-
-
Home
-

About
-
Equation Checker and Solver
-
Essay Reviewer and Grader
-

Plagiarism Detector
-
FAQ and Team
-
Contact Us
Inspiration
As high school students, we have had to transition from in person learning to virtual learning, and we know how hard it can be for students to communicate with teachers to get the help they need. Students can no longer walk into classrooms and ask their teachers for help specific to their needs. Teachers also have to cater to all their students over online calls in a limited amount of time, so each student does not get the attention they deserve. Assignments that students submit online cannot be graded properly and gone over with students. Thus, we created EdHance. EdHance takes various aspects of learning, which have been affected by virtual learning and helps students receive the help they need in certain areas using machine learning. We mainly focus on math problems, essays, and making sure work is not plagiarized.
What it does
Our Project has three core features. The first is our equation checker and solver, the second is an essay reviewer and scorer, and our third feature is a plagiarism detector. All three features utilize machine learning.
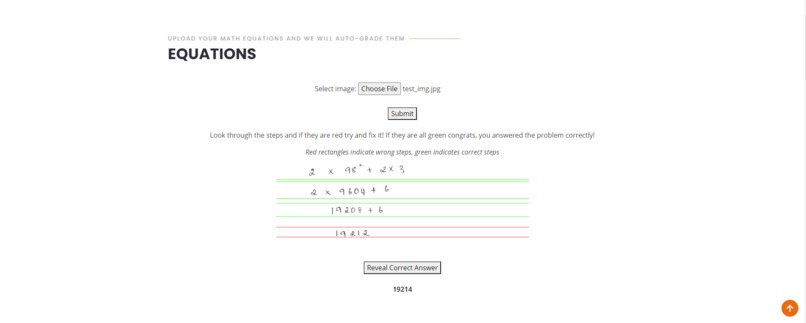
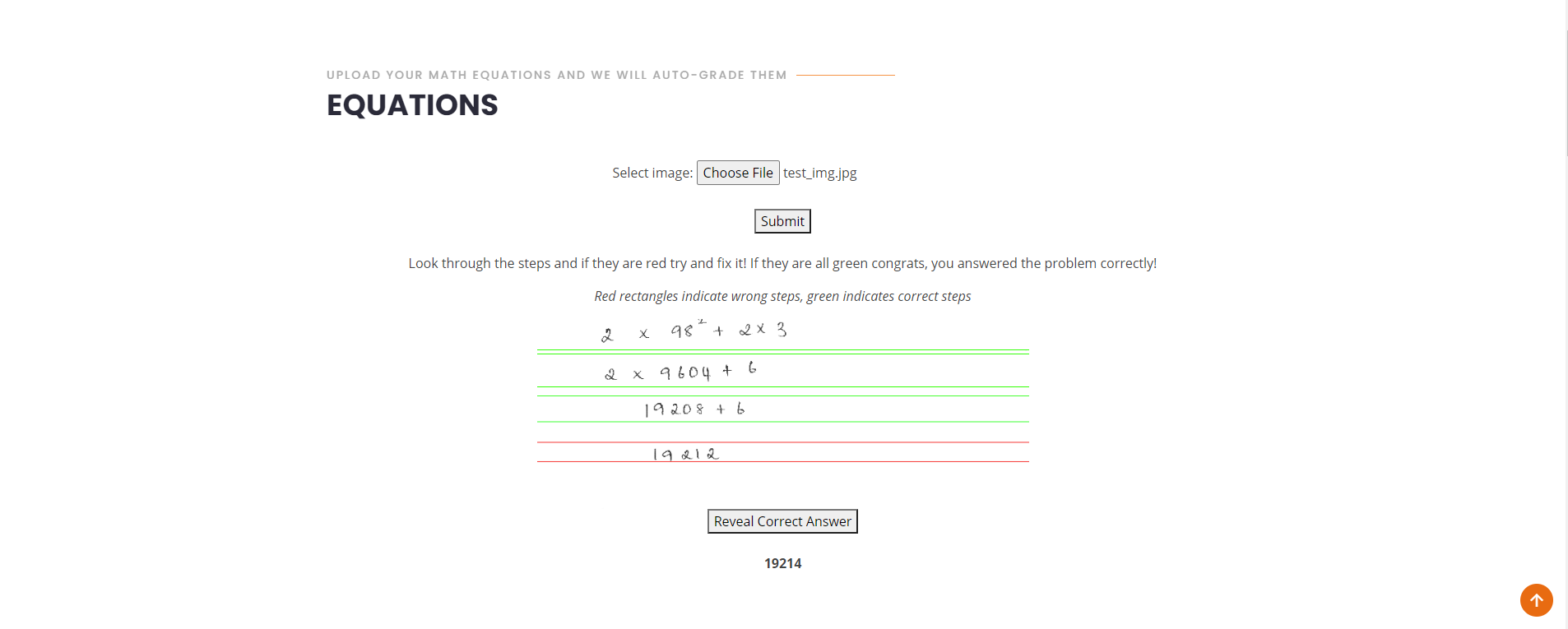
The equation checker and solver is meant for math problems and users can upload a picture of their work. Our model, built with OpenCV and a Convolutional Neural Network(CNN), will then produce the picture as an output, segmented with green boxes around lines that are correct, and red lines that are wrong. When submitting work, make sure that you are working vertically. Not only does our model find your wrong work, it also has a function where you can see the correct answer after clicking a button to reveal it. The correct answer will be hidden unless the user hits the button.
