-
-

EcoSys
-

-

Inspiration Most people who want to build a garden, terrarium, aquarium, or backyard ecosystem have no idea where to start. They search for plant lists, read conflicting advice, and end up with a collection of species that don't actually work together — wrong climate, wrong trophic level, wrong water needs. The knowledge exists, but it's scattered and hard to apply to a specific situation.
We wanted to build something that closes that gap: a tool that lets anyone model a living ecosystem before they build it, get AI-powered advice grounded in real ecological knowledge, and identify what they're looking at in the wild — all without needing a biology degree or an internet connection to a paid API.
The deeper inspiration was the idea that ecology is fundamentally a systems problem. Food chains, nutrient cycles, pollinator networks — these are all interconnected graphs. If you can visualize and simulate those relationships, you can make better decisions. EcoSys is our attempt to make that kind of systems thinking accessible to anyone.
What it does EcoSys is an AI-powered ecosystem design and advisory platform with four core capabilities:
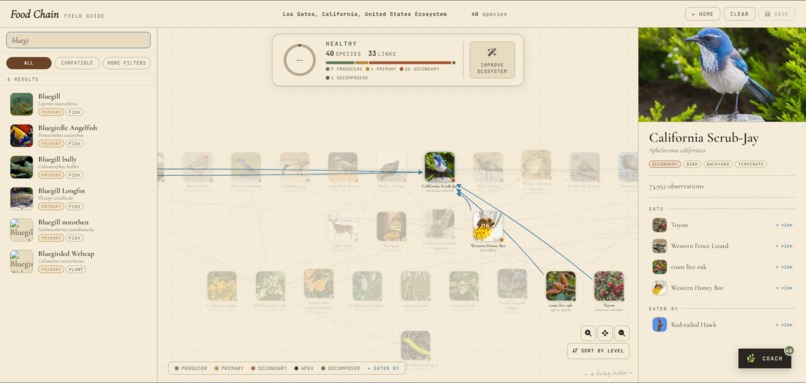
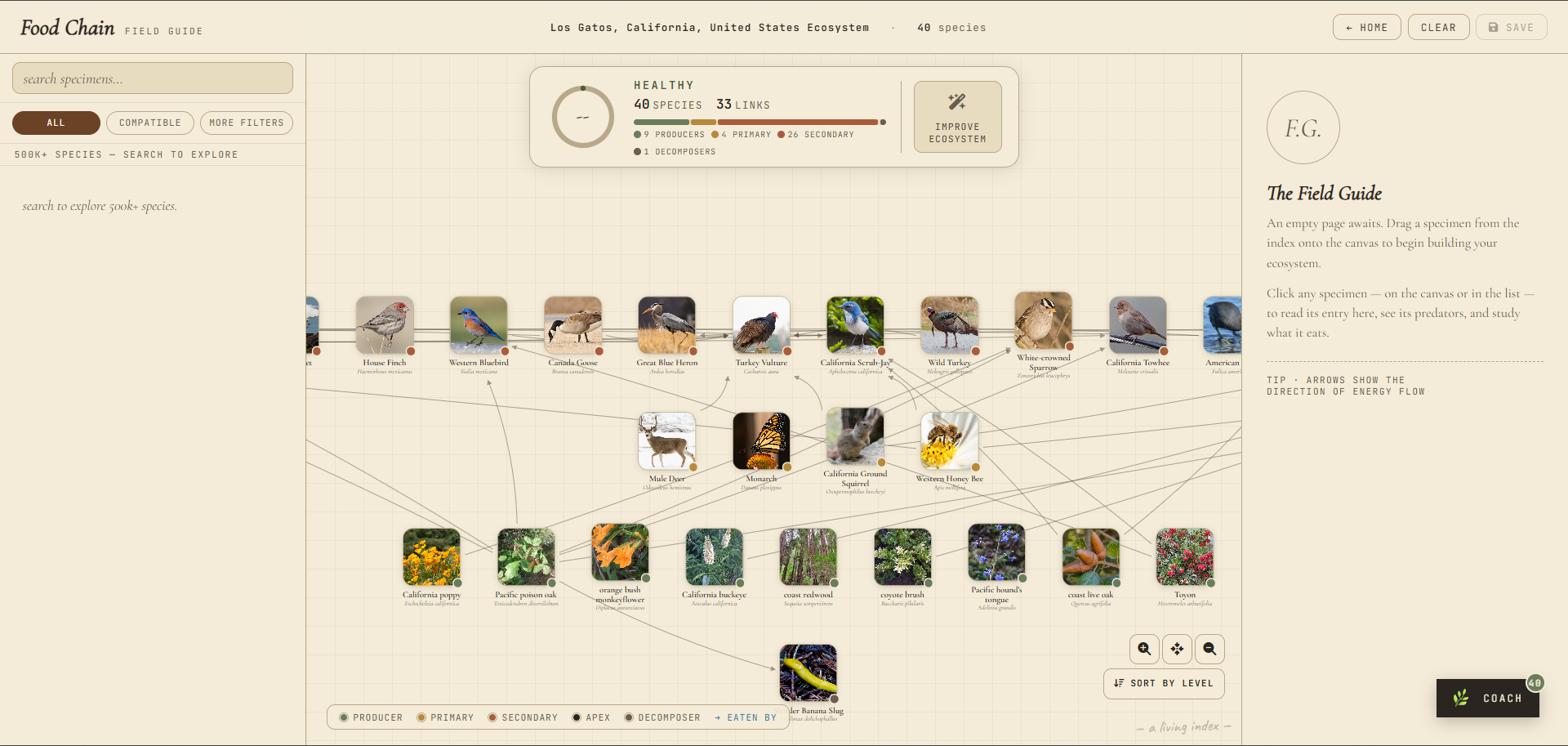
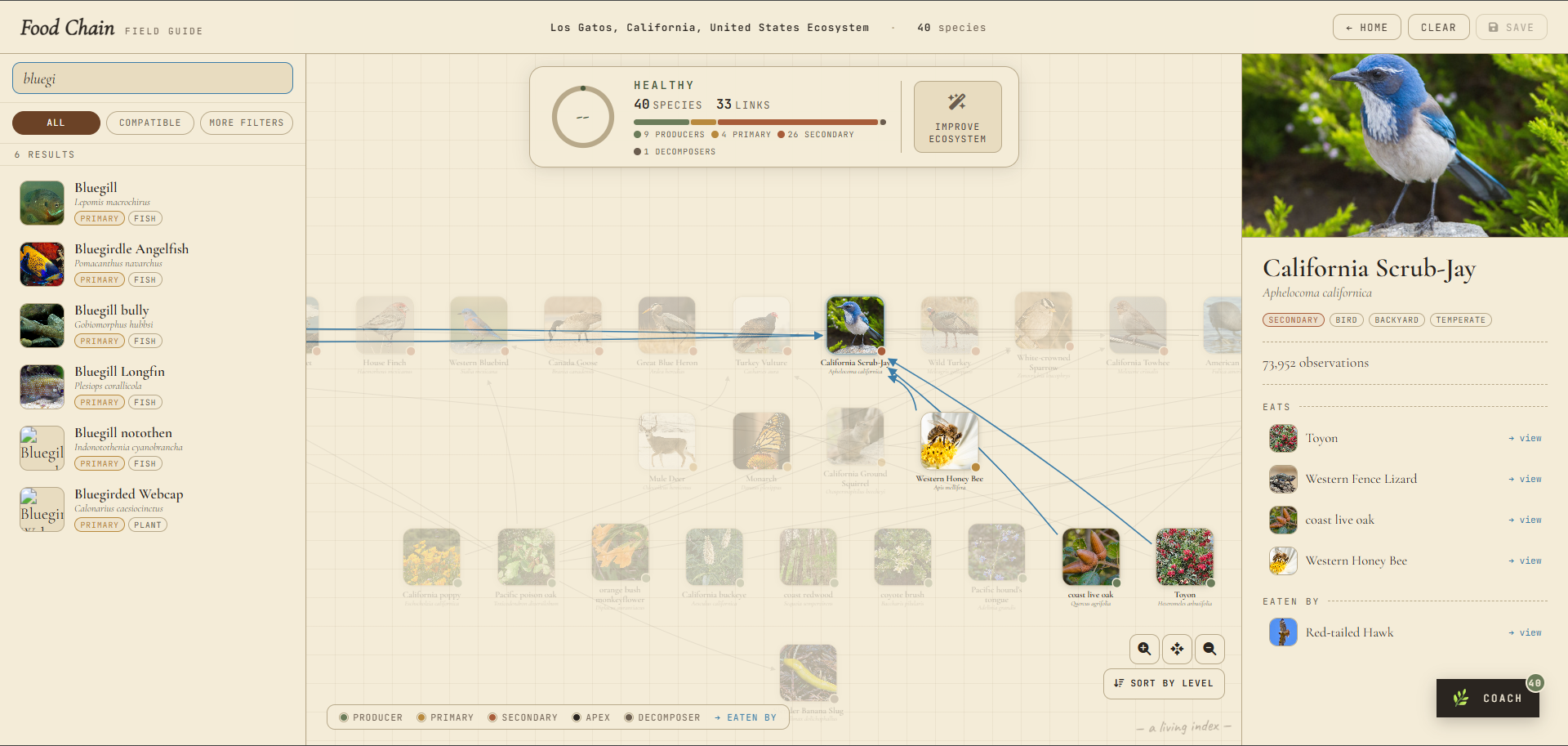
Ecosystem Builder: A visual canvas where users drag and drop species (plants, animals, insects, decomposers, fish) onto a grid. The app tracks trophic relationships, draws food chain connections, and scores the ecosystem in real time for sustainability and biodiversity. Users can see at a glance which trophic levels are missing, which species are incompatible, and how their choices affect the overall health score.
