-
-
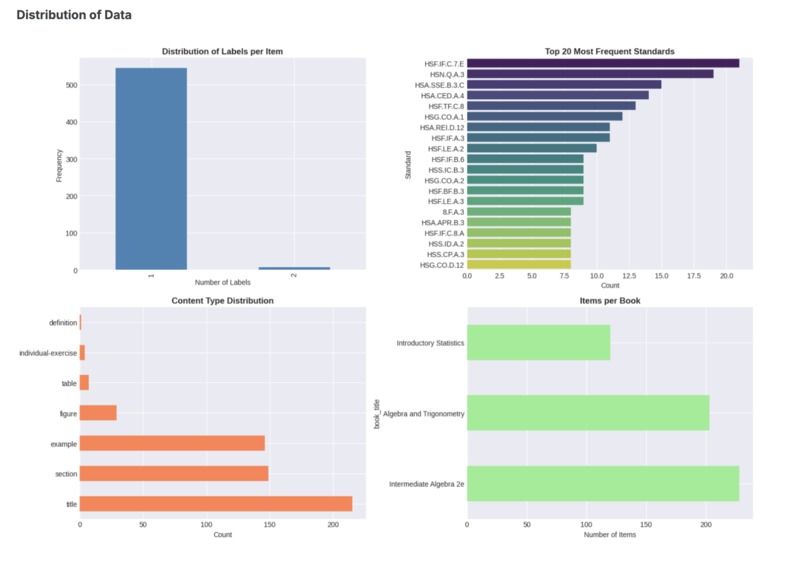
EDA - Distribution of Data
-
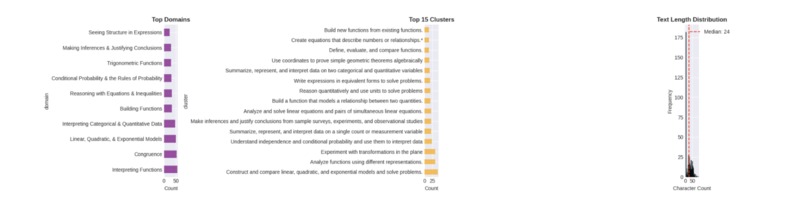
EDA - Hierarchical Structure Analysis
-

Evaluation

GitHub link: https://github.com/dothanhtam91/OpenStax---2026-Rice-Datathon-Mapping-Sta
tldr
We participate in the Education Track and GeminiAPI track
Education Track: OpenStax
We approach this as an NLP classification task where the goal is to grasp the semantics of the context and map it to the correct standard code, going beyond the capabilities of a standard classification model.
Gemini Track:
We leverage the Gemini API for data augmentation, which has allowed us to significantly improve our overall accuracy scores.
1. How we define the problem
We define this as a classification problem, we our goal is to label each sections of the textbook with the correct standards. Here are some rules about standards labeling:
- 1. Items can have one or more standards associated, and they may or may not have a valid url to fetch content from.
- 2. tems have a type (e.g. section, title, example, individual-exercise, figure, etc.).
- 3. When present, the values in the [“numbers”] array are specific instances of that item that can be found in the text (e.g. example 1.2, section 11.2).
- 4. Sections are the least specific type, followed by titles, then the remaining types--associated with specific elements--are of equal specificity.
This notebook is run on Kaggle environment with GPU T4 x2
2. Our Approach
For each dataset (train.json and test.json), we are provided with standard codes and their corresponding definitions, alongside textbook sections mapped to their respective labels. We have identified this task as a Hierarchical Multi-Label Classification (HMLC) problem. Given the availability of both formal definitions and labeled examples, we implemented a Hybrid Retrieval-Augmented Fine-Tuning (RAFT) architecture to ensure maximum robustness.
You can refer to our notebook via this link: https://www.kaggle.com/code/thanhtamdo91/openstax-2026-rice-datathon-mapping-standards-i
3. Data Preparation
The json's structure is deeply nested: Books → Chapters → Sections → Concepts → Clusters → Items.
There are two sections in the json file (train and test), which are Standard definitions and text sections with associate standards code. Our first task is to represent the data as a dataframe by flattening its according to hierarchy order.
Then, we enrich our data by
- 1. Consolidate Text Field: description and text are often spares. We create an unified input_text column that merge those data together.
- 2. Parse Label: the standard column is currently a string representation of a list. We will convert this into a list of strings for multi label classification.
- 3. Metadata injection: Append the domain and cluster to the text. For example: "Understand slope" is ambigous, but "Expression and Equation: Understand slope is highly specific".
However, the train.json file only utilizes 76 out of the 156 distinct standard codes. This means more than half of the target labels are missing from the training set. To address this, we leveraged Gemini API to generate 1,000 synthetic data artifacts to ensure coverage for all standard codes. You can refer to this code on how we leverage the Gemini API:
import pandas as pd
import google.generativeai as genai
from kaggle_secrets import UserSecretsClient
import time
user_secrets = UserSecretsClient()
api_key = user_secrets.get_secret("GEMINI_API_KEY")
genai.configure(api_key=api_key)
model = genai.GenerativeModel('gemini-1.5-flash')
def augment_text(text, concept, cluster):
if pd.isna(text) or text == "":
return None
prompt = f"""
You are an educational content creator.
Original Text: "{text}"
Subject Concept: {concept}
Cluster: {cluster}
Task: Rewrite the 'Original Text' to be slightly different but pedagogically equivalent.
Maintain the same mathematical or educational meaning.
Provide only the rewritten text.
"""
try:
response = model.generate_content(prompt)
return response.text.strip()
except Exception as e:
print(f"Error: {e}")
return None
df_subset = df.dropna(subset=['text']).head(10).copy()
print("Starting augmentation...")
augmented_texts = []
for idx, row in df_subset.iterrows():
new_text = augment_text(row['text'], row['concept'], row['cluster'])
augmented_texts.append(new_text)
time.sleep(2) # To avoid rate limiting
df_subset['augmented_text'] = augmented_texts
df_subset.to_csv('augmented_training_data.csv', index=False)
4. Exploratory Data Analysis
First, we explore the distribution of the data
- Number of columns and rows: (551, 12)
- Number of distinct labeling: 173
- Number of distinct label in train dataset 96
- Number of data that does not have code labeling: 0
- Number of items with multiple standards labels: 7
Distribution of Data

