sentiment analysis, and some machine learning, applied to the Goldman Sachs stock market indicators.
Team Members
- Matthew Huang
- Anand Lalwani
- Wenhao Li
- Juan David Lizarazo
Inspiration
Stock market appeared to be random in the past. But only because the complexity of the world could not be factored into its analysis. Our hypothesis is that this is no longer the case and that using the GDELT dataset additional insight can be brought to bear the stock market's behaviour. Together with quantitative data from Goldman Sachs and easily accessible machine learning techniques, we hope to gain further insights into the stock market.
What it does
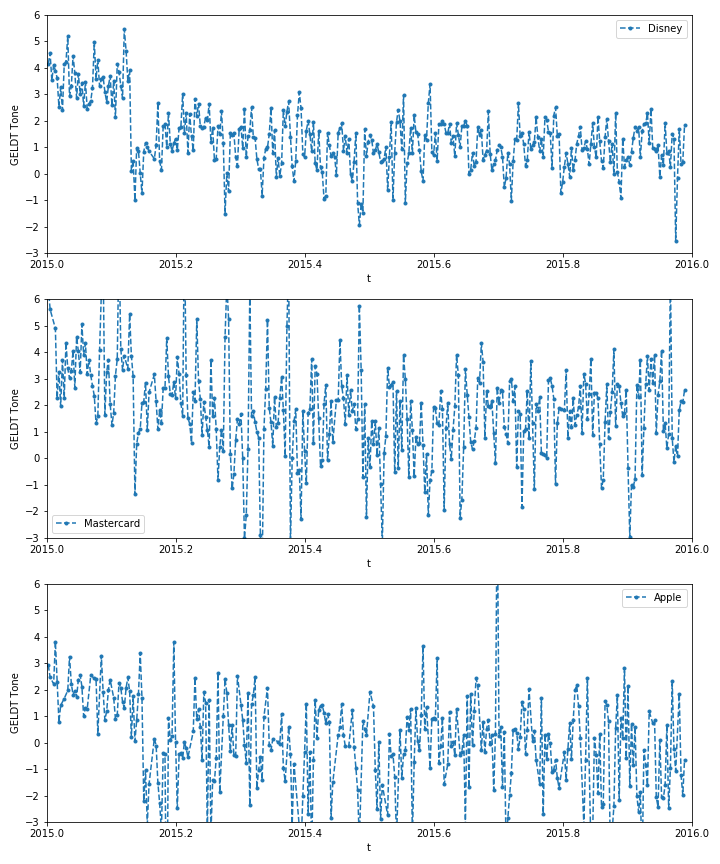
With the help of the GDELT Project, we did sentiment analysis on hundreds of thousands of news articles every day for a full year. We also attempted to scrape tweets with selenium to gain insight into people's opinions towards a company, but have not succeeded yet due to time constraints. The Goldman Sachs data for all stocks was incorporated by using Principal Component Analysis to reduce its dimensions to manageable size. These data were then fed to a neural network to predict the future GS indicators.
How we built it
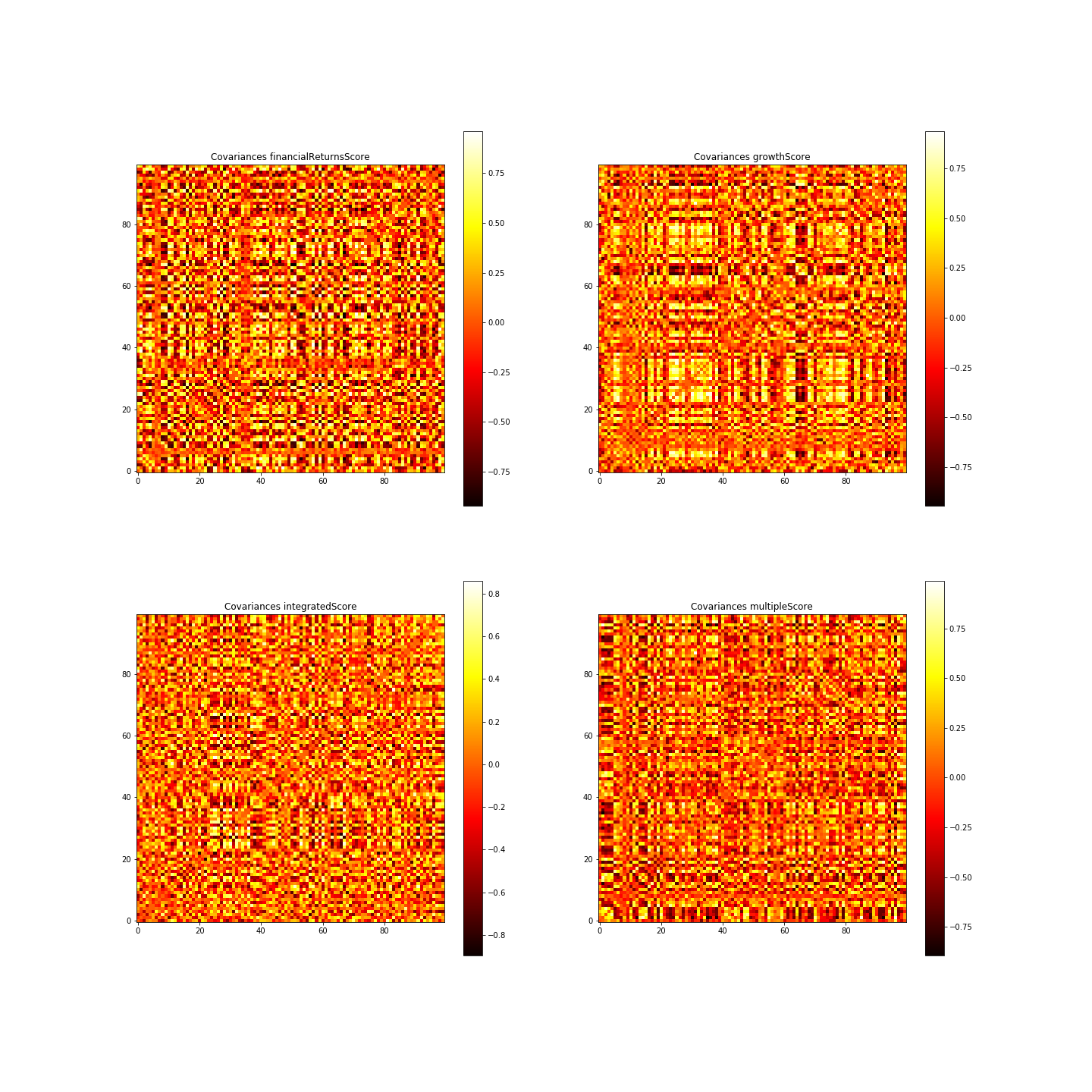
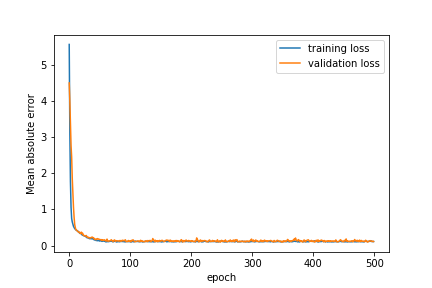
After downloading data from the GDEL project we wrote a Python script to search all posts mentioning a certain company (Disney in our case). We then tried to look into the correlations of the data by building covariance matrix of the GS indicators. Using PCA to select out the most important linear combinations of variables, we finally fed the data from sentiment analysis and the GS indicators into a neural network to try to predict future GS indicators. With some tweaking of hyperparameters, regularization and drop out, we were able to get satisfactory prediction with no significant overfitting.
Challenges we ran into
We spent a lot of effort trying to clean up the data from Marquee, as there are missing dates in the data set. The annoying part is that many of the stocks have missing data on different dates (probably because they were suspended trading? We did not look into the details of this). We attempted to carefully select the range of date request to minimize missing data, and also try to build complex calculations to find an accurate covariance matrix by obtaining covariance pair by pair. To account for missing dates we used a linear interpolation between known dates. This may affect the creditability of our neural network predictions because essentially information from the future is obtained through the interpolation. However, this has been a very rewarding and fruitful experience to every member in trying to gather data ourselves and incorporate it to given data, then construct and fit a neural network.
