-

Cover Banner
-
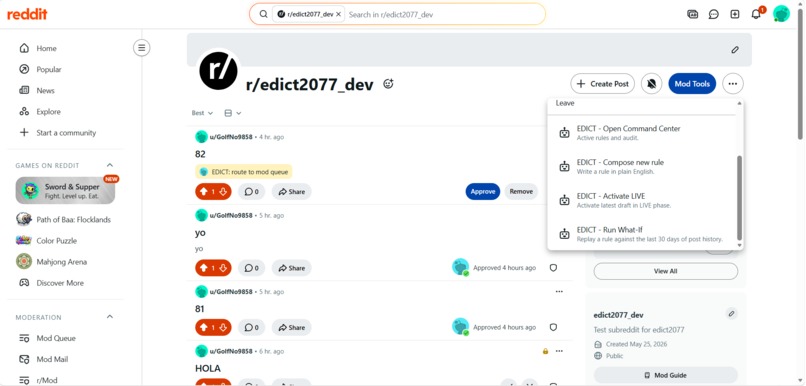
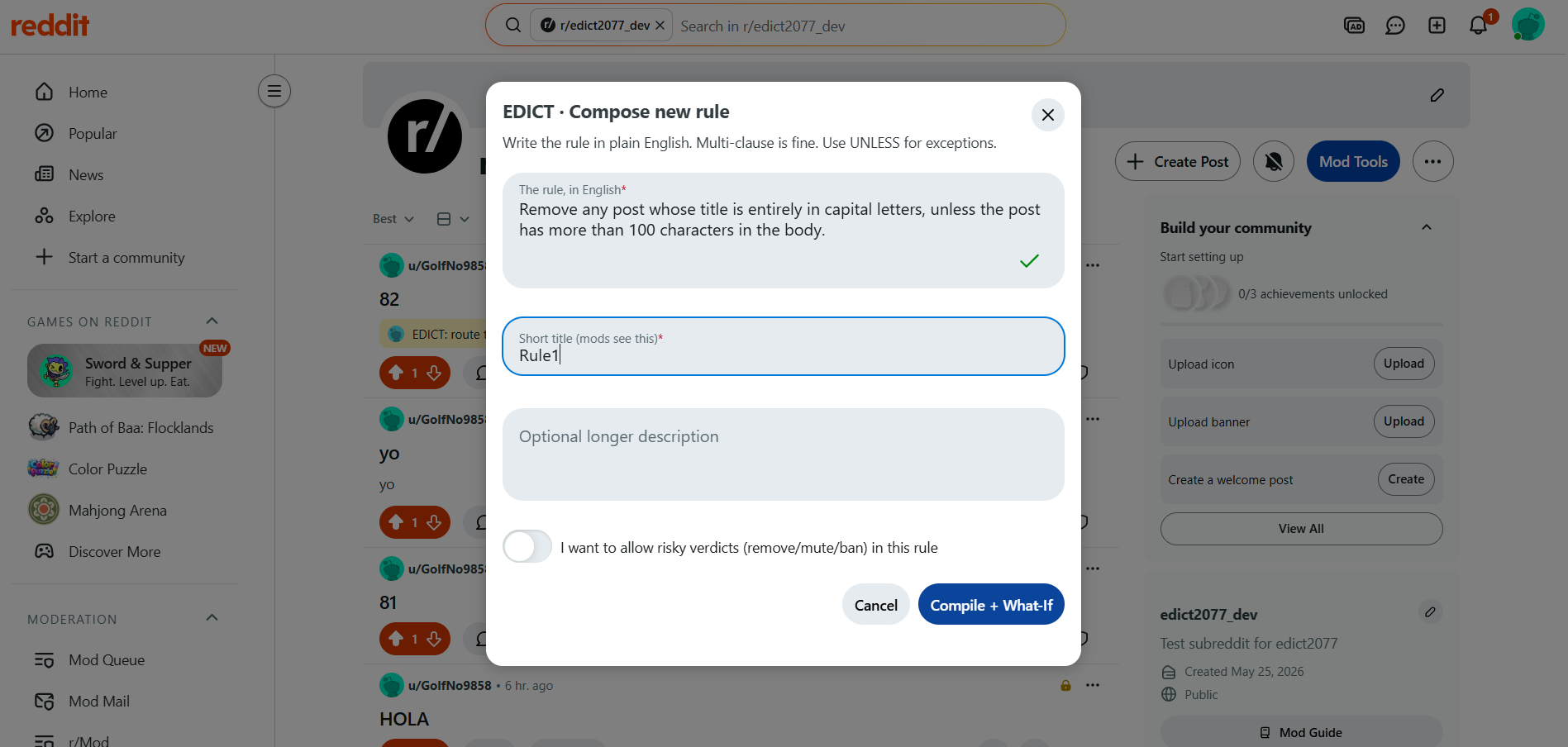
Compose Rule
-
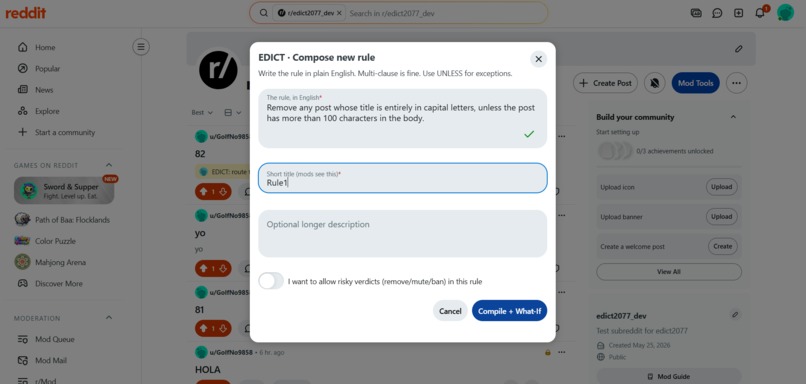
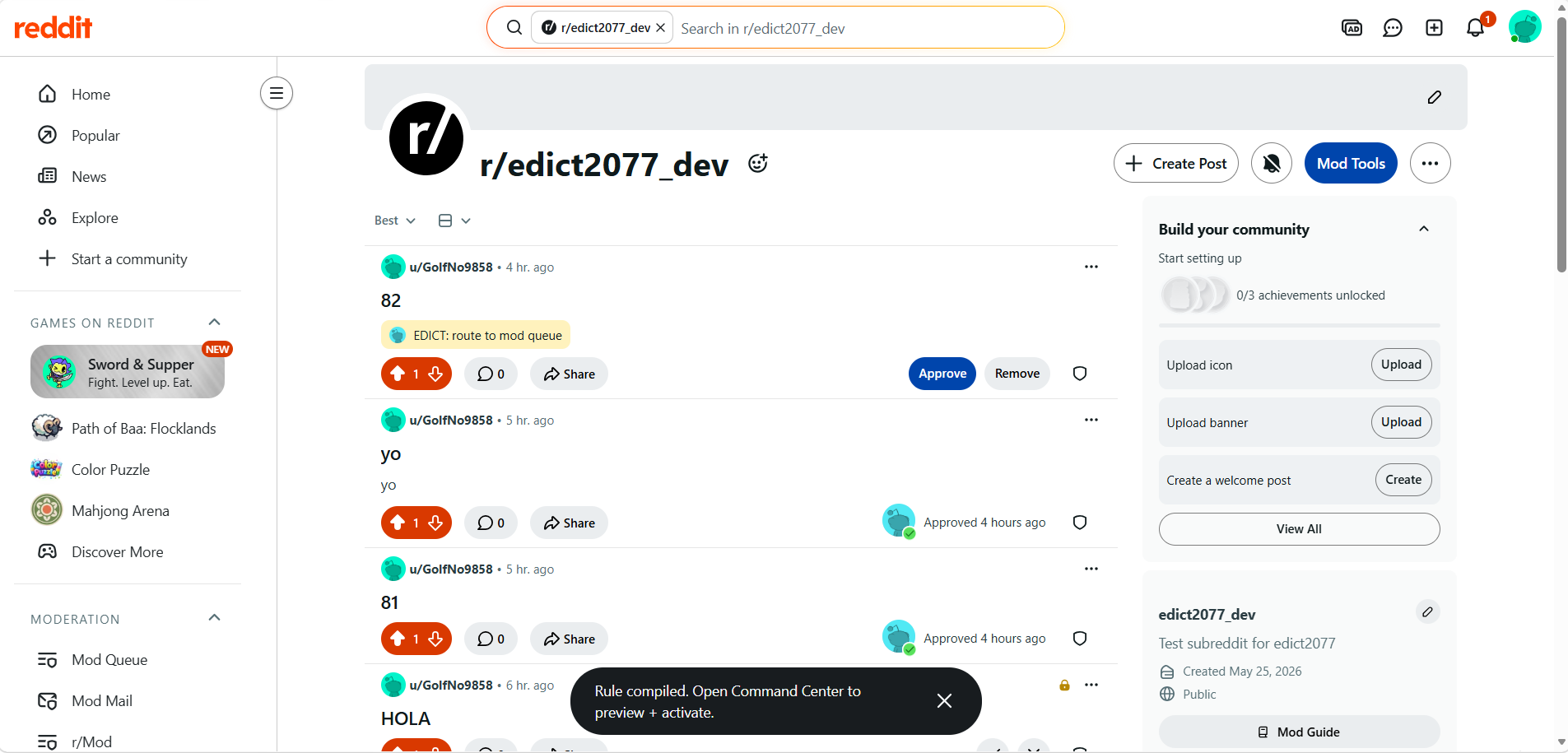
Compiling Rule1
-
