-
-

Raspberry Pi Edge Device
-
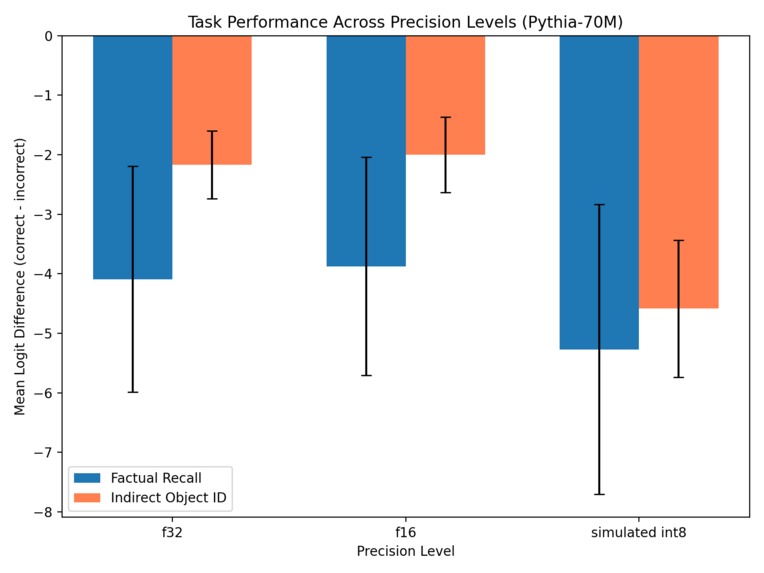
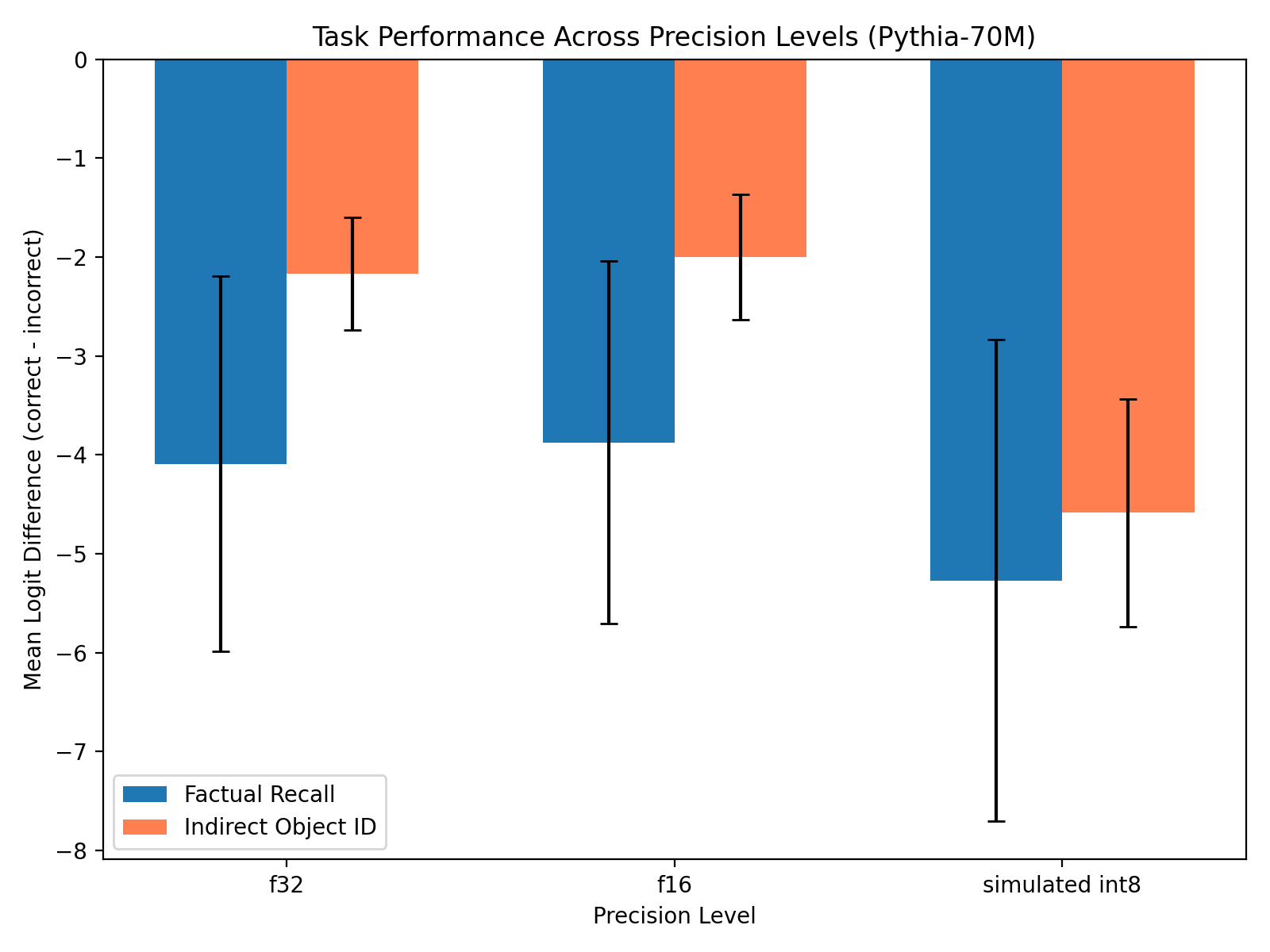
Task Degradation by Precision
-
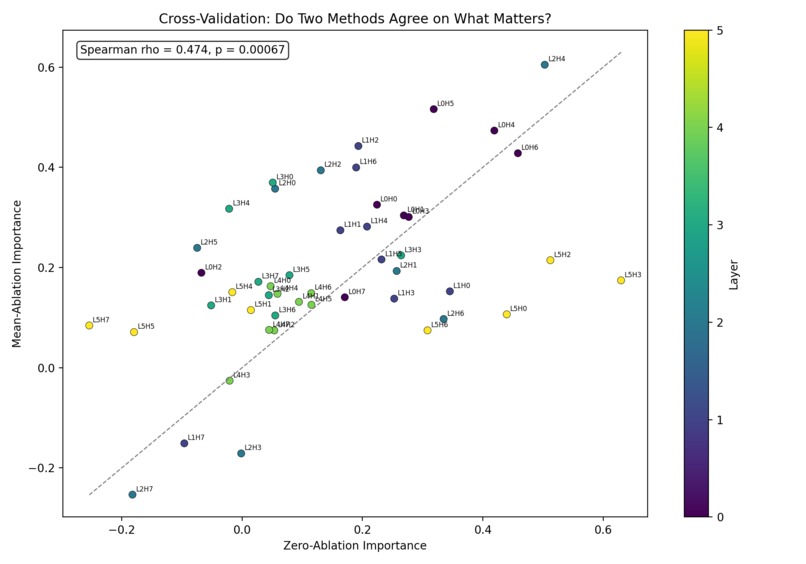
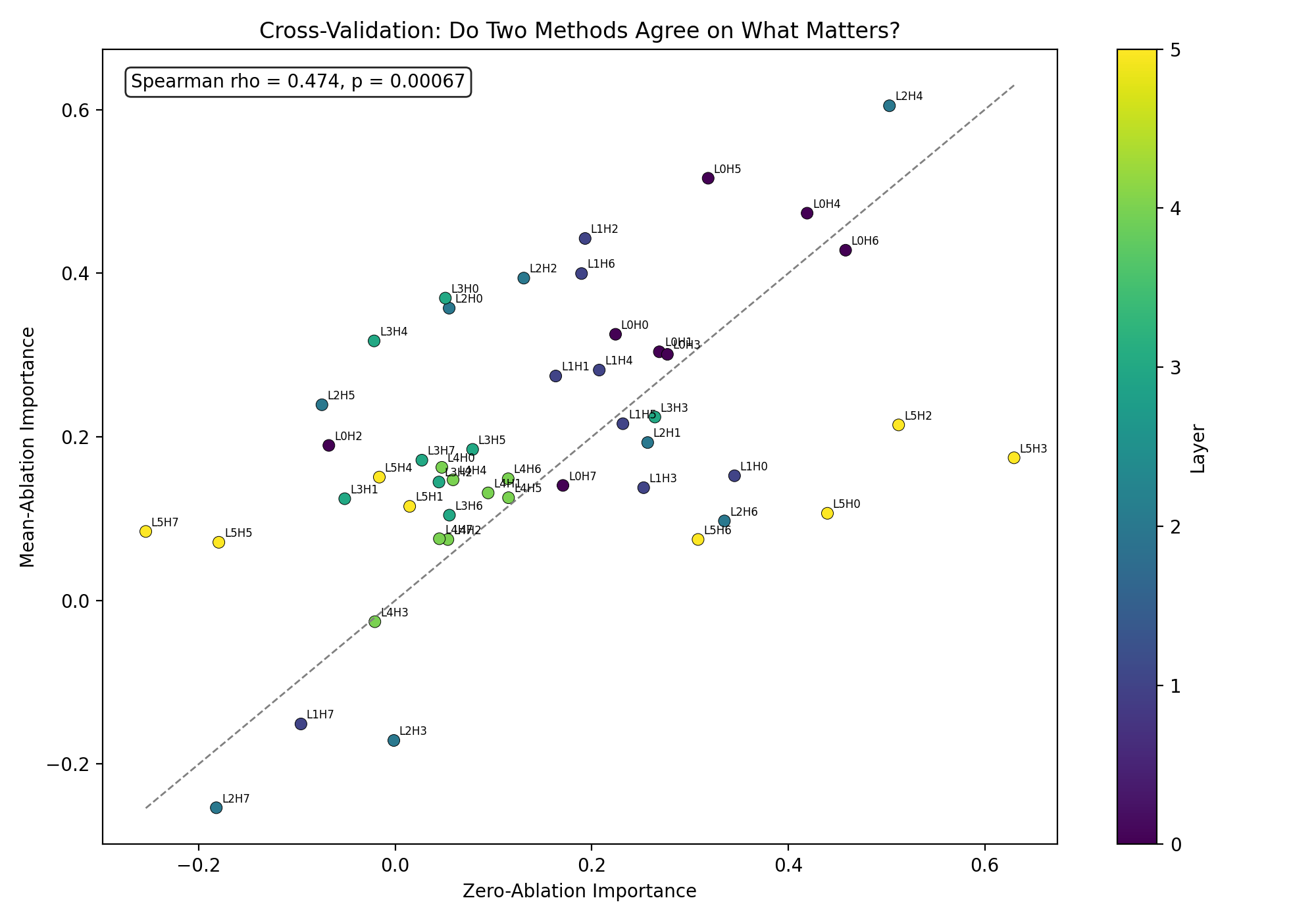
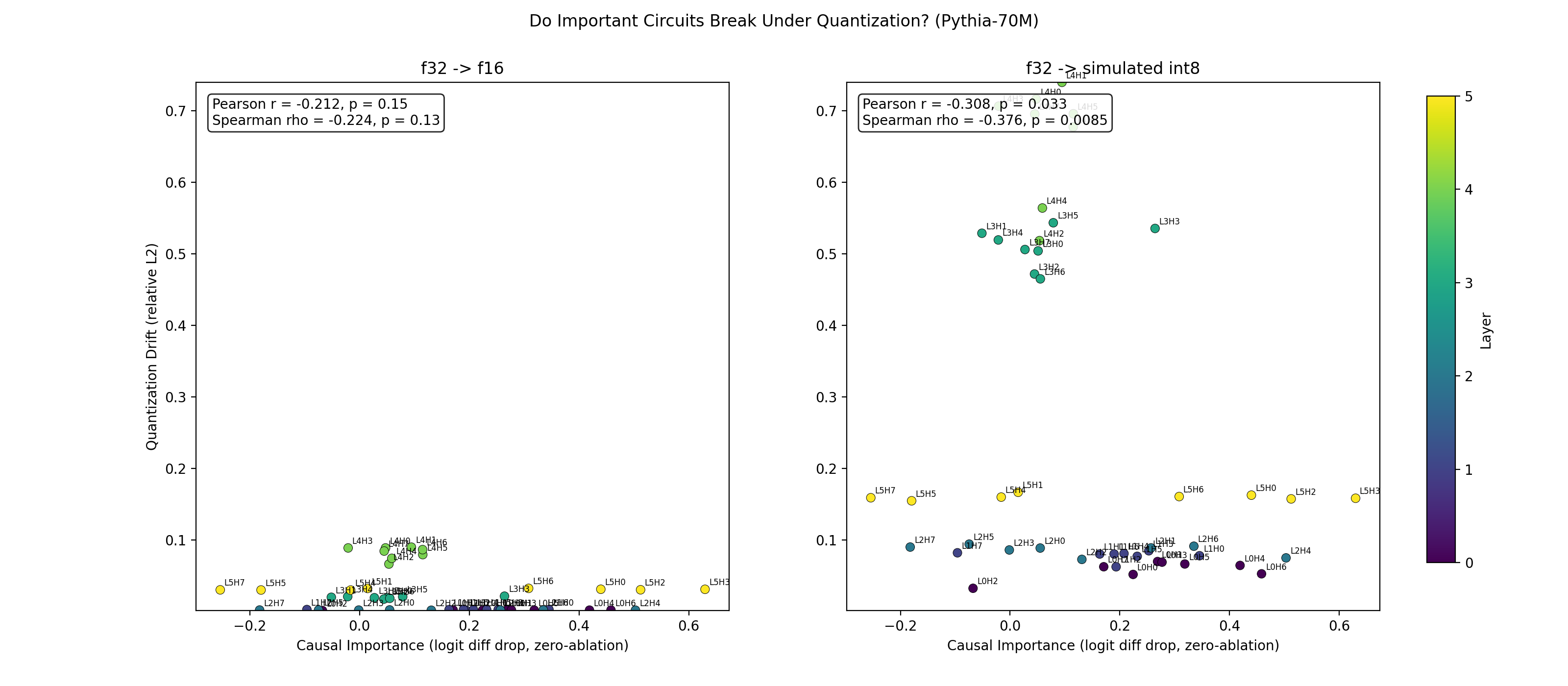
Zero vs Mean Ablation
-
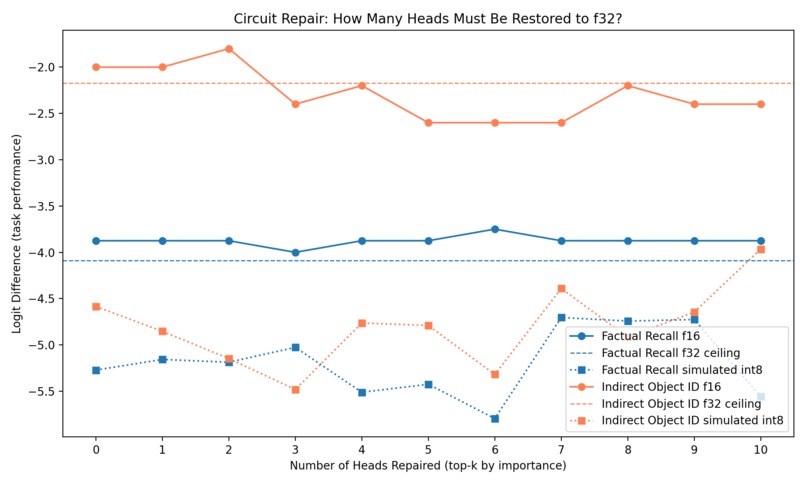
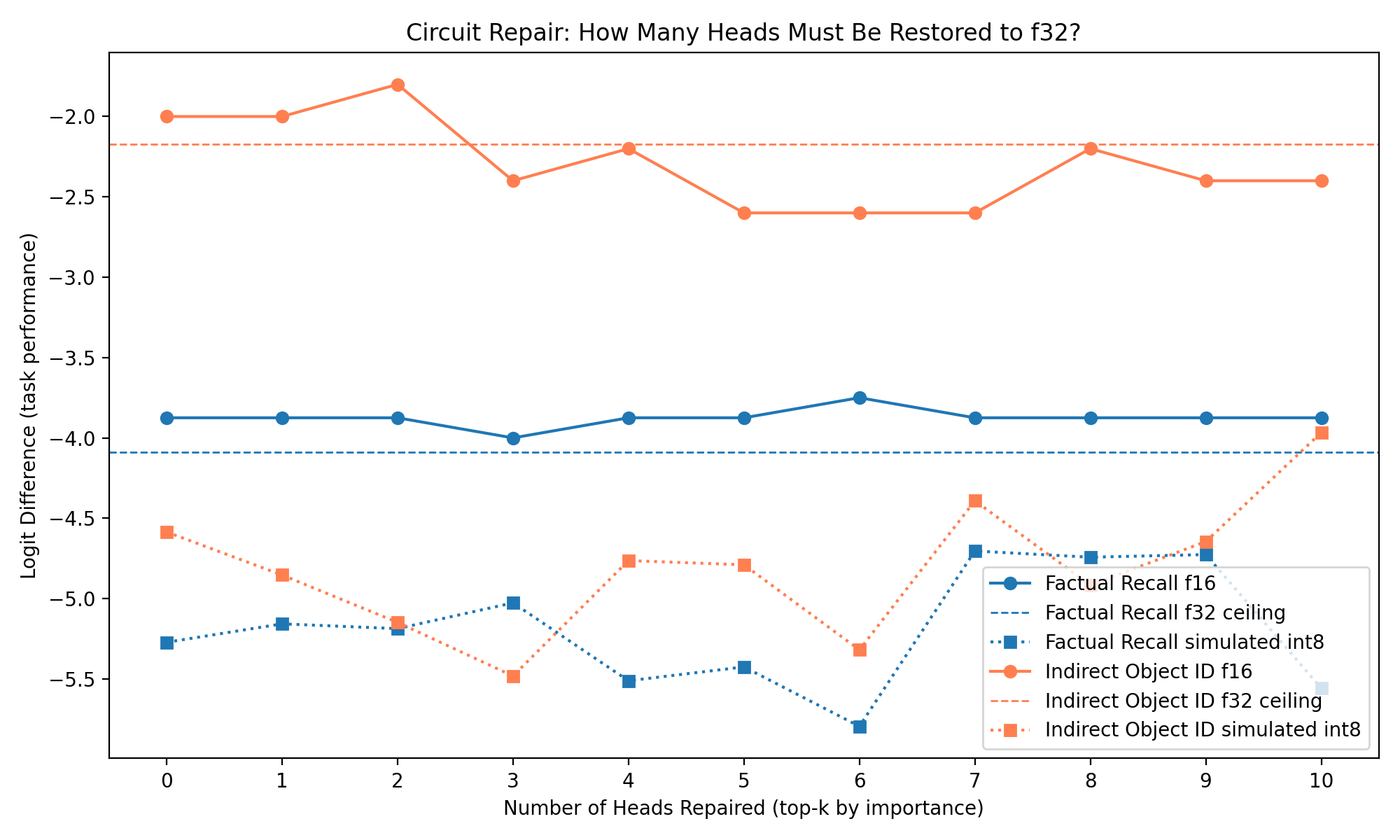
Repair Curve
-
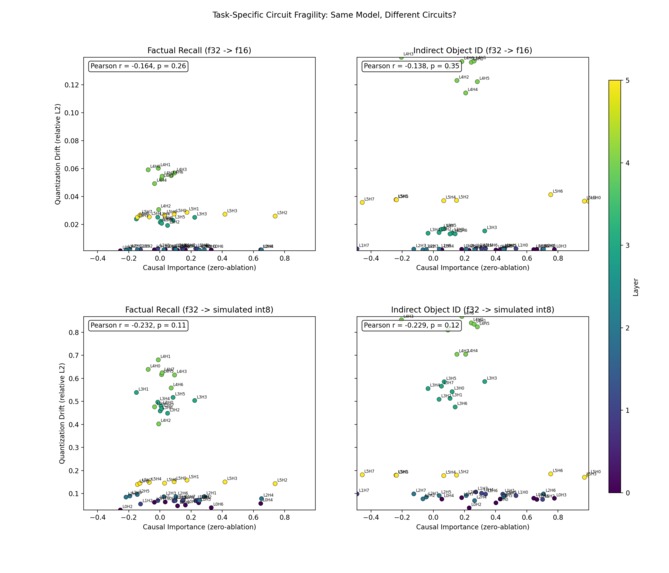
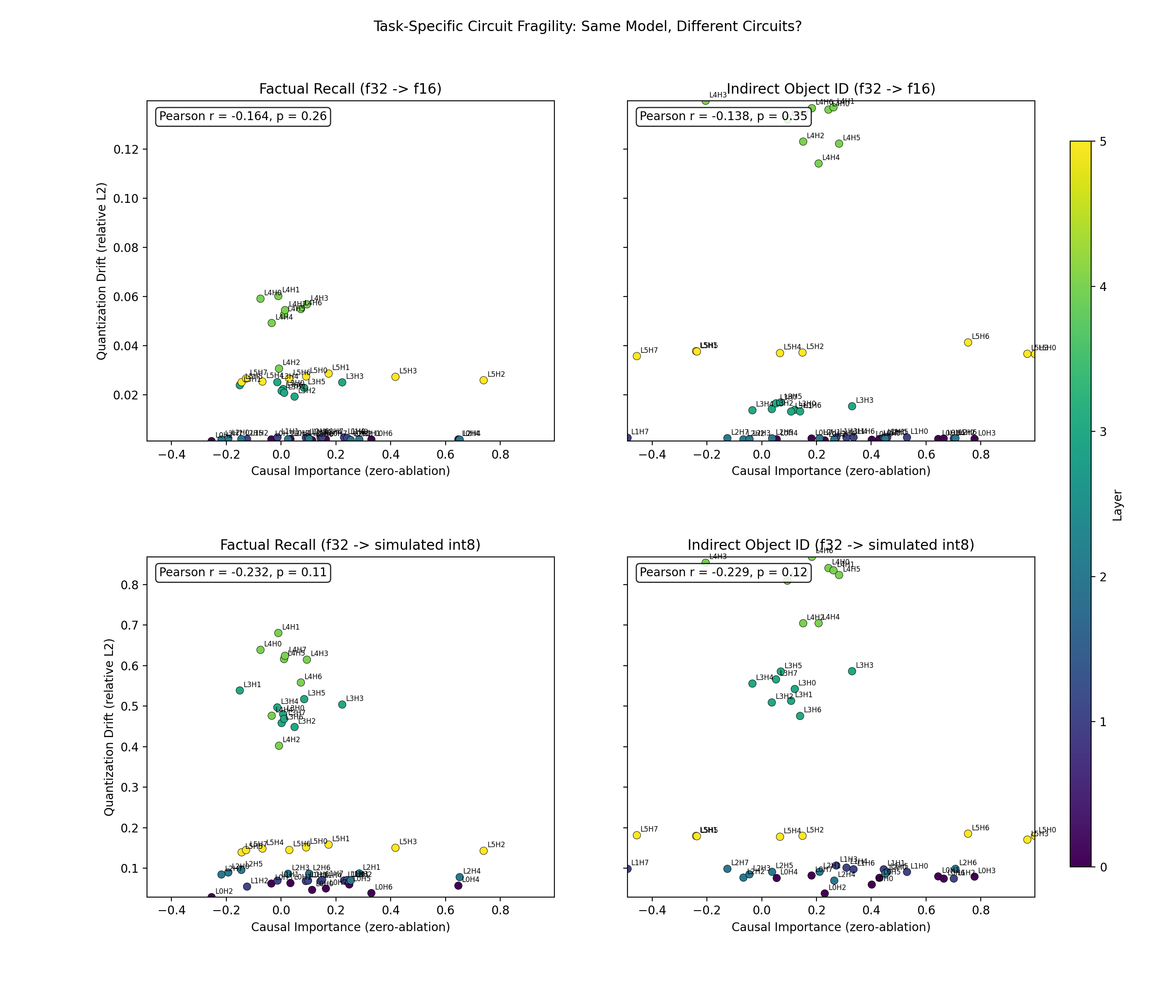
Task-Specific Fragility
-
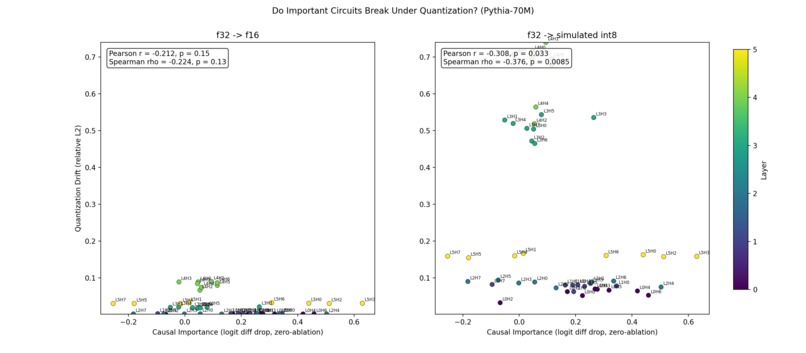