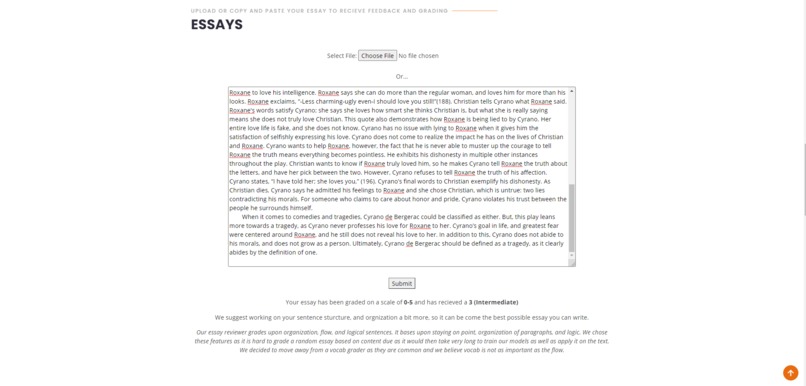
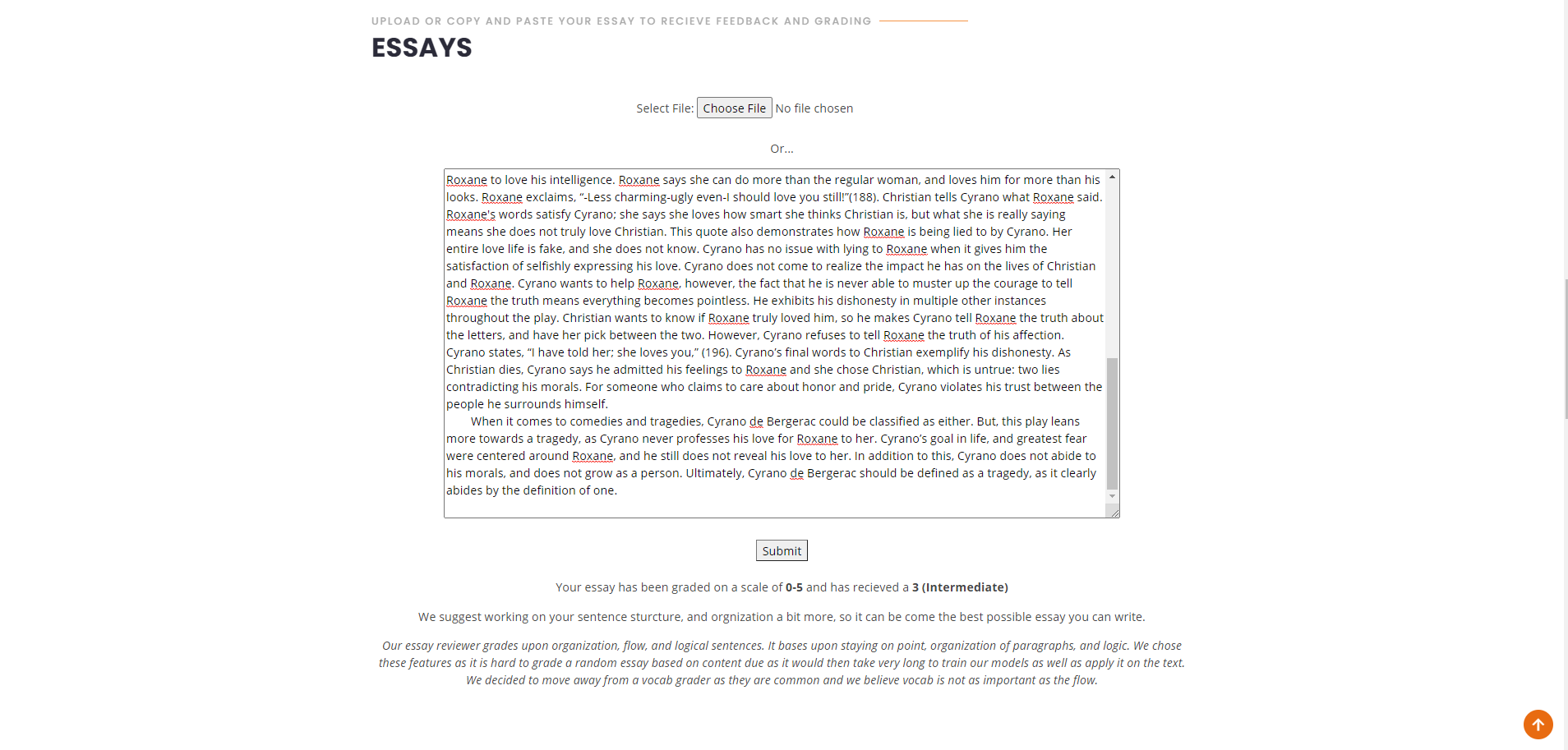
Next, we have our essay reviewer and grader. The essay reviewer and grader, built with Natural Language Processing concepts and tools, is based upon the user’s essay organization, workflow, logic, and relevancy. Users can either upload a file of their essay, or copy and paste the text and our model will give it a score on a scale of 0-5, 5 being the highest. After you submit your work, we will give the essay a score based on the features stated above, and it will also give personalized feedback based on your score on how to improve. We trained our model on thousands of essays that were webscrapped,which all had a variety of scoring between 0-5. Our model grades on organization, flow, logic, and relevance because we believe that grading based on a user’s vocab won’t represent the grade they will get from their teacher well. There are also numerous grammar checkers already, so we decided to make something new and innovative.
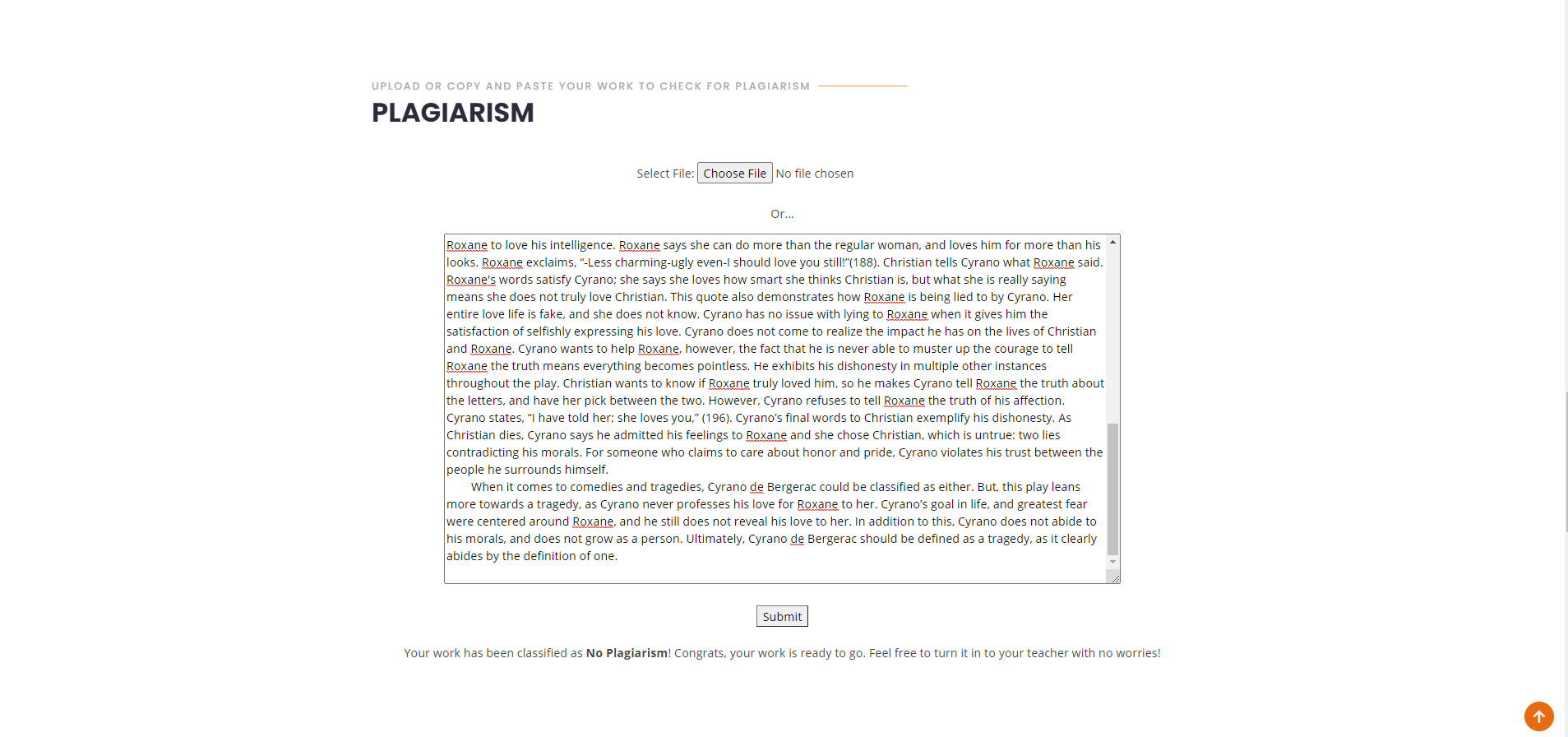
Lastly, we have a plagiarism detector. With an online environment, many students have become demotivated to work, and plagiarism happens often. To combat this issue we created this feature, which can be used by both students and teachers. Students or teachers can either upload a file of one’s work, or copy and paste the text into the box. Teachers can use it to save time to check through their students' work for plagiarism, and students can make sure they aren’t plagiarizing if they are incorporating other people’s ideas, before they turn their work in. The Naive Bayes Classifier will return either “no plagiarism” “little plagiarism” “some plagiarism” “much plagiarism”. Depending on the model’s output, user’s will receive personalized feedback on what to do from there.
How we built it