EcoDoctor Chat : A conversational AI coach powered by a local Ollama model and a RAG (Retrieval-Augmented Generation) pipeline backed by Supabase and pgvector. Users ask questions in plain language "What plants grow well in Southern California?", "Why are my leaves turning yellow?", "What's missing from my food chain?" and get answers grounded in an ingested knowledge base of ecological documents. The system retrieves the most relevant chunks by cosine similarity, injects them into the prompt, and cites sources in the response.
Photo Insights : Users upload a photo of a plant, animal, insect, fungus, or soil sample. The image is sent to a local Ollama vision model (moondream), which identifies the subject and returns structured ecosystem insights: category, common name, scientific name, confidence score, health status, ecosystem role, observations, and recommended actions. Results are saved to Supabase for future reference.
Knowledge Base : A RAG ingestion pipeline that processes .md, .txt, and .pdf documents, chunks them with overlap, embeds each chunk using nomic-embed-text (768-dimensional vectors), and stores them in a pgvector table with HNSW indexing for fast similarity search. The knowledge base grows as more documents are added.
How we built it The stack is deliberately local-first and privacy-respecting; no OpenAI API key is required for the core experience.
Frontend is React 18 with React Router, Three.js for the 3D globe on the home page, and a custom CSS design system built around a paper/botanical aesthetic. Vite handles the build and dev server.
Backend runs entirely inside Vite's configureServer middleware, no separate Express server needed. The /api/chat and /api/vision-insights routes are registered as Node.js middleware, keeping all backend code (Supabase keys, Ollama calls, RAG logic) server-side and out of the browser bundle.
RAG pipeline uses Ollama's nomic-embed-text model to embed document chunks and query vectors. Supabase PostgreSQL with the pgvector extension stores the chunks and runs cosine similarity search via an HNSW index. A custom chunking algorithm splits documents on paragraph boundaries with 100-token overlap, with a hard safety limit of 2000 characters per chunk to prevent Ollama context-length errors on dense PDF text.
Multi-agent orchestration routes each user message through intent detection, context extraction (location, ecosystem type, goal), parallel agent execution (plant planning, sustainability scoring, biodiversity analysis, diagnosis, memory), RAG retrieval, and finally an LLM synthesis step that produces both a conversational response and structured card data.
Vision pipeline accepts multipart file uploads, resizes images to 768px with sharp, base64-encodes them, and sends them to Ollama's /api/generate endpoint with the image attached. The response is parsed with multiple fallback strategies to handle models that don't always return clean JSON.