Importance vs Drift
-
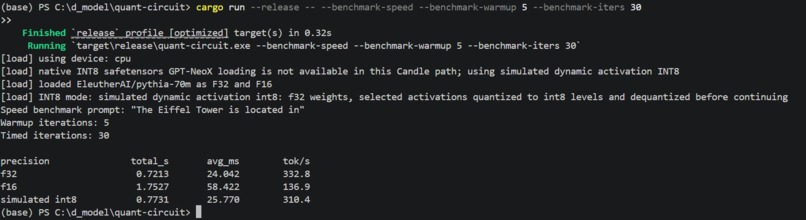
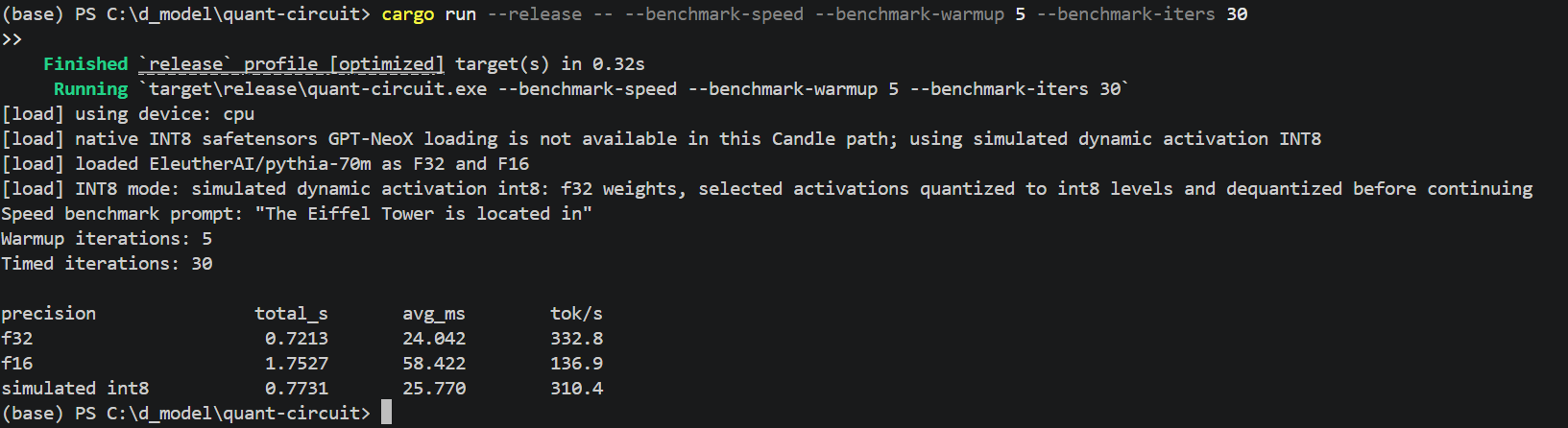
Benchmarking

About
Inspiration
We were inspired by a simple question: when we quantize a transformer to make it smaller and faster, does it still “think” the same way internally? Most quantization research focuses on preserving accuracy, but we wanted to investigate whether the internal attention-head circuits responsible for computation remain stable under compression. That led us to explore the intersection of mechanistic interpretability, model efficiency, and AI safety.
