EdgeLedger — AI-Powered Financial Document Intelligence Platform
Overview
EdgeLedger is an intelligent financial document analysis platform designed to automate the extraction, interpretation, risk evaluation, and compliance assessment of complex loan agreements and financial contracts.
Traditional financial document review is slow, repetitive, and error-prone. Analysts often spend hours manually reviewing PDFs to identify risky clauses, repayment obligations, penalties, collateral terms, and regulatory inconsistencies.
EdgeLedger transforms this workflow into an AI-powered real-time system capable of processing documents in seconds while providing explainable risk insights and portfolio-level intelligence.
Problem Statement
Financial institutions process thousands of loan agreements every month.
Manual review workflows suffer from:
- High operational costs
- Human error and inconsistency
- Delayed compliance detection
- Limited portfolio visibility
- Slow due diligence processes
Traditional review pipelines typically require:
| Task | Manual Time |
|---|---|
| Loan agreement review | 30–60 mins |
| Risk assessment | 15–20 mins |
| Compliance validation | 20–30 mins |
| Cross-document comparison | 1–2 hours |
This creates massive inefficiencies at scale.
Solution
EdgeLedger introduces an AI-native compliance intelligence engine that combines:
- Large Language Models
- Semantic search
- Risk scoring systems
- Automated compliance evaluation
- Real-time analytics
- Intelligent document understanding
The system converts unstructured loan PDFs into structured, searchable, explainable financial intelligence.
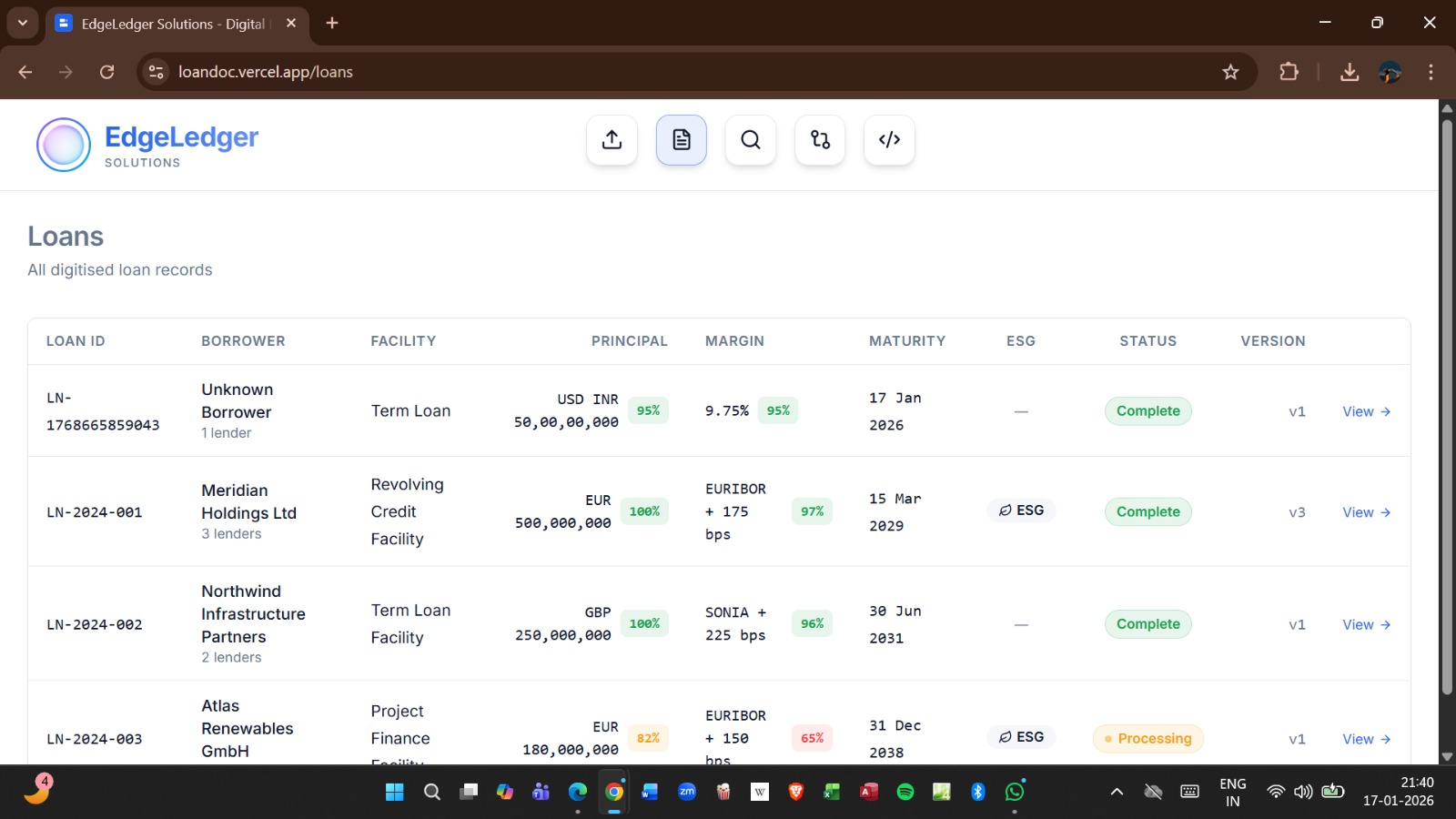
Core Features
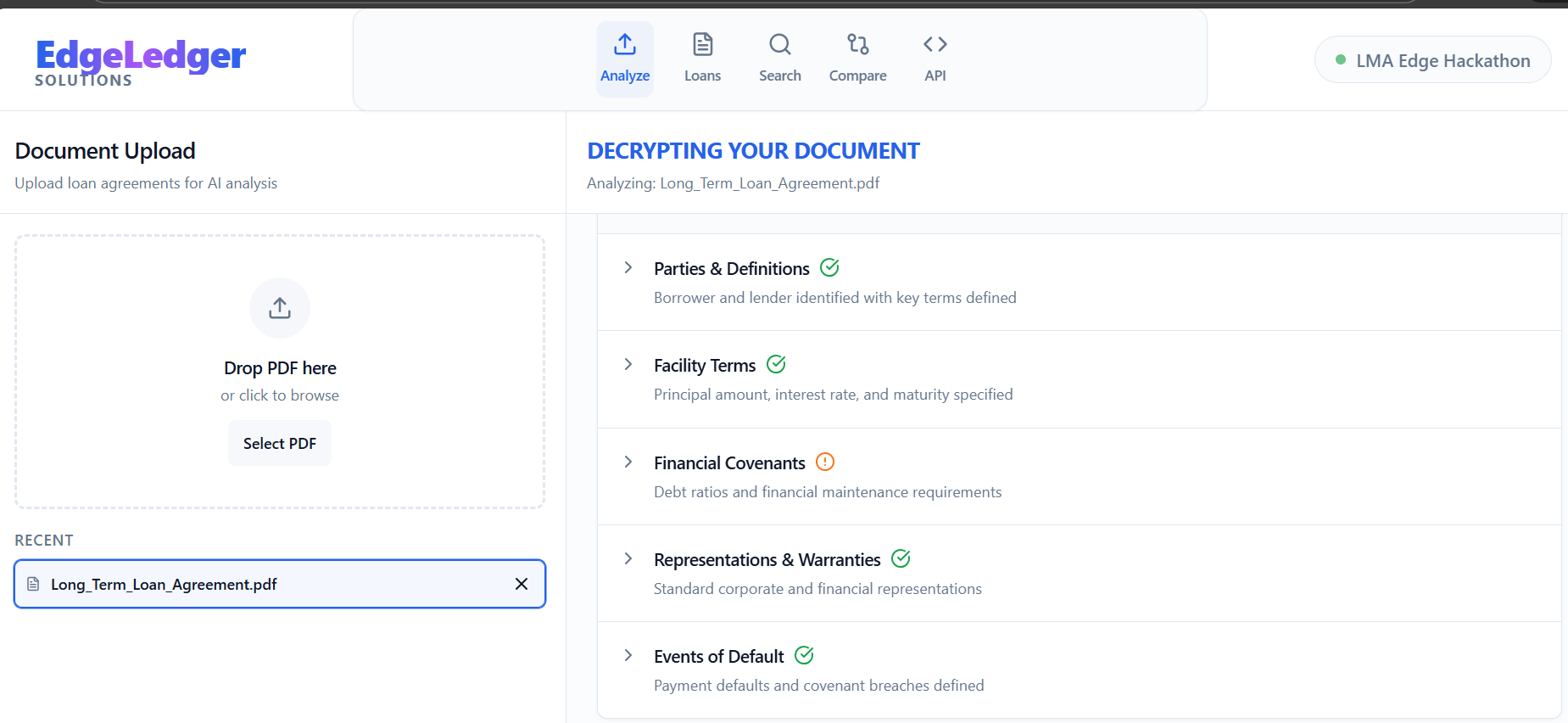
Intelligent PDF Processing
- Automated document ingestion
- Clause segmentation
- Metadata extraction
- Financial term identification
- Borrower & lender detection
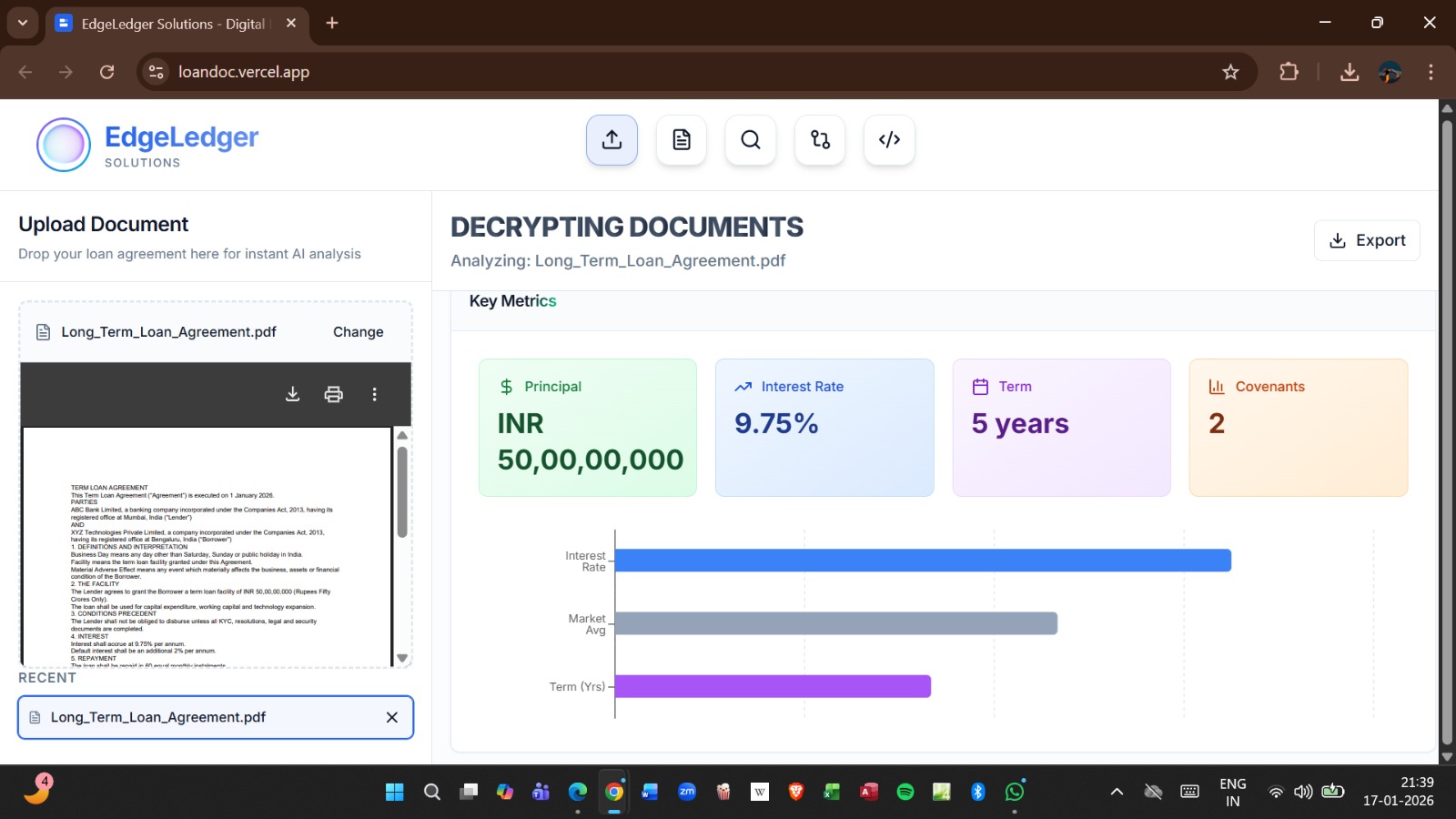
AI-Powered Risk Engine
EdgeLedger evaluates loan agreements using a hybrid explainable scoring model.
