-
-
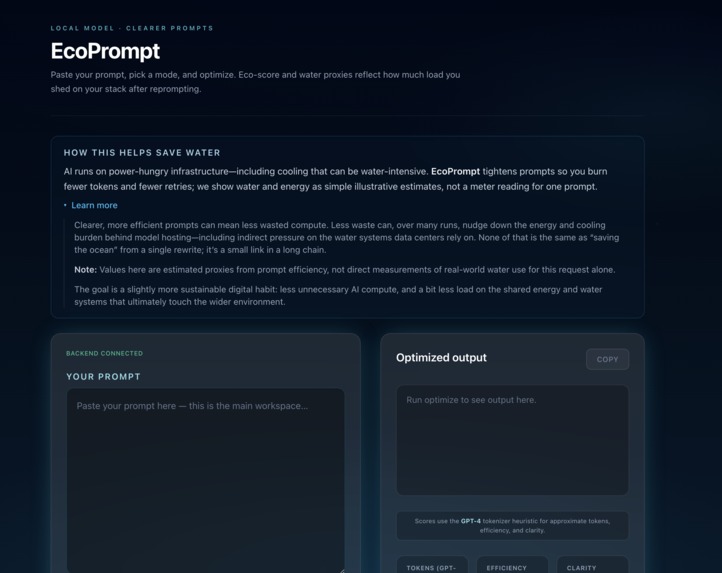
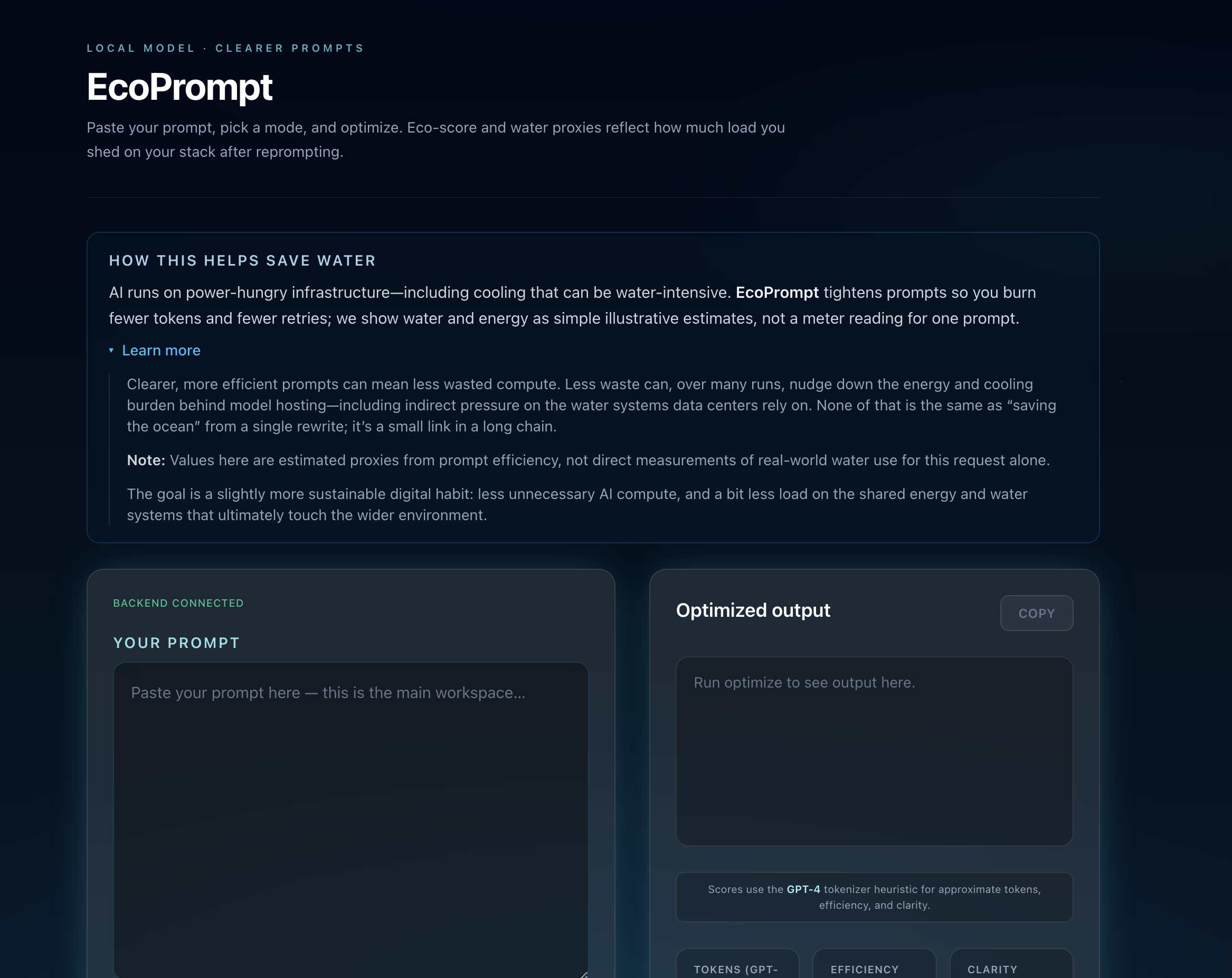
Basic Page before Prompt Revision
Inspiration
As AI tools become more widely used and shipped, the environmental cost behind every prompt and computation multiplies. According to EESI, large data centers can consume up to 5 million gallons per day, equivalent to the water use of a town populated by 10,000 to 50,000 people. Most users don't realize that inefficient prompts can contribute to this problem by leading to unnecessary computation, increasing consumption.
What it does
A pipeline that takes messy user prompts and rewrites them into tight, well-framed prompts — using two small local models and a retrieval layer for style hints.
Stack:
- Extractor:
qwen2.5:3b— pulls a 6-field skeleton (INTENT, TASK, SUBJECT, OUTPUT, CONSTRAINTS, PROMPT) - Reviser:
gemma3:4b— rewrites using the skeleton + retrieved exemplars - Retrieval: HumanDelta vector DB over
fka/awesome-chatgpt-prompts+ a custom corpus - Scorer: heuristic rubric (concision, preservation, no-leak, no-headers, compression) over 12 labeled test prompts
How It Works
- User gives a raw prompt (could be 3 words or 3 paragraphs)
- Extractor distills it into a structured skeleton
- Gating logic decides whether to retrieve (length, intent, similarity threshold)
- Reviser rewrites — borrowing structure only from retrieved examples, never nouns
- Scorer compares "with retrieval" vs "without retrieval" across categories
