-
-
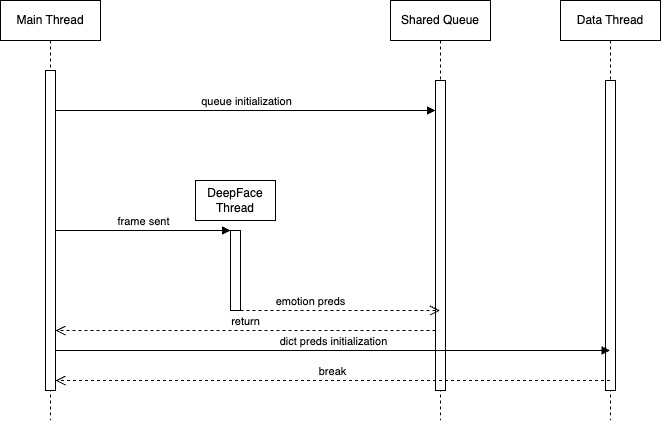
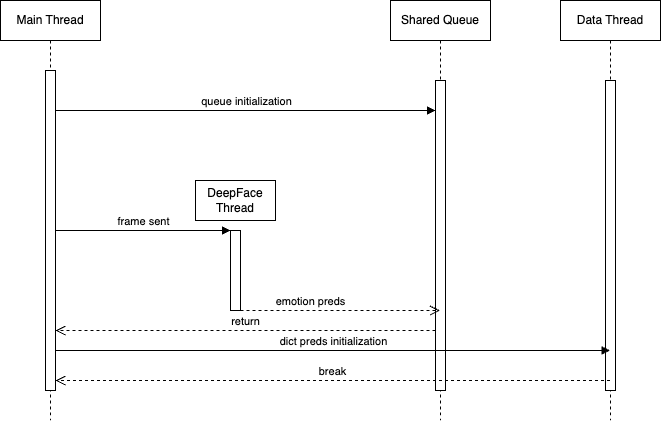
Threading
-
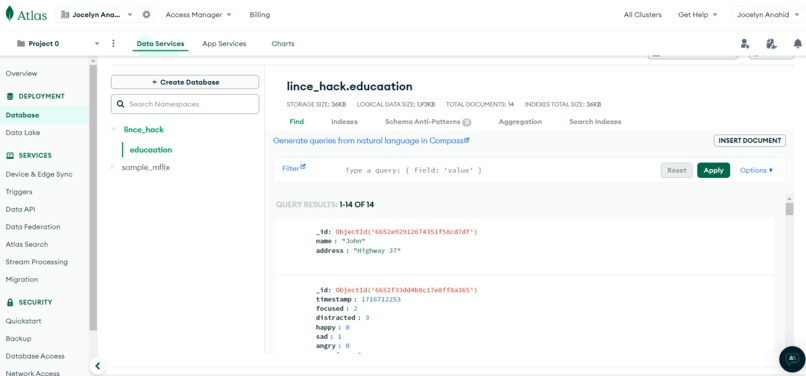
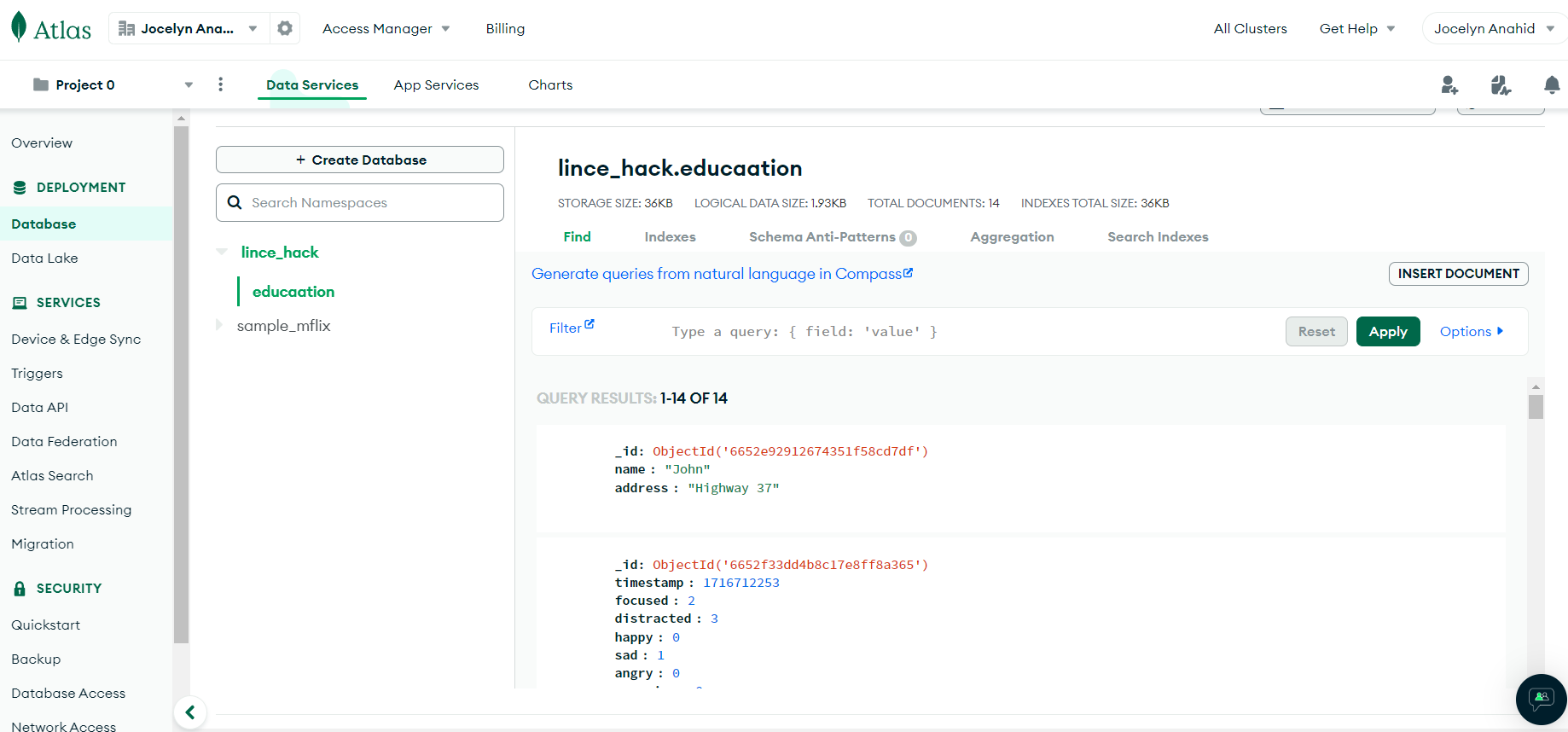
MongoDB Atlas
-
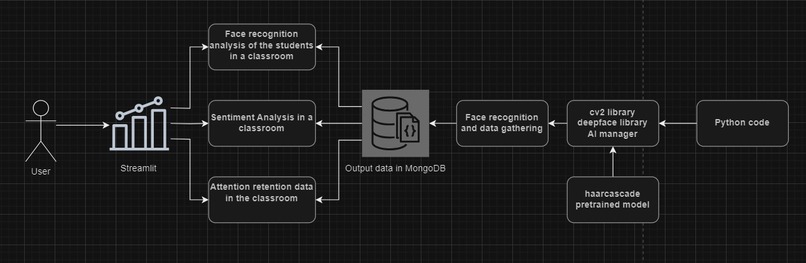
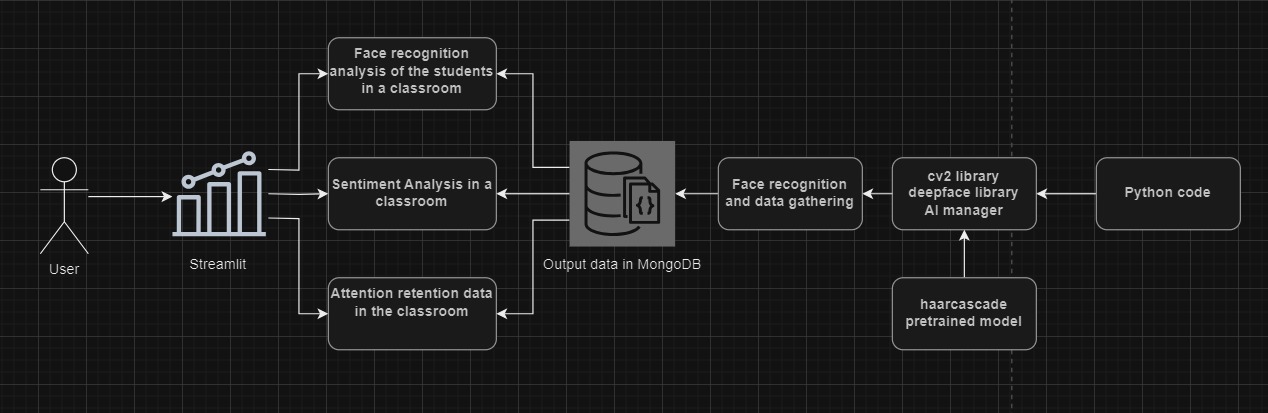
Architecture Overview
-
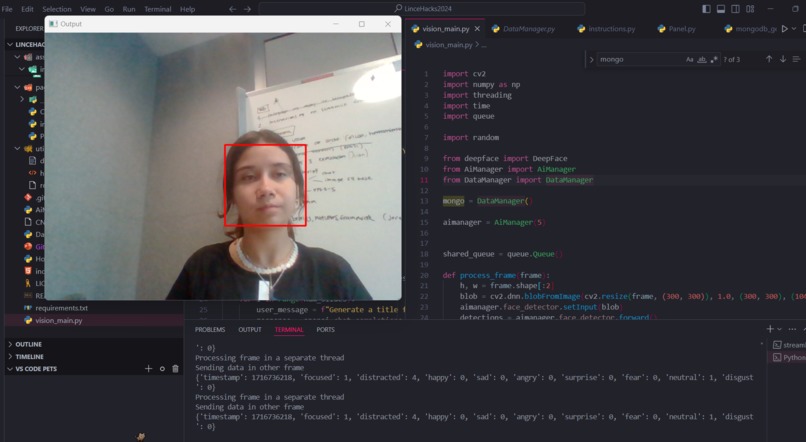
-
Sauce Labs Test
Inspiration
How many times have we, as students, struggled to pay attention in class? or as teachers, how annoying it is to try to get our students to pay attention Small questions with very tedious or complex answers are the ideal archetype that inspired us to create EduVision in order to generate simple and adaptable answers to generate a case where Students as Teachers manage to win.
What it does
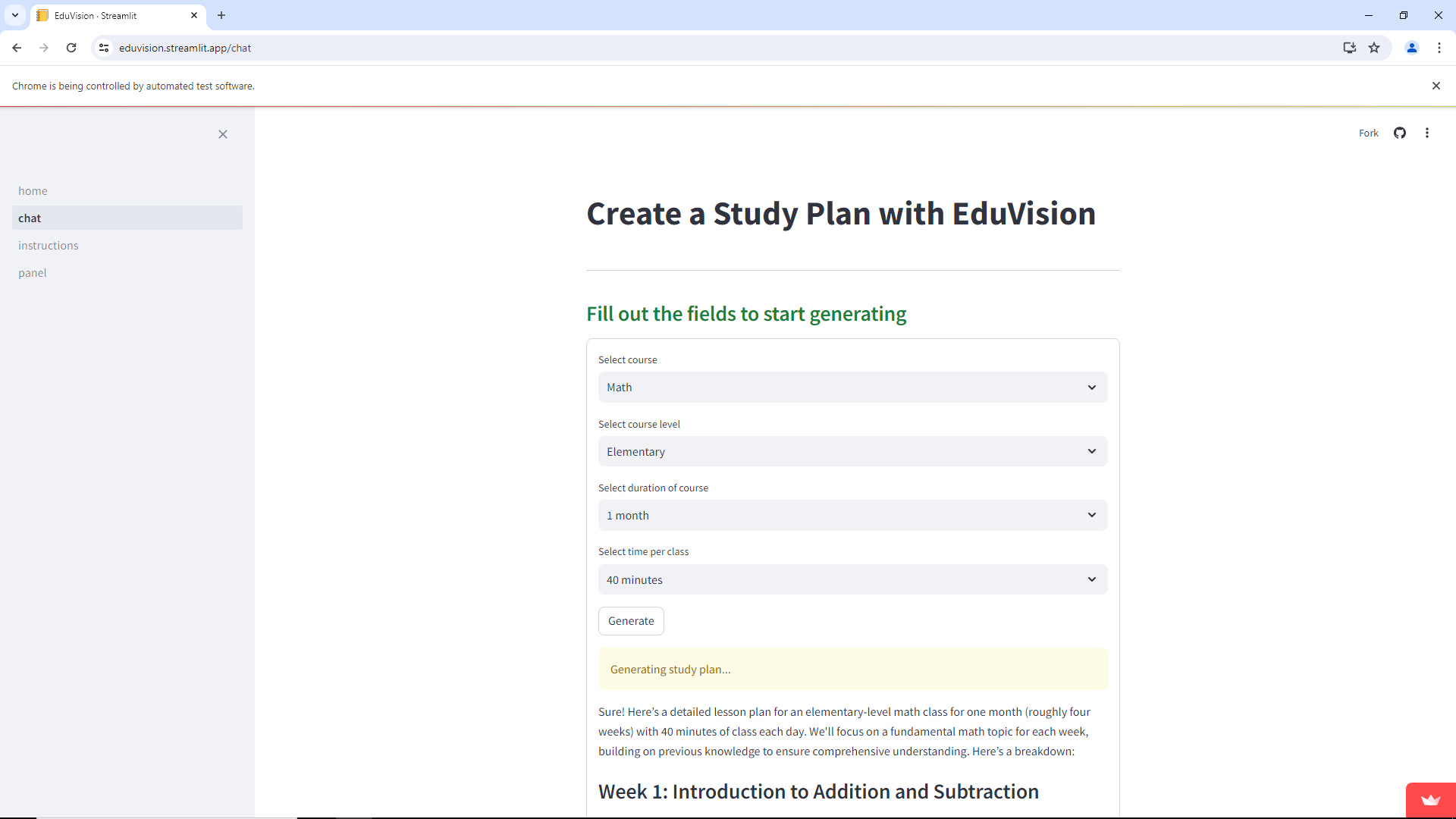
EduVision is a set of digital tools powered by Computer Vision models as well as Artificial Intelligence. A teacher can access our website, and can decide whether to create a presentation for their class, create a syllabus using something as a base, or if they would like to see the statistics of students present in class who are paying