Our website was built with four main languages. HTML, CSS, and JS for our frontend, and JS and Python for our backend and model development. For the ML we used OpenCV, a Convolutional Neural Network(CNN), and Natural Language Processing features.
Our equation checker and solver was created using OpenCV and a CNN. We used a CNN to distinguish numerics, mathematical operations, and exponents. We got our data for this on Kaggle. We used OpenCV to distinguish when the user finishes a step and goes down to the next line to work on the next step. We also used OpenCV to differentiate exponents from normal numbers. We created a line and if the number started above it then it would be classified as an exponent. From here we are able to use math to evaluate whether or not each step is correct. If the step is correct, we highlight it in green, and if it’s wrong we highlight it red. We also have a feature where the user can reveal the correct answer for their equation. We are able to do this by using the first step in the user’s work and calculating the correct answer from there.
The Essay grader reviews and grades essays on a scale of 0-5(5 is the best score) based on organization, workflow, logic, and relevancy. We found data on thousands of essays from Kaggle and web scraped data from Medium. We are able to calculate organization and staying on target using cosine similarity and comparing paragraphs to give us a score. We found vector values from our Word2Vec model based on sentences within a paragraph. We do this for every paragraph of the essay and calculate a score for the user’s essay’s relevancy and staying focused on the topic. We combine this with our cosine similarity score to get a final grade for the students. Based on the score, we give them personalized feedback on how to improve.