Risk Formula
$$ RiskScore = w_1R_{interest} + w_2R_{penalty} + w_3R_{compliance} + w_4R_{collateral} $$
Where:
- $R_{interest}$ → abnormal interest structures
- $R_{penalty}$ → aggressive penalty clauses
- $R_{compliance}$ → regulatory inconsistencies
- $R_{collateral}$ → collateral seizure severity
The system generates:
- Numerical risk scores
- Risk categories
- Clause-level explanations
- Compliance summaries
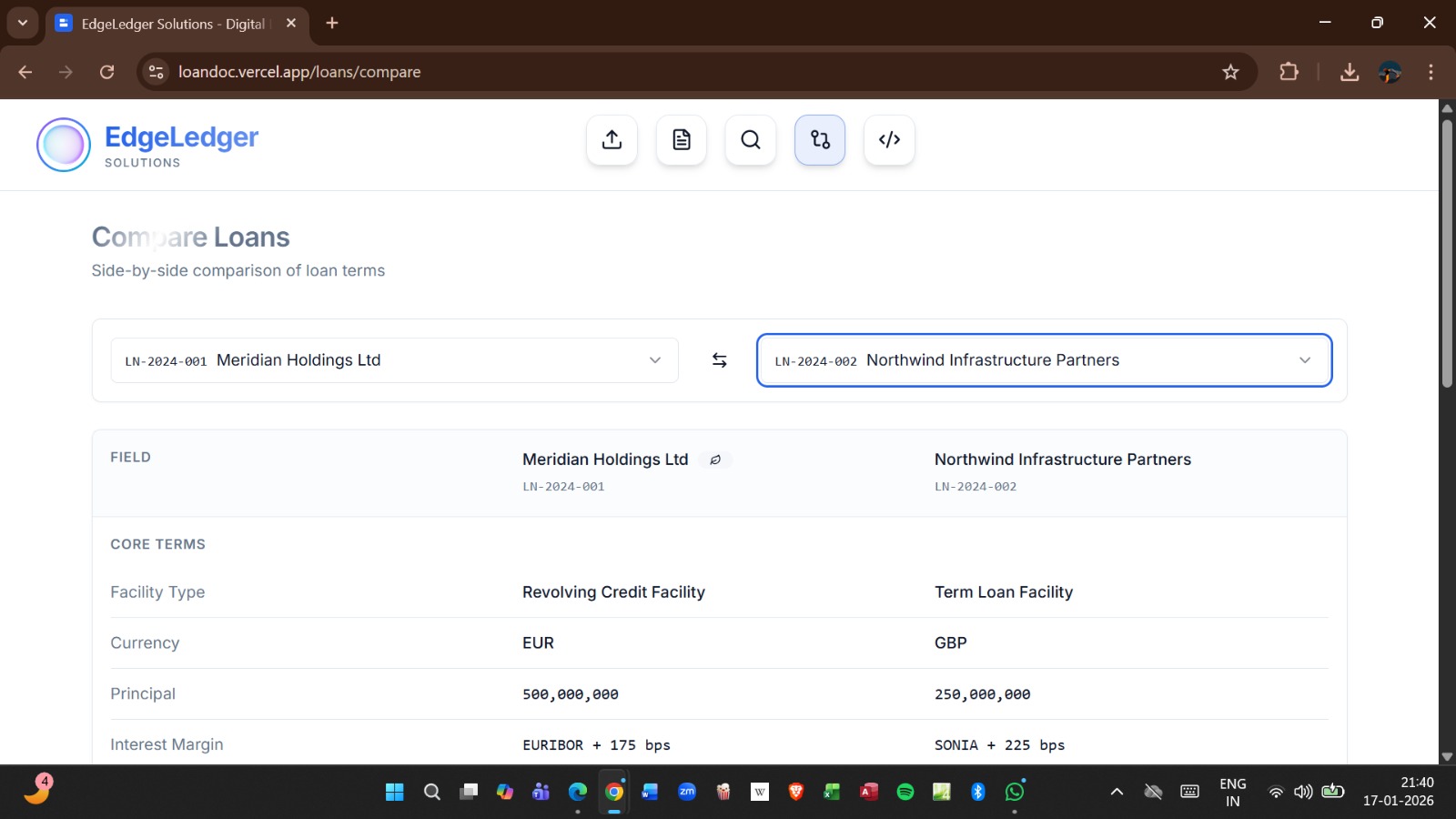
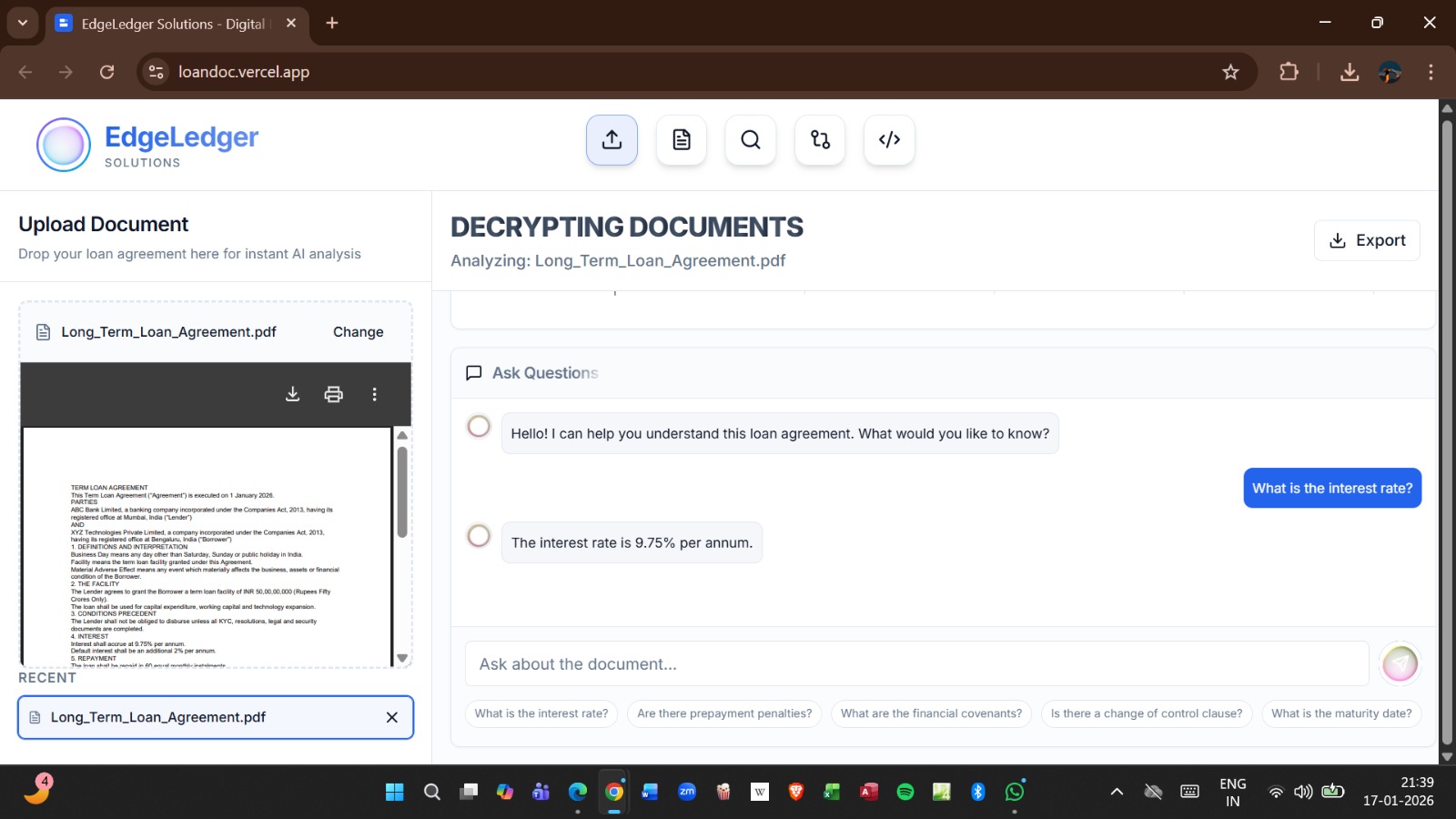
Semantic Search Engine
Users can search financial clauses using natural language.
Example Query
“Find agreements containing aggressive foreclosure clauses”
The platform performs vector similarity matching across all indexed agreements and surfaces semantically related clauses instantly.
AI Compliance Monitoring
The platform continuously evaluates:
- Interest rate violations
- Borrower concentration risk
- Regional exposure imbalance
- Missing disclosures
- High-risk clause density
When thresholds are exceeded, automated alerts are generated.