What We Built
We built a Rust/Candle mechanistic interpretability system around Pythia-70M to study circuit fragility under quantization.
Our project measures:
- Causal importance of attention heads using ablation
- Activation drift under precision changes (f32 → f16 and f32 → simulated INT8)
- Circuit repair, by restoring full-precision activations inside lower-precision runs
We used drift metrics:
$$ \text{Relative Drift} = \frac{|a_{f32}-a_{q}|}{|a_{f32}|} $$
and evaluated whether important circuits were more or less fragile under quantization:
$$ \text{Task Degradation} \leq \sum_{l,h} |\nabla_{a_{l,h}} f| \cdot |\delta_{l,h}| $$
What We Learned
Our biggest surprise was that the original hypothesis may have been wrong.
We expected important circuits to break first.
Instead, we found evidence that important circuits may actually be more robust under quantization, especially under simulated INT8.
We also learned:
- FP16 largely preserved internal circuits
- Simulated INT8 caused larger drift and task degradation
- Repair was much harder than expected, suggesting damage may be distributed rather than localized
How We Built It
We implemented the project in Rust using Candle, with a custom hooked GPT-NeoX/Pythia forward pass because native head-level intervention hooks were unavailable.
We built:
- Per-head activation caching
- Causal ablation experiments
- Drift analysis across precision modes
- Activation repair experiments
- JSON experiment outputs and Python plotting for analysis
Challenges We Faced
1. No Native Hook API