Lastly, we use a Naive Bayes Classifier in order to compare the users input to our data of hundreds of different text responses. Before running the text on the model much data cleaning needs to be done. For both the input text and our data we had to remove all punctuation and words that provide no value such as “if” or “and”. The model will return a value from 0-4(4 being the most plagiarized. and each number corresponds with one of the following: “no plagiarism” “little plagiarism” “some plagiarism” “much plagiarism
We used flask for all of our features to take the users inputs and run them through the model, returning the output on the website. For the equation solver it was a bit different. We downloaded the image locally when a user inputs it, and then from there run it through the model, and display the final image on the website.
Challenges we ran into
Finding data for our essay reviewer was hard. However, after much research we were able to find a dataset from Kaggle and webscraped essays from Medium. However, we still had to do data cleaning to make it usable for the model. Working with NLP features was also hard. This was our first time and we ran into many issues trying to create the essay reviewer.
What we learned
We learned very much about Natural Language Processing. None of us had ever used it before, and making the essay grader was a daunting task. We also strengthened our skills with CNNs and OpenCV to create our equation checker and solver.
What's next for EdHance
In the future we plan on adding more features to our essay grader so that it includes vocabulary, content, and grammar on top of our already existing features. This will give users a holistic score so they don’t have to go to multiple places. We also plan on adding more features to the equation checker and solver such as trigonometric functions. We also want to find more data to add to our plagiarism detector so it can be more widespread.
Built With
- convolutional-neural-network
- css
- html
- javascript
- jupyter-notebook
- naive-bayes-classifier
- natural-language-processing
- opencv
- php
- python









Log in or sign up for Devpost to join the conversation.