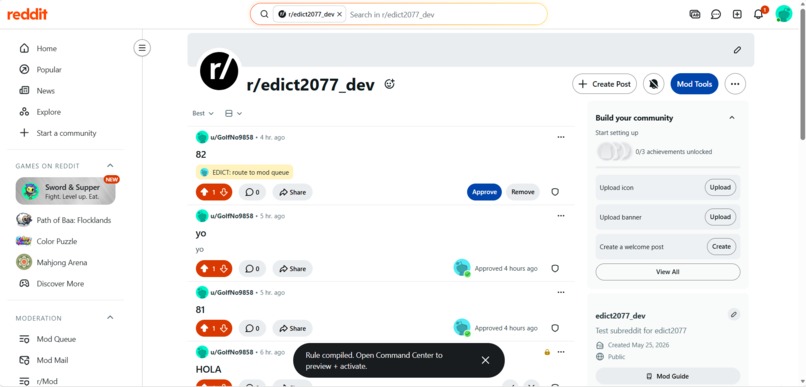
Rule Compiled Toast
-
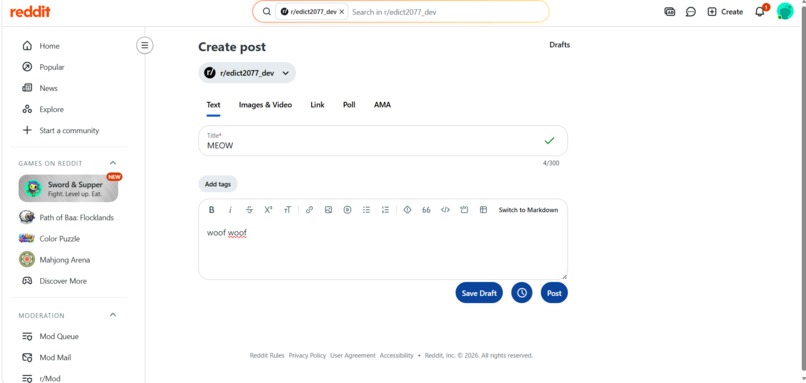
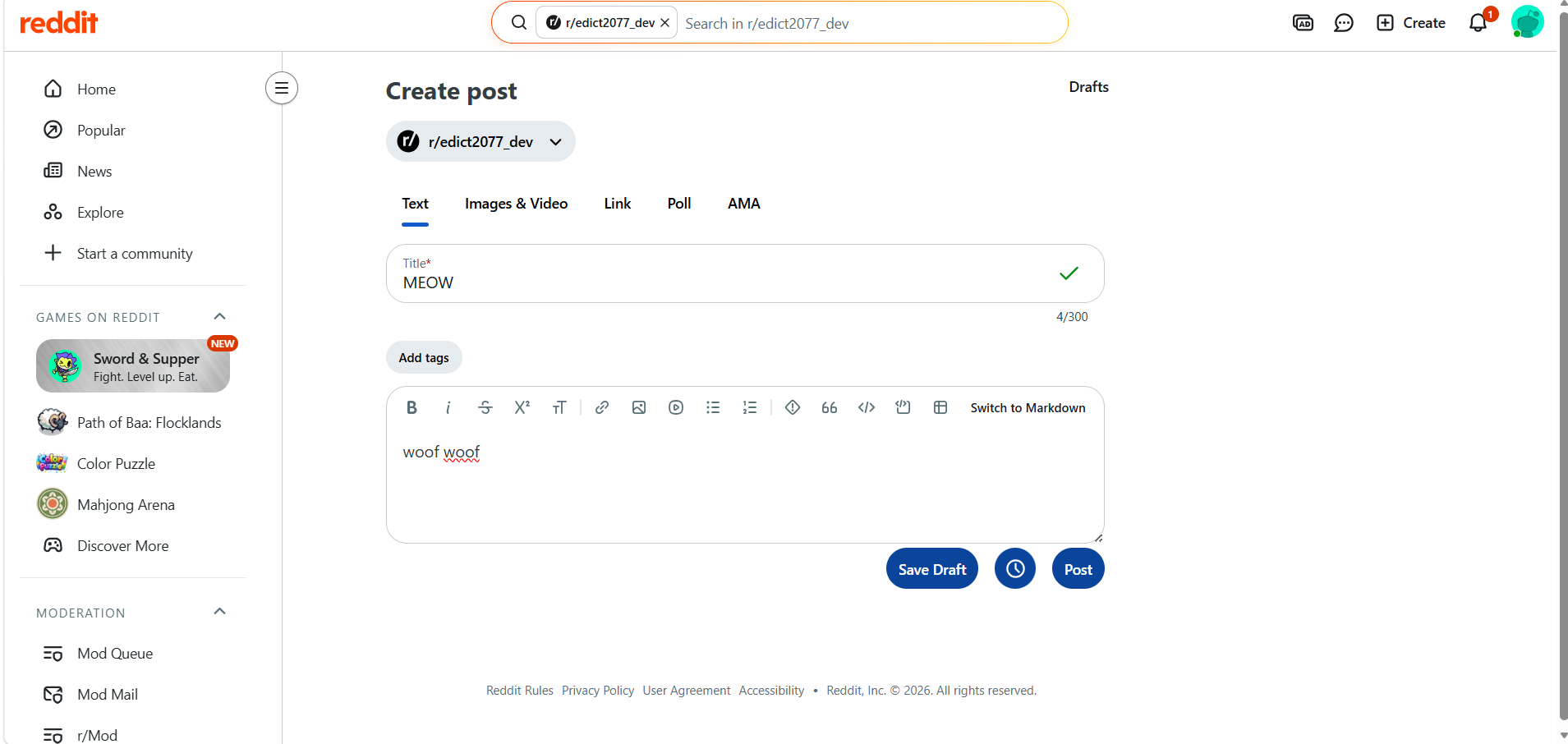
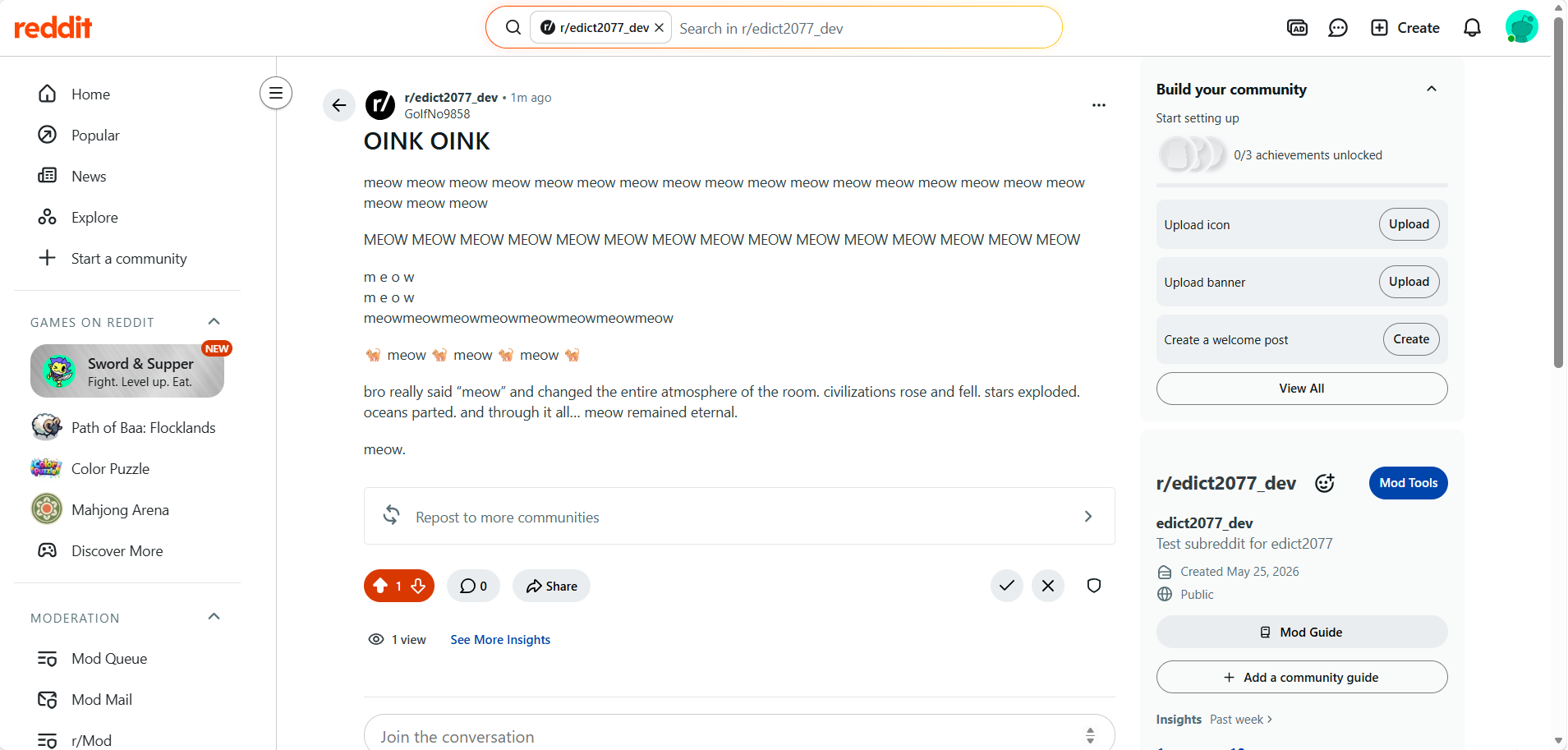
Post will trigger our Rule1
-