Hierarchical structure analysis

5. Model Selection: Semantic Alignment via Dual-Stream Transformers
Since, we define the core challenge of this task is the "vocabulary gap" between instructional textbook language and the technical, formal language used in academic standards. To bridge this, we treat the labeling task as a semantic retrieval problem—similar to how modern search engines match natural language queries to relevant documents—rather than a simple flat classification.
The Solution: Bi-Encoder & Cross-Encoder Architecture
This is a Dual-Stream Transformer model to map both textbook sections and standard definitions into a shared semantic vector space.
- Vectorization: Using a high-performance pre-trained model (such as all-mpnet-base-v2), we generate dense vector embeddings for every standard definition. These are stored in a FAISS (Facebook AI Similarity Search) vector database for high-speed retrieval.
- Semantic Matching: Instead of treating standard codes (e.g., 8.EE.B.6) as meaningless labels, the model uses the formal definition as a rich feature. This allows the system to understand why a section on "slope" matches a specific standard, even if the phrasing differs.
Why we believe this approach is best suit for the problem
- Bridging the "Vocabulary Gap": Traditional models struggle when a teacher's explanation doesn't use the exact technical keywords found in the curriculum. Our dual-stream approach focuses on the underlying mathematical concepts, aligning the pedagogical intent with the regulatory code.
- Solving the Imbalance Problem: Textbook datasets are often imbalanced, with hundreds of examples for common topics like Algebra and almost none for niche standards. Because our model learns the meaning of a standard through its definition, it can accurately label sections for standards it has seen few (or zero) times during training—a capability traditional classifiers lack.
- Efficiency This architecture offers scalability and precision through a two-stage pipeline:
- Stage 1 (Bi-Encoder): Rapidly narrows down hundreds of potential standards to the top candidates.
Stage 2 (Cross-Encoder): Deeply analyzes the top candidates alongside the textbook text to ensure mathematical accuracy.
Hierarchical Logic: By operating in a semantic space, the model respects the natural hierarchy of education. If the model is uncertain about a specific sub-standard, its "best guess" is mathematically grounded within the correct domain and cluster, rather than being a random or unrelated error.
6. Evaluation
Because this is a retrieval-heavy task, traditional accuracy doesn't tell the whole story. And such as one labeling can be used for different context, we use Hit Rate @K to see if the right answer is in the model’s "shortlist," which is what matters most for helping human experts. Macro-F1 ensures the model is actually learning the math definitions for rare topics rather than just memorizing the most common codes, while Hamming Loss gives the model partial credit for sections that cover multiple standards. In short, we're using the definitions as a superpower to ensure the model stays mathematically grounded, even when data is sparse.
Here is our result

Our model achieves 77.7% accuracy for 'Hit Rate @ 5,' ensuring that a correct standard is included in the top 5 candidates for the vast majority of sections.
On the other hand,
- The "Rare Standard" Struggle (Macro vs. Micro F1)
- Micro F1 (0.2589) vs. Macro F1 (0.0350): This is the most telling part of the data. The Micro F1 is significantly higher, meaning the model is doing a decent job on the "popular" standards that appear frequently in your data.The Macro F1 gap: The very low Macro score means the model is currently failing on the "long-tail"—those niche standards that only appear once or twice. It’s likely playing it safe and over-predicting common topics while missing the rare ones.
- Precision and the "Exact Match" (0.4149)
- Exact Match is identical to Hit Rate @ 1. This suggests that most of textbook sections only have one "correct" standard. When the model gets the top prediction right, it achieves a perfect score for that section.
- The Margin of Error (Hamming Loss: 0.0257)
- Low is Great: A Hamming Loss of 0.02 is very low. This means that out of all the possible standards in dataset, the model is only "guessing wrong" on a tiny fraction of them. It’s not out there making wild, random guesses; it’s being relatively precise, even if it’s not always hitting the bullseye.
Where the most common classification happened


7. Conclusion
This is our best result so far beside those previous approach.
Baseline Approach: TF-IDF & One-vs-Rest Our initial strategy involved using TF-IDF on combined text fields paired with a One-vs-Rest (OvR) classifier. We treated the dataset primarily as a single-label problem, allowing for occasional multi-label instances based on the train.csv labels. Despite rigorous hyperparameter tuning, this approach peaked at 40% accuracy.
Advanced Approach: Domain-Specific Fine-Tuning We also explored a more sophisticated domain-specific fine-tuning method. This involved using a BERT backbone optimized with Contrastive Loss to teach the model semantic proximity—essentially ensuring "Textbook Section A" is mapped closer to "Standard Definition A" than "Standard Definition B." While promising, we encountered significant implementation hurdles and were unable to fully integrate this architecture due to competition time constraints.











Log in or sign up for Devpost to join the conversation.