-
personalized feed
Inspiration
As current college students, we felt that many students were not taking advantage of the discounts provided by their .edu email. The problem isn't the lack of discounts, its the lack of accessibility. Discounts are scattered across brand sites, campus pages, directories, and random GitHub lists, with no single place to look. Most of the deals you find are expired or not for your school. We wanted one clean feed that knows you're a student the moment you sign in with your .edu email, and shows only the deals that are relevant to you.
What it does
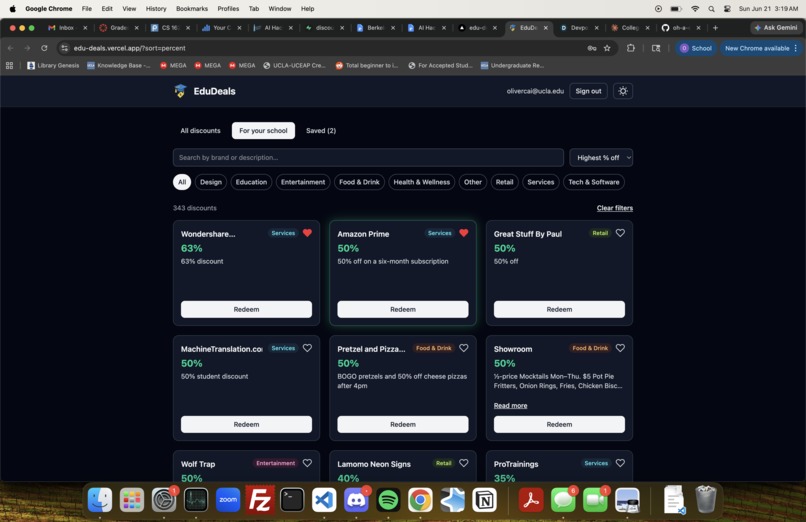
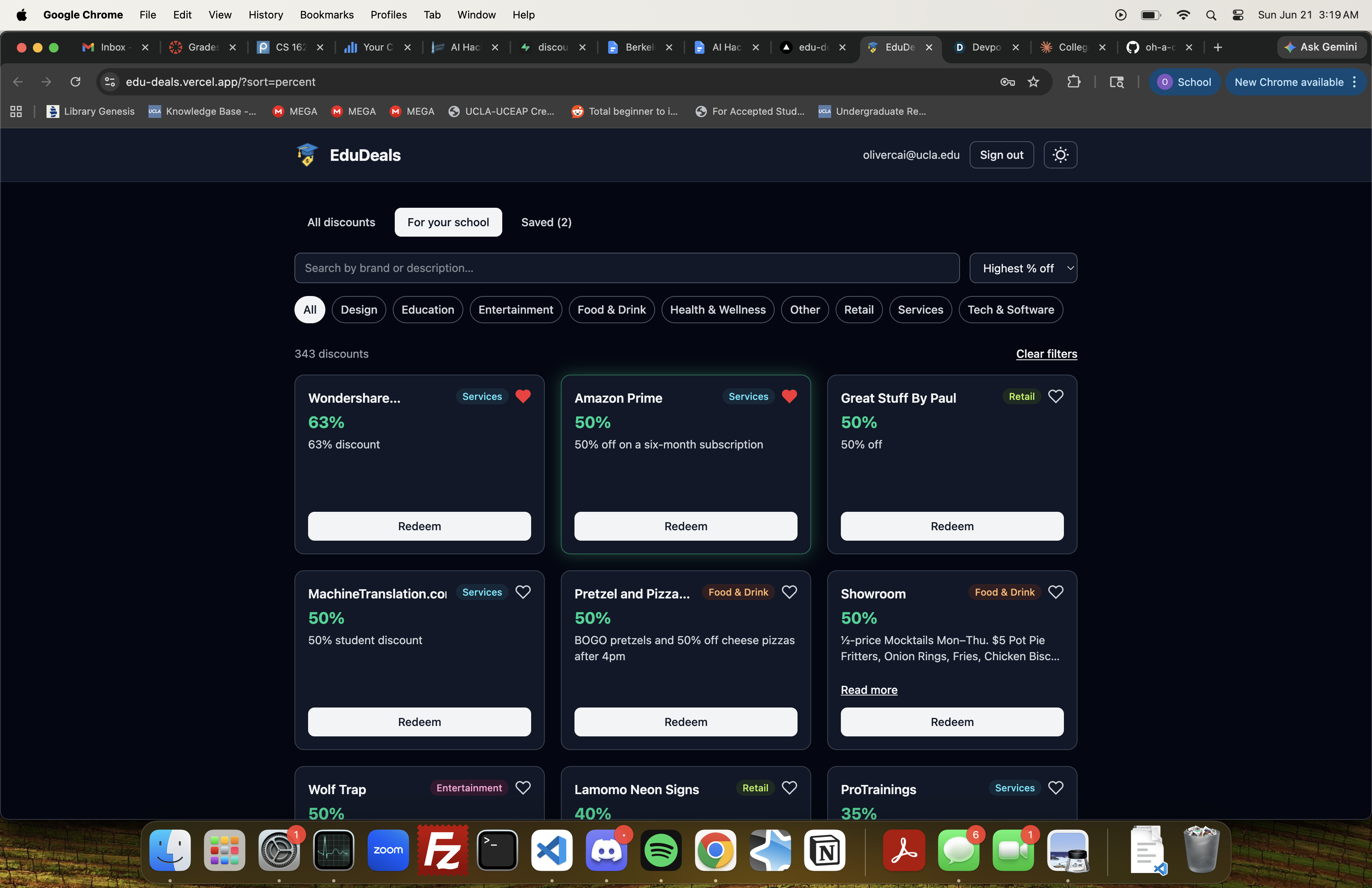
EduDeals is a searchable, filterable catalog of verified student discounts. Sign in with your .edu email to unlock a paginated grid of deals you can search by brand or description, filter by category, and sort by name, expiry, or highest % off. A "For your school" tab matches deals to your campus from your email domain, and a "Saved" tab keeps your favorites. Expired deals are hidden automatically, expiring-soon deals are flagged, and your filters live in the URL so a view is shareable. The catalog itself is kept fresh by a Python pipeline that scrapes and extracts new deals into the database on its own.
How we built it
The frontend is React 19 + TypeScript + Tailwind CSS v4, talking directly to Supabase for Postgres storage and email/password auth — no backend of our own. Discounts are populated by a standalone Python pipeline: httpx + BeautifulSoup fetch campus and city deal pages, Google Gemini extracts structured deals from messy HTML in one batched call, clean GitHub markdown lists are parsed deterministically with regex, and everything is upserted into Postgres via psycopg using ON CONFLICT (redemption_url) so re-runs update existing rows instead of duplicating.
Challenges we ran into
- Messy, inconsistent school data. The