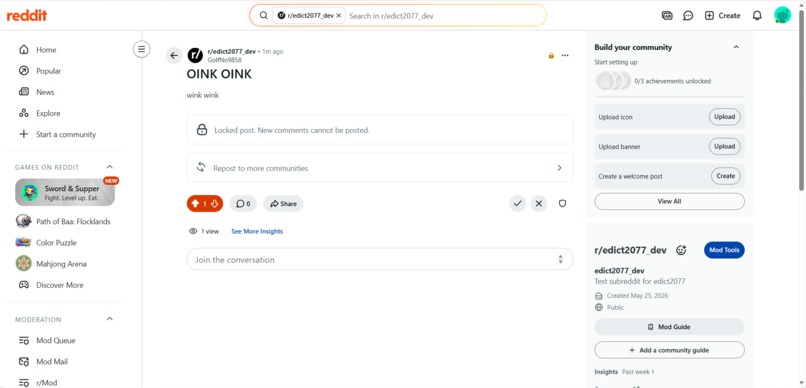
The first post fired because its title was entirely uppercase and the body was short.
-
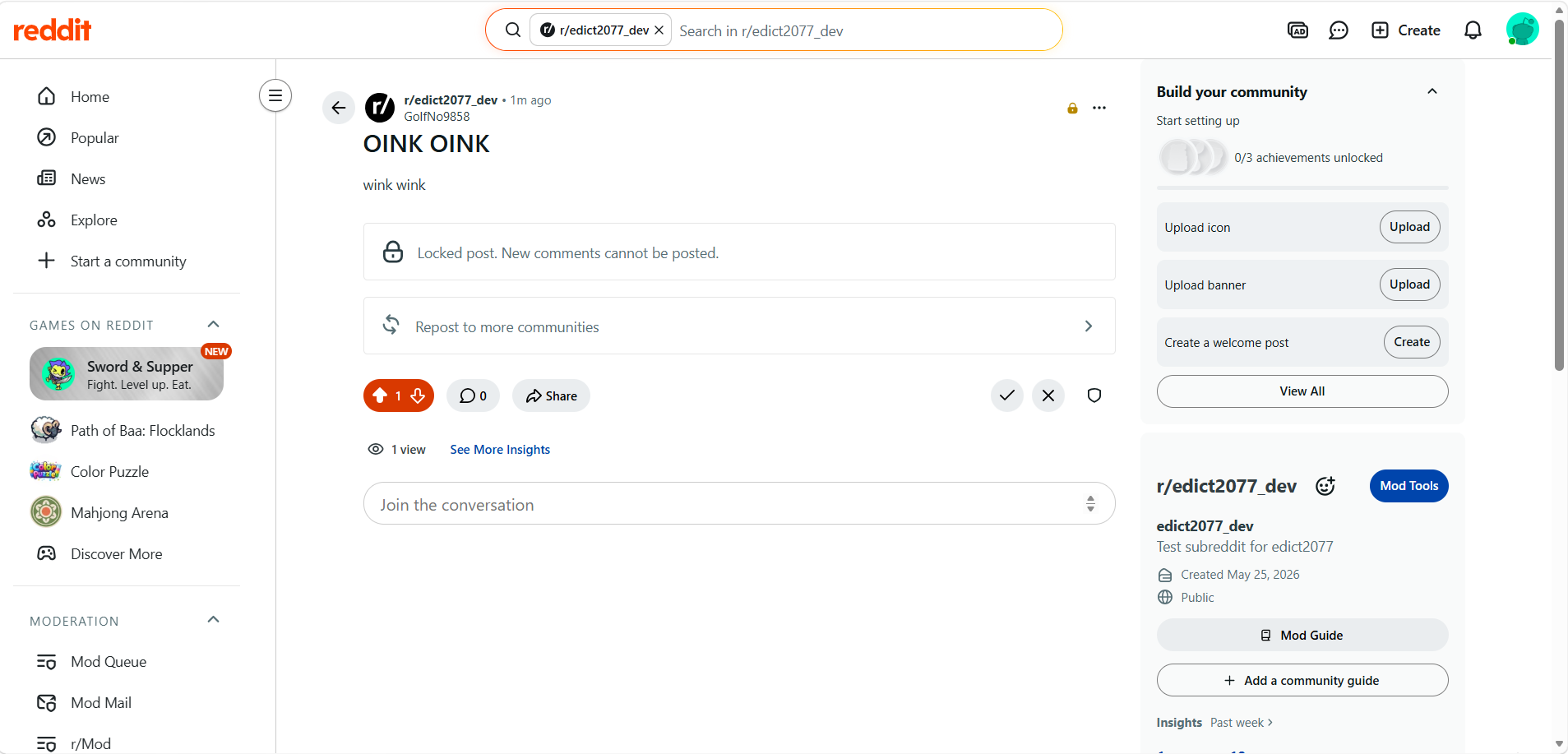
Post Locked
-
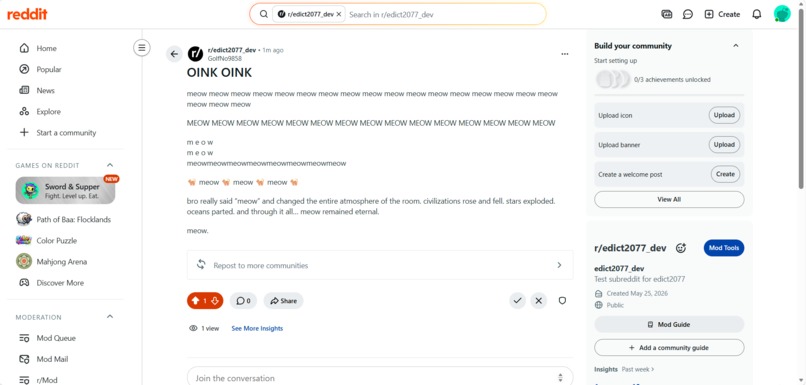
Post wont trigger Rule1