Challenges we ran into The browser/Node.js boundary was the hardest architectural problem. Vite injects VITE_* environment variables into import.meta.env at build time, but they're not available in process.env in the Node.js middleware. This meant config.llmProvider was always resolving to the fallback value, silently routing every chat request through the mock response instead of Ollama. The fix required adding plain (non-VITE-prefixed) copies of the env vars and rewriting config.js to use lazy getters that read process.env at call time rather than at module load time.
Merge conflicts accumulated across multiple development branches, leaving unresolved <<<<<<< HEAD markers in EcosystemBuilder.jsx, HomePage.jsx, chatService.js, and package.json. Each had to be carefully resolved by reading both versions and keeping the richer one.
Ollama vision timeouts: llava was consistently timing out at 180 seconds on CPU. Switching to moondream and reducing the timeout to 90 seconds, combined with resizing images to 768px before encoding, brought inference time down to a manageable range.
Hardcoded fallback responses kept surfacing. The mock response function had a generic else branch that returned the same onboarding question regardless of what the user asked. Fixing this required intent detection across 10+ categories, location detection for major regions, and completely removing the buildTemplateFallback function that was generating static species cards.
PDF chunking : pdf-parse often returns the entire document as a single paragraph with no blank lines, bypassing the paragraph-based chunking logic and sending thousands of characters to Ollama in one shot. The fix was a splitOversized function that breaks any chunk exceeding 2000 characters on sentence boundaries, falling back to word boundaries, then character count.
Accomplishments that we're proud of A fully local AI stack: chat, embeddings, and vision all run on-device with no external API keys required for the core experience. A RAG pipeline that goes from raw .md/.txt/.pdf documents to semantically searchable vector chunks in a single npm run rag: ingest command. A multi-agent architecture where intent detection, context extraction, RAG retrieval, and LLM synthesis all happen in a single request cycle, with each agent running in parallel where possible. The Vite middleware pattern, running a full backend inside the dev server without needing a separate process, while keeping all secrets server-side. A vision feature that works entirely offline, identifies ecosystem subjects from photos, and saves structured results to a database. A design system that feels like a botanical field guide, the paper texture, serif typography, and hand-drawn aesthetic make the app feel grounded in nature rather than tech. What we learned Local LLMs are genuinely capable of domain-specific tasks when given good context, the quality of the RAG context matters far more than the size of the model. The browser/Node.js boundary in Vite is subtle and easy to get wrong. import.meta.env and process.env are not the same thing, and the difference only shows up at runtime. Merge conflicts in a fast-moving codebase compound quickly. Resolving them requires reading both versions carefully rather than just accepting one side. The chunking strategy has a bigger impact on RAG quality than retrieval parameters. Getting the chunk size, overlap, and safety limits right is what makes the difference between useful and useless retrieval. Small models like moondream and qwen2.5:3b are surprisingly capable when the prompt is well-structured and the context is focused. The system prompt and RAG injection matter more than model size for most practical tasks. What's next for EcoSys Richer knowledge base: Ingest regional plant databases, USDA hardiness zone data, invasive species lists, and companion planting guides to give EcoDoctor deeper, more location-specific knowledge.
User accounts and persistent projects: Replace the in-memory project store with Supabase Auth and a projects table so ecosystems persist across sessions and devices.
Species photo recognition at scale: Integrate iNaturalist's API or a fine-tuned plant identification model to improve vision accuracy beyond what general-purpose vision models can achieve.
Ecosystem simulation: Add time-based simulation to the canvas: seasonal bloom cycles, population dynamics, predator-prey relationships playing out over a virtual year.
Mobile app: The photo insights feature is a natural fit for a mobile camera experience. A React Native port would let users identify plants and animals in the field and add them directly to their ecosystem canvas.
Community knowledge base: Let users contribute documents, species profiles, and regional guides that get ingested into the shared RAG knowledge base, improving answers for everyone.
Built With
- java
- postgresql
- python
- react
- sql
- supabase

Log in or sign up for Devpost to join the conversation.