Candle did not provide the hook infrastructure we needed, so we implemented our own head-level intervention point.
2. No Native INT8 Path
Native INT8 loading for this Pythia path was unavailable, so we implemented a clearly documented simulated dynamic activation INT8 fallback.
3. Repair Instability
Repair results were noisy and inconsistent, which turned into an important negative result rather than something we hid.
What’s Next
Next, we’d like to:
- Test native INT8/INT4 inference
- Improve repair using importance × drift targeting
- Move beyond attention heads into feature-level circuits
- Scale the experiment to larger models
Why It Matters
This matters because efficient AI systems should preserve not just output accuracy, but the internal reasoning circuits we rely on for interpretability and trust.
Our results suggest that quantization can affect internal mechanisms in a non-uniform way: some important circuits may remain robust, while others may be disproportionately fragile.
Conceptually, the question is not just whether behavior is preserved:
$$ f(x) \approx \hat{f}(x) $$
but whether the underlying internal computation is preserved:
$$ C(x) \approx \hat{C}(x) $$
If output behavior appears similar while internal circuits change significantly, current evaluation may miss meaningful shifts in how the model computes.
Understanding which circuits remain robust and which drift under compression could help design AI systems that are not only efficient, but also more interpretable, trustworthy, and safer to deploy.

Log in or sign up for Devpost to join the conversation.