Accomplishments that we're proud of
We learnt how to deal with the Marquee API and the GDELT API within a short period of time. Our undergraduate learnt a lot in using selenium to scrape data off the web, which is a very essential step in data collecting for further analysis. We are also proud to apply machine learning techniques including PCA and NN to analyze data we scraped ourselves and insightful GS indicators. This preliminary investigation sparked our curiosity in applying what we learnt from our research into industrial applications.
What we learned
Always have good time management and do not invest too much time into a certain aspect of the project. Lots of technical skills including selenium scraping, API interactions, data cleaning, applying machine learning techniques to real-world data.
What's next
To enhance the creditability of our investigation, we should work on getting data without the interpolation, such that we are not getting future data indirectly. This can be done by carefully selecting stocks that have maximal overlaps in trading days. We will try to help our undergraduate partner finish scraping data off twitter, as it will be immensely helpful to his possible endeavor in data science, This analysis can be repeated on multiple stocks and see if such predictions will also work. It will also be very interesting to investigate how to get back stock price from the GS indicators, such that we are actually predicting the future stock price from previous data.
The data that we used in our ML is very limited due to insufficient time and computing resources. We tried to do analysis on Google Cloud Platform to leverage its high computational power, but have not succeeded. GCP will allow us to analyse information up to several days / weeks before a day, do sentiment analysis on contents on even more platforms, and come up with better predictions. If we actually came up with a workable analysis that reliably predicts stock price, automatic trading will definitely be an interesting thing to attempt.
Built With
- gdelt-project
- keras
- python
- scikit-learn
- selenium
")
Log in or sign up for Devpost to join the conversation.