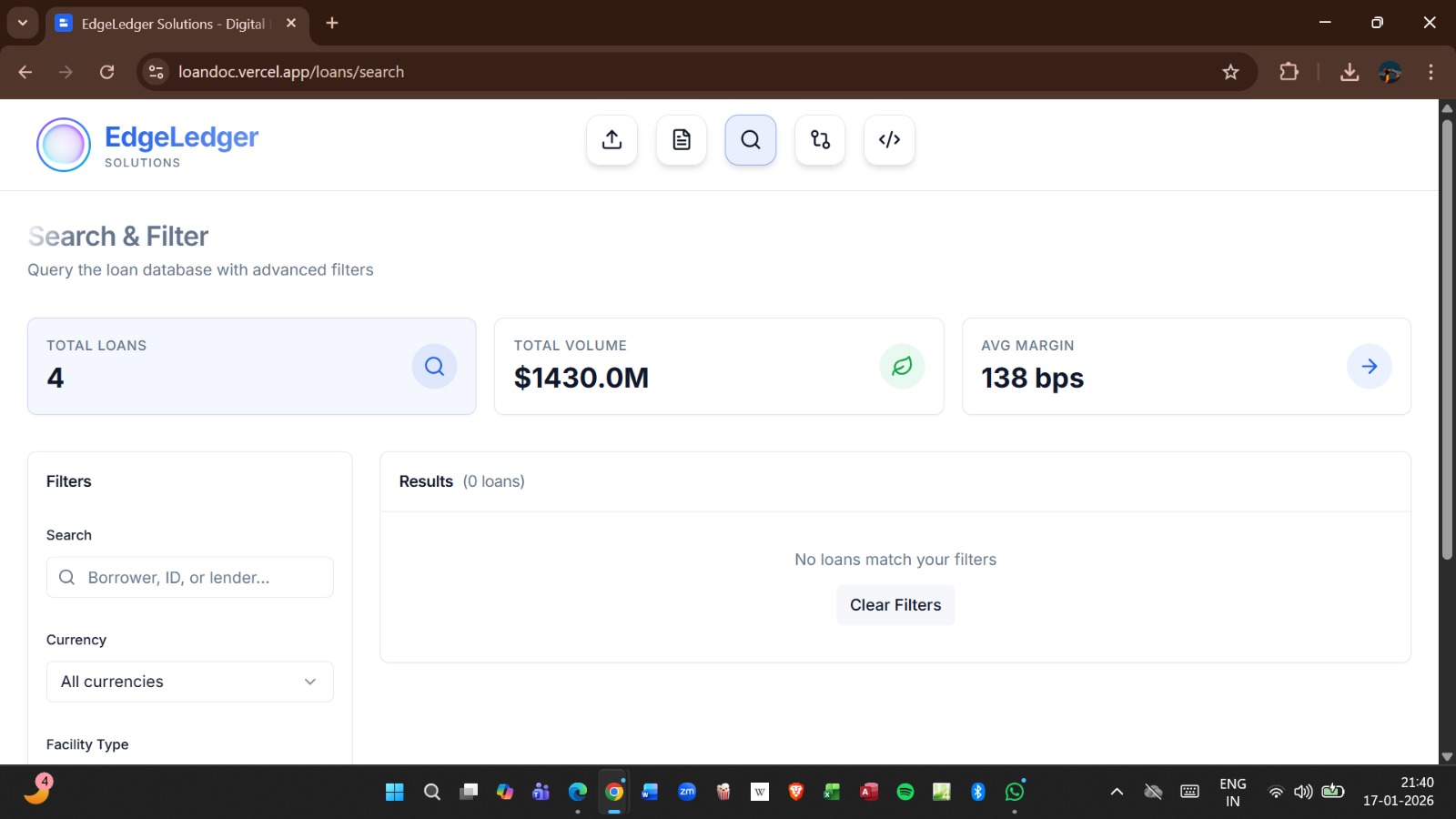
Portfolio Analytics Dashboard
EdgeLedger provides portfolio-wide intelligence including:
- Risk distribution
- Regional analysis
- Exposure tracking
- Trend monitoring
- Compliance heatmaps
- Borrower concentration analysis
System Architecture
┌──────────────────────┐
│ Frontend Dashboard │
│ React / Next.js UI │
└──────────┬───────────┘
│
▼
┌──────────────────────┐
│ API Gateway │
│ FastAPI │
└──────────┬───────────┘
│
┌──────────────────┼──────────────────┐
│ │ │
▼ ▼ ▼
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ Extraction │ │ Risk Engine │ │ Compliance │
│ Agent │ │ │ │ Agent │
└──────┬──────┘ └──────┬──────┘ └──────┬──────┘
│ │ │
└─────────────────┼─────────────────┘
▼
┌───────────────────┐
│ Vector + Search DB│
│ Semantic Indexing │
└───────────────────┘
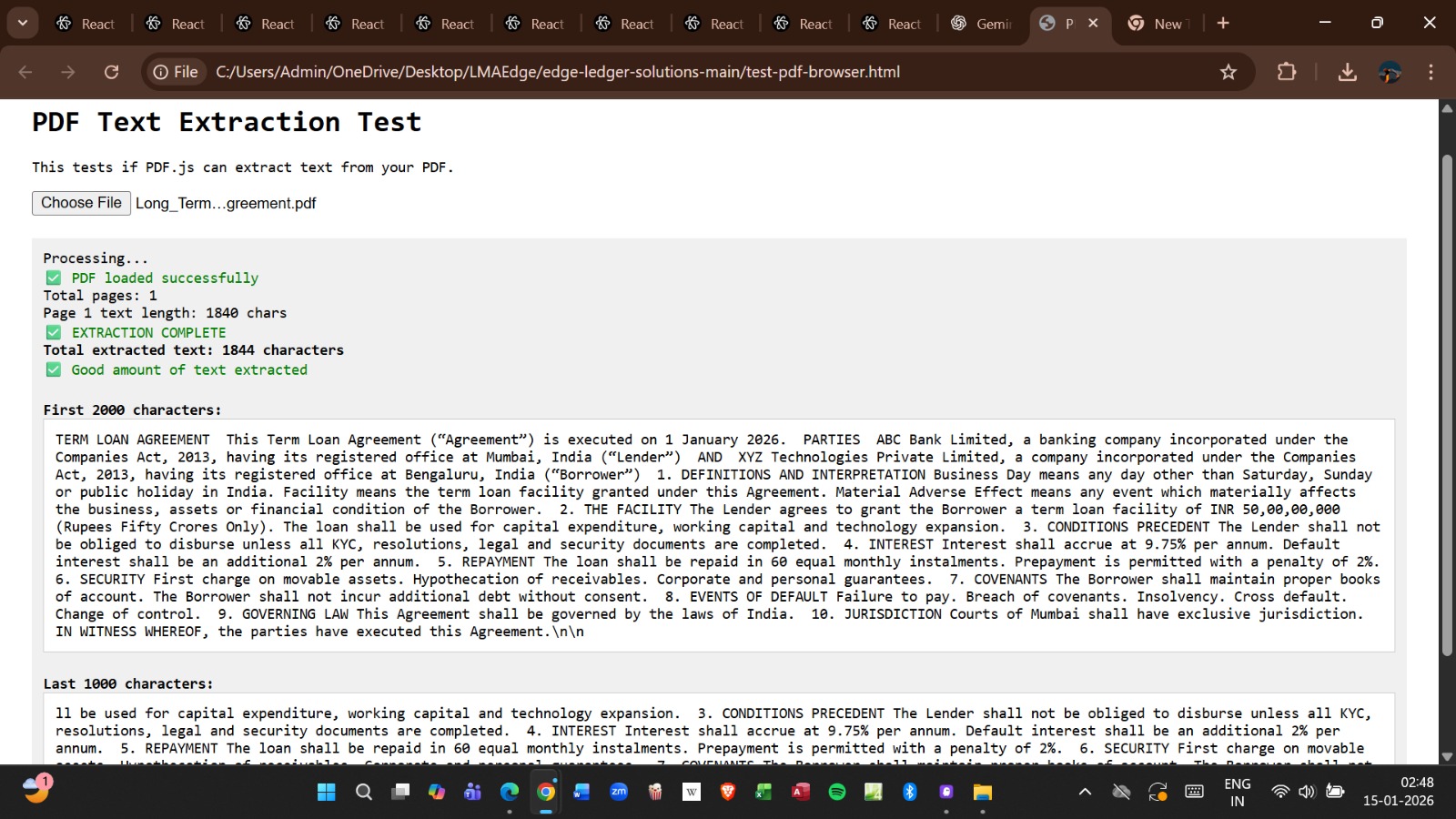
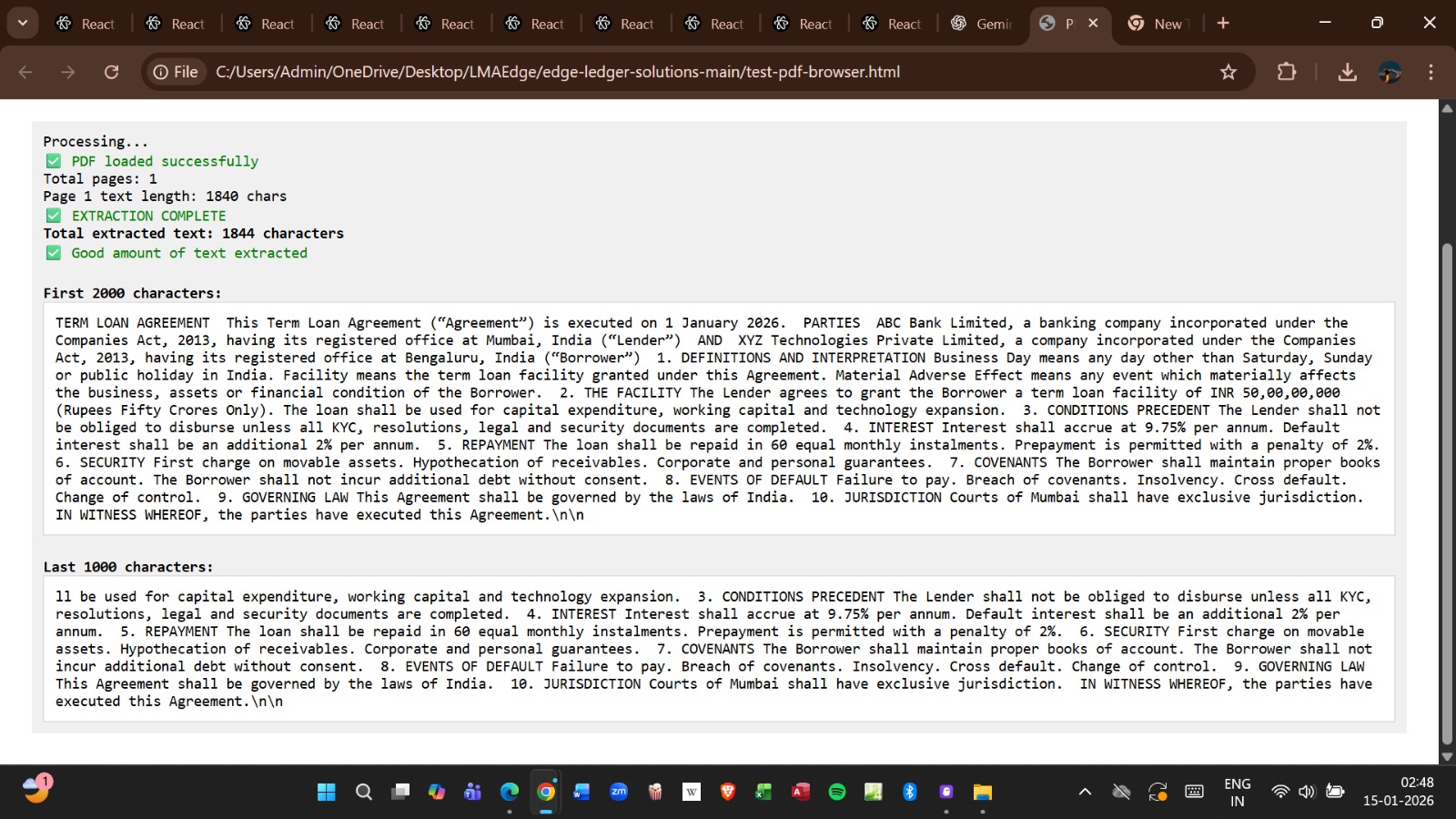
AI Workflow Pipeline
Step 1 — Document Upload
Users upload financial agreements in PDF format.
Step 2 — Intelligent Parsing
The platform extracts:
- Financial clauses
- Interest structures
- Borrower obligations
- Penalty terms
- Collateral conditions
Step 3 — Embedding Generation