attention to the class. Likewise, with this data, the teacher has empirical data at hand that will facilitate the way to generate an action plan for his classes as well as for the students by having new educational resources that will help them in their training.
How we built it
- Programming Language:
- Python
- Front End:
- Streamlit
- Computer Vision:
- Opencv
- Deepface
- Mediapipe
- Large Language Model:
- OpenAI
- Data Base:
- MongoDB
Models
- Haar Cascade: Haar Cascade is an object detection method used primarily for face detection. It is based on the Haar-like features introduced by Viola and Jones in 2001. The model uses a series of increasingly complex classifiers (cascade) applied to regions of an image. Each classifier uses simple rectangular features computed quickly through integral images. Fast detection, especially in real-time applications. It is relatively simple and requires less computational power compared to deep learning models. It can be less accurate, particularly in complex or varied lighting conditions, and may struggle with different facial orientations and expressions.
- DeepFace: DeepFace is a deep learning-based facial recognition system developed by Facebook in 2014. It uses a deep convolutional neural network (CNN) to learn facial representations by training on a large dataset of labeled images. It processes the input image through multiple layers to capture intricate facial features and constructs a high-dimensional embedding. High accuracy in recognizing and verifying faces due to the depth and complexity of the network. It is robust to variations in lighting, orientation, and facial expressions. Requires significant computational resources for training and inference. It also needs a large and diverse dataset for effective training.
Threading
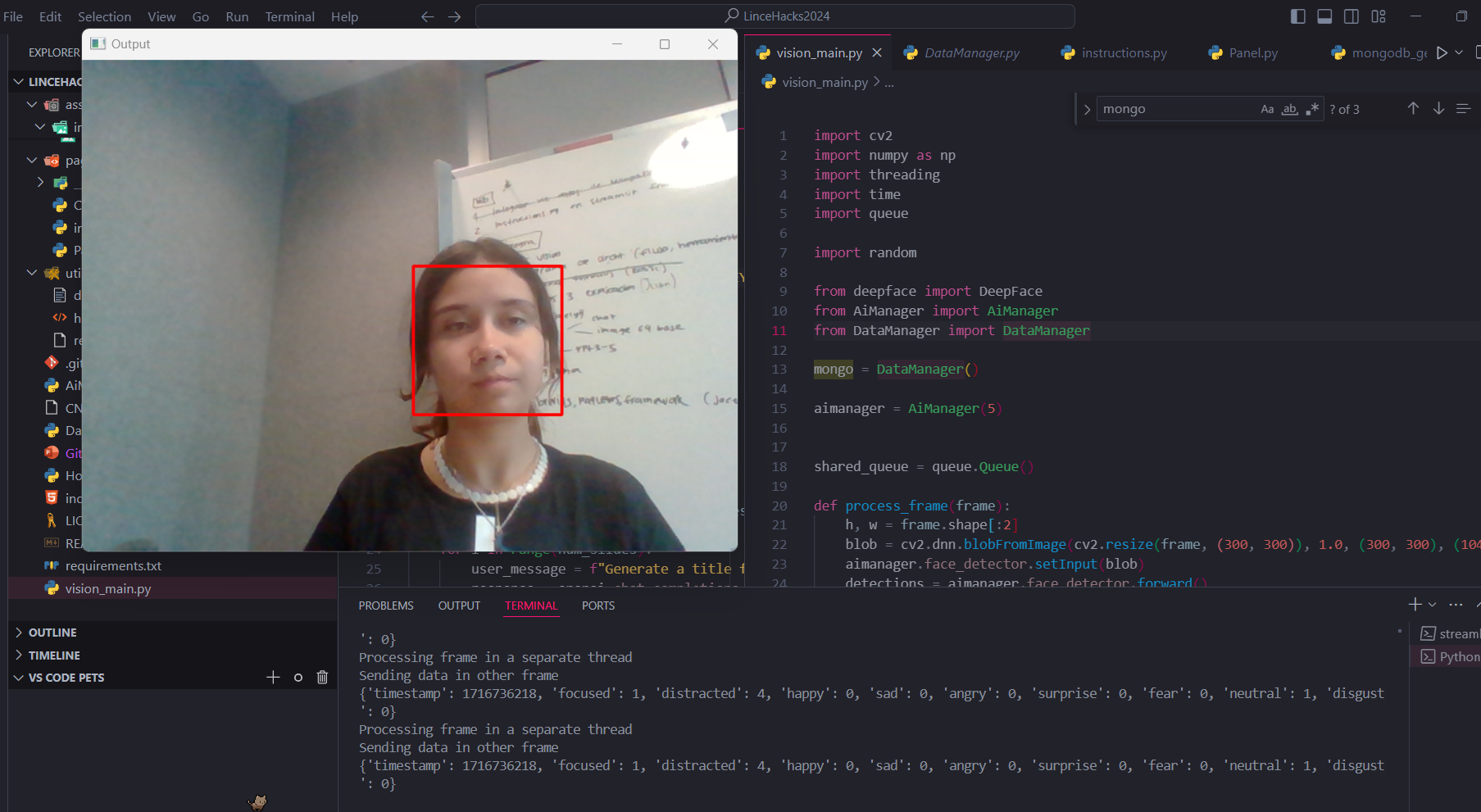
The computer vision section of the project required support for multiple time based calculations, in which running every piece of code on the main thread would have not been optimal. To solve this problem we implemented a multi threaded approach, which can be seen along with the diagram above
Generative AI