-
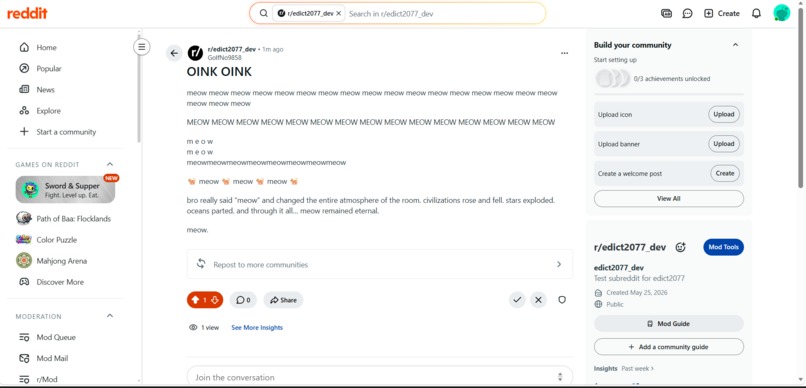
The second post matched the uppercase condition, but the UNLESS bodyLength > 100 exception negated the rule, so no action was taken.
-
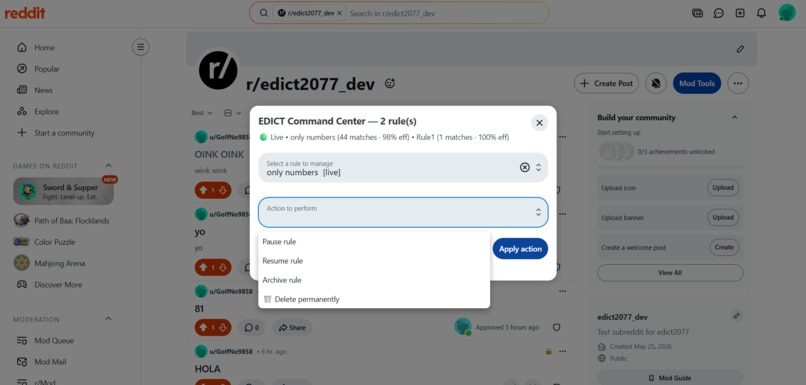