Each clause is transformed into high-dimensional semantic vectors for contextual search and retrieval.
Step 4 — Risk Evaluation
AI models evaluate:
- Clause severity
- Compliance exposure
- Financial anomalies
- Structural inconsistencies
Step 5 — Explainable Insights
The platform generates:
- AI summaries
- Risk reasoning
- Highlighted clauses
- Portfolio recommendations
Technical Stack
| Layer | Technologies |
|---|---|
| Frontend | Next.js, React, TailwindCSS |
| Backend | FastAPI, Python |
| AI Models | LLMs + Embedding Models |
| Search Layer | Vector Search + Semantic Retrieval |
| Database | Indexed Document Storage |
| Analytics | Real-Time Aggregation Engine |
Mathematical Foundation
Cosine Similarity Search
For semantic clause retrieval:
$$ Similarity(A,B)= \frac{A \cdot B} {|A||B|} $$
This enables contextual retrieval instead of simple keyword matching.
Portfolio Risk Aggregation
$$ PortfolioRisk = \frac{\sum_{i=1}^{n} LoanRisk_i}{n} $$
Used for:
- regional risk analysis
- exposure monitoring
- compliance forecasting
Key Advantages
Speed
Processes documents in seconds instead of hours.
Explainability
Every risk score includes human-readable reasoning and clause-level traceability.
Scalability
Supports bulk document ingestion and large-scale portfolio analytics.
Intelligence
Combines semantic understanding with structured financial analysis.
Real-World Impact
| Metric | Traditional Workflow | EdgeLedger |
|---|---|---|
| Review Time | 30–60 mins | <15 seconds |
| Manual Effort | High | Minimal |
| Error Rate | Significant | Reduced |
| Portfolio Visibility | Limited | Real-time |
| Compliance Monitoring | Reactive | Automated |
Future Enhancements
- Multi-language financial document support
- Predictive default risk forecasting
- Automated remediation suggestions
- Real-time regulatory update ingestion
- Institution-wide risk intelligence systems
Conclusion
EdgeLedger demonstrates how AI can transform financial document analysis from a slow manual workflow into an intelligent, explainable, scalable system.
By combining semantic understanding, automated compliance monitoring, and portfolio-level analytics, the platform enables financial institutions to review agreements faster, reduce operational risk, and make smarter lending decisions.

Log in or sign up for Devpost to join the conversation.