We implemented the most recent OpenAI LLM gpt4-o to process text and base 64 encoded images to generate personalized lesson plans for teachers. We also used pptx api. The generate_slides_titles function is defined to generate titles for a specified number of slides based on a given topic. It initializes an empty list, slide_titles, and then enters a loop that runs for the number of slides specified. In each iteration, it constructs a message asking for a title for the current slide based on the topic, presumably to be used in a call to the OpenAI API model gpt3.5-turbo
Challenges we ran into
One of the principal challenges we had was the implementation of computer vision into the project, as integrating it flawlessly was not easy due to some library compatibility issues. We tried creating several Docker containers to run YOLOv8 and deepface, but some versions were not adding up to make it work on our Jetson. So we decided to implement it locally on someone's machine and re-install dependencies on a new environment. After this, we were able to run the libraries with no issues. Another problem we encountered is the implementation of MongoDB, we required an open IP address to where we would be making the requests, but our university blocked some of those queries, so we had to implement a VPN connection to make our IP addresses discoverable.
Accomplishments that we're proud of
We are really happy that we had enough time to implement a computer vision system into the project, that did not only classify the image and show how are the students doing, but also log this information to a MongoDB for further analysis on the Streamlit panel ready to view for users
What we learned
We discovered the use of non SQL databases such as MongoDB, it was interesting to see that we were not able to operate on a single thread, but we had to create different processes to make the vision simple less overloaded.
What's next for EduVision
In order to achieve our goals we believe that a full implementation that could segment the information of users in physical places, logging data individually could really enhance the learning experience. By introducing a multimodal model we could also implement an even better experience for teachers, allowing the generation of full power point slides filled with information and images that elevate the experience.

Log in or sign up for Devpost to join the conversation.