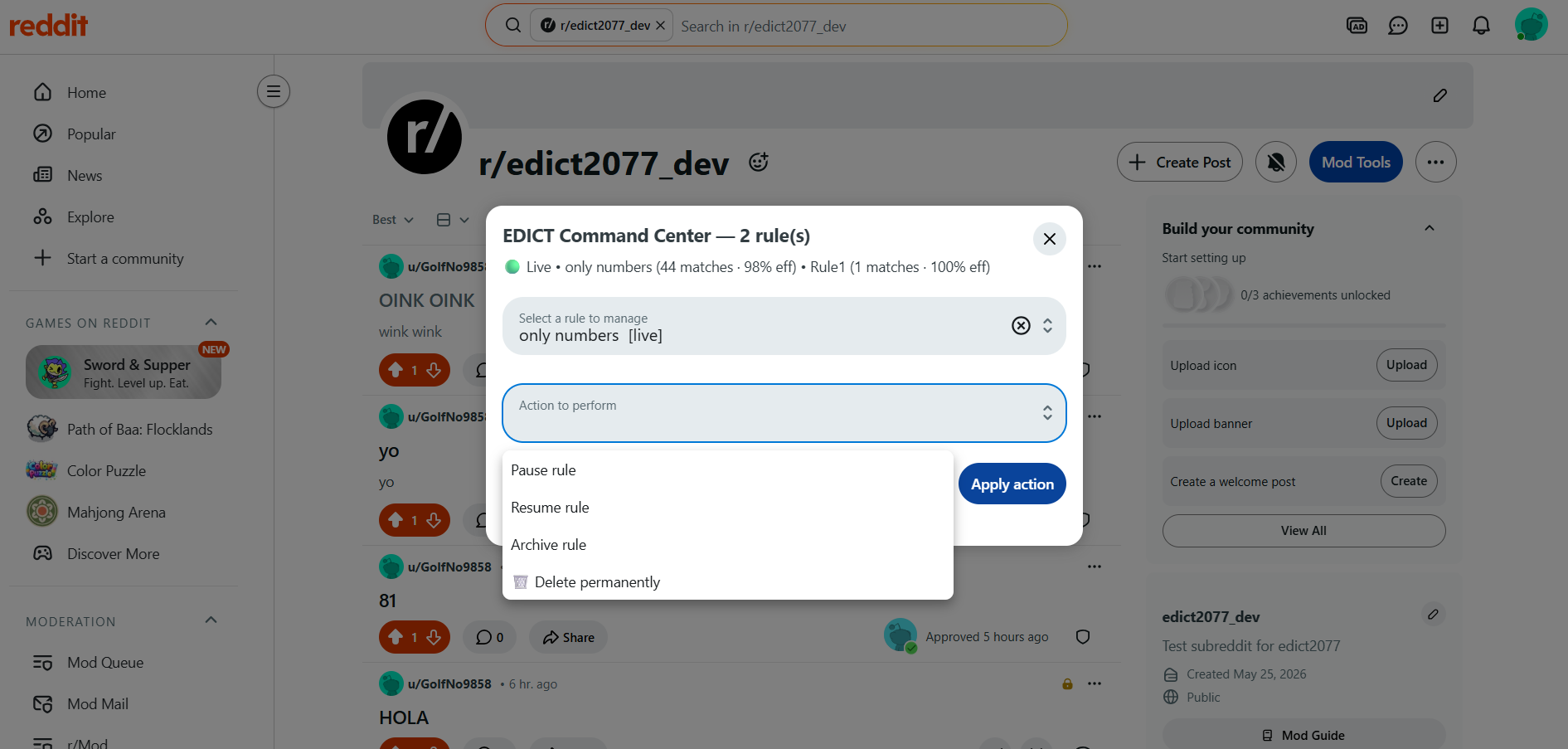
Command Centre Options
-
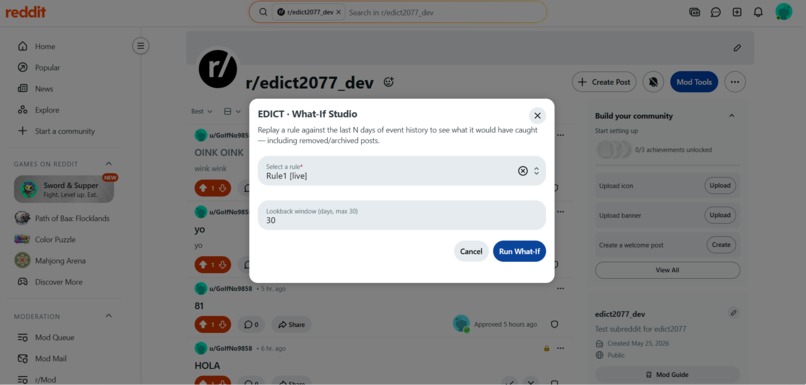
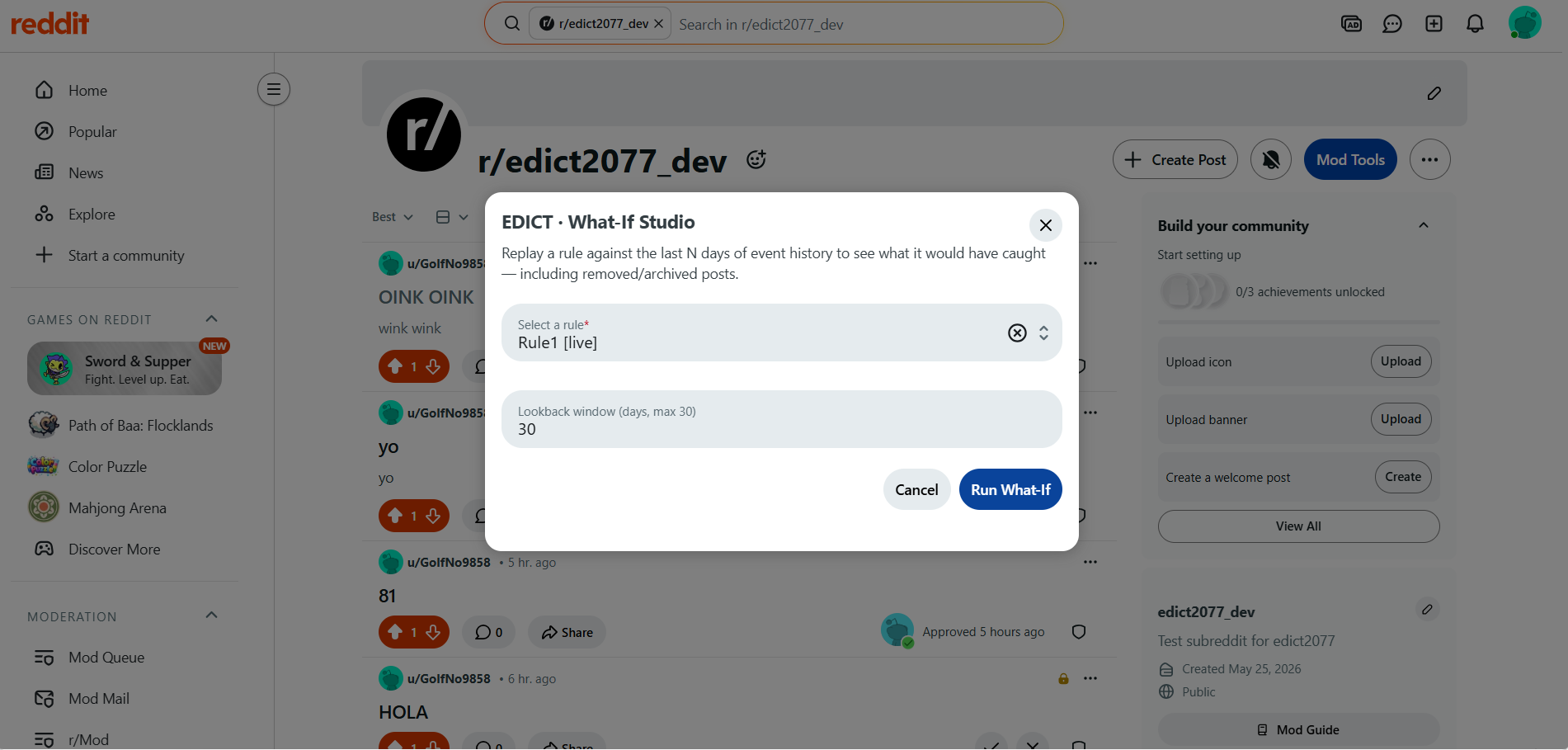
What-IF Studio
-
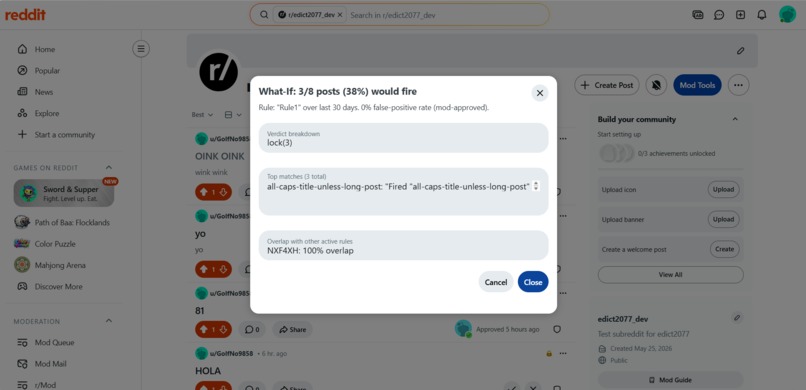