schoolfield comes in as display names ("UC San Diego"), bare domains ("chapman.edu"), and the keyword "all" — matching a user's email domain to the right deals needed a normalization heuristic rather than an exact lookup. - Deduping without losing real deals. The same brand legitimately appears on multiple campuses; we key dedup on normalized brand + host so the same listing scraped twice on one site collapses, but the same brand across different campuses doesn't.
- LLM cost and reliability. Sending every page in full to Gemini was wasteful, so we route only messy HTML to the LLM and parse clean, structured markdown deterministically instead.
Accomplishments that we're proud of
A self-updating catalog built with the scraper means the deal list isn't hand-maintained, which is paired with personalized per-school feeds, shareable URL state, persistent dark mode, and a uniform card grid that adapts cleanly no matter how long a deal's description is. And a data pipeline that mixes LLM extraction with deterministic parsing to keep both speed and accuracy.
What we learned
How to combine an LLM with deterministic parsing so each approach does what it's best at, how to design dedup/upsert logic that's idempotent across re-runs, and how much of building a real product is taming inconsistent data rather than writing features. On the frontend, we got a lot more comfortable with React state that needs to stay in sync with the URL and localStorage at the same time.
What's next for EduDeals
- A proper domain → school mapping (or a user-set school) so display-name campuses match correctly.
- Scheduling the scraper (cron/serverless) so the catalog refreshes automatically.
- One-click copy for promo codes, deal ratings/verification by students, and expiry notifications.
- Broadening sources beyond the initial California campuses.
Built With
- python
- react
- supabase
- typescript
- vercel
- vite

Log in or sign up for Devpost to join the conversation.