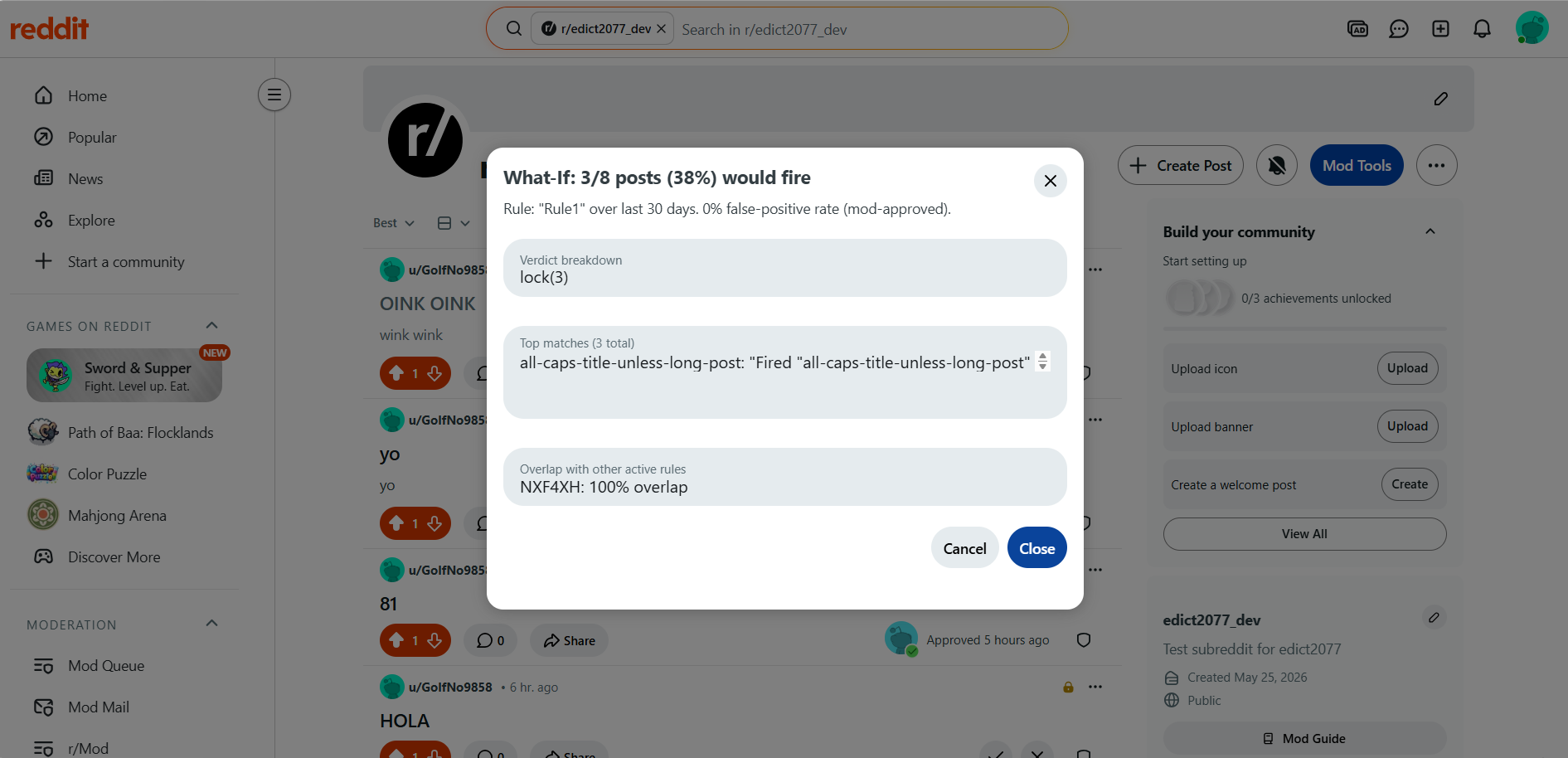
What-If Results

What inspired EDICT
Reddit moderators are unpaid volunteers managing communities that can grow to millions of members overnight. The tools available to them — AutoModerator's YAML syntax, manual queue review, third-party bots with opaque logic — were designed for a different era of the platform. The gap between "what a moderator wants to enforce" and "what they can actually configure" is enormous.
The specific frustration that drove EDICT: a moderator who wants to say "send to mod queue any post under 50 characters from new accounts, unless the author is established" has to translate that into YAML conditions, test it blind, and hope it doesn't fire on something it shouldn't. There is no preview against real history. There is no explanation when it fires. There is no undo.
EDICT started from one question: what if the gap between intent and enforcement was just a sentence?
What we built
EDICT is a compiled moderation rule engine. A moderator writes a rule in plain English. EDICT compiles it into a deterministic condition tree — supporting multi-clause logic with AND, OR, NOT, and UNLESS exceptions. The compiled rule is validated against a strict schema, then runs in adaptive shadow mode before it ever takes a live action.
The architecture has one core principle: the AI runs once, at rule-write time, and never again. Every post evaluation after that is pure TypeScript — deterministic, free, and fully traceable. The same post always gets the same verdict.
Key components built from scratch:
Combinator algebra. Each rule clause compiles to a tree of AND/OR/NOT nodes over atomic fact comparisons. The evaluator walks the tree with short-circuit semantics and emits a per-atom trace on every match. Adding a new fact means adding one evaluator function — nothing else changes.
Adaptive shadow promotion. Rather than a fixed timer, EDICT uses a Bayesian confidence model:
$$\text{posterior} = \frac{\text{positives} + 1}{\text{observations} + 2}$$
A rule promotes when its posterior confidence exceeds a configurable threshold (default 0.92) with sufficient observations. A rule with a high reversal rate never promotes automatically — it surfaces for human review. This is the difference between "waited long enough" and "earned the right to act."
What-If Studio. Every ActionTaken and ShadowDecisionRecorded event stores the full fact-bag snapshot at evaluation time. The Studio replays a draft rule against these persisted snapshots — including removed posts and archived content that no longer exists on Reddit. A current-state preview can only see what is still visible. The Studio sees everything that happened.
Six-layer safety model. Schema validation, adaptive shadow, per-rule and subreddit-wide circuit breakers, undo-learning deflection (patterns reversed three times get re-routed automatically), consensus voting for high-impact verdicts, and 30-day rollback tokens. Each layer is independent — a failure in one does not compromise the others.
Event sourcing. Every state change is an immutable event appended to a per-subreddit event log. Aggregates and read models are projections of the log. This gives time-travel queries, complete audit history, and the ability to rebuild any projection from scratch if it drifts.
What we learned
Building on Devvit taught us how much engineering depth is possible within a serverless Reddit app. The platform's Redis, trigger system, and scheduler gave us everything needed to build a production-grade event-sourced system — persistent event log, incremental projections, background compaction, scheduled shadow promotion sweeps — all running inside a single Devvit app with no external infrastructure.
Working with LLM function-calling at the schema boundary taught us to treat model output as untrusted data. Zod validation after every model response, coercion for type inconsistencies, and graceful fallback paths for malformed output made the compiler robust across both OpenAI and Gemini without changing the domain logic.
Event sourcing paid off immediately in testing. Every test that exercises a rule lifecycle hands an event log to replay() and asserts on the resulting aggregate. No mocks, no fixtures, no setUp/tearDown. The 185-test suite runs in under 3 seconds entirely in-process.
Challenges
Devvit's interactive surface. Building a rich dashboard within Devvit's form API required creative use of form fields for display — titles carry the headline numbers, descriptions carry the summary, and fields carry the detail rows. Every display decision was made with the constraint that form descriptions collapse whitespace. The result is a Command Center that works entirely through the mod menu with no custom post required.
LLM output consistency across providers. OpenAI and Gemini have different function-calling behaviors. Gemini's structured output required provider-specific parameter schemas (OpenAPI subset rather than full JSON Schema), coercion for numeric values returned as strings, and a JSON-mode fallback for edge cases. All of this is handled transparently — moderators select their provider in settings and the compiler adapts.
Tuning the adaptive shadow algorithm. The Laplace smoothing formula is straightforward. The interaction between the confidence threshold, minimum observations, and reversal rate cap required careful calibration to avoid both premature promotion (a rule that saw ten posts and got lucky) and indefinite shadow (a rule that is genuinely good but sees low traffic). The defaults — 25 observations, 0.92 threshold, 25% reversal cap — were validated against synthetic event streams before shipping.
What's next
The six-tab Command Center dashboard exists as fully implemented Blocks components — Rules, Effectiveness, Audit, Briefing, Conflicts, Suggestions — and is ready to ship as a custom post once the web-view build pipeline is wired up. That is the highest-priority next step.
The suggestion engine mines audit history for removal patterns and proposes new rules based on a moderator's own enforcement history. The conflict detector scans every compile for overlap, contradiction, and shadowing between rules. Both are implemented, tested, and running in the background — surfacing them in a richer UI is the next milestone.
Built With
- api
- cqrs
- devvit
- gemini
- openai
- redis
- typescript
- vitest
- zod

Log in or sign up for Devpost to join the conversation.