What We Learned
- Small models need scaffolding, not trust. A 3B model won't follow a schema just because you hand it one. It needs concrete examples, canonical order enforcement, and a regex safety net.
- RAG is portable leverage. Adding new style patterns = dropping text into a corpus. No fine-tuning, no retraining.
- Retrieval isn't always better. For trivial inputs ("tie a tie"), retrieved "act as a stylist" templates actively hurt. Gating matters more than retrieval quality.
- Structure-only borrowing beats content borrowing. Pulling "Act as a " from an exemplar is safe. Pulling nouns, verbs, or domain words leaks contamination (Ethereum prompts drifting into messenger-app territory).
- Deterministic fallbacks save LLM weaknesses. Regex constraint sweeping caught "3-4 hours a week" that the extractor kept dropping.
Challenges
1. The extractor kept copying its own examples
Give qwen an in-context example with write a python function... and ask it to process "tie a tie" — and the skeleton comes back with PROMPT: write a python function. Fixed by: two diverse examples, explicit "NEVER copy values verbatim," and a short-input rule ("if ≤5 words, copy to PROMPT verbatim").
2. The reviser over-prompted trivial tasks
"Act as a professional stylist to tie a tie" — nobody wants that. Added a QUICK TEST to Rule 1: role prefix only for tasks needing specialized professional expertise. Everyday tasks get step-by-step framing instead.
3. Synonym leaks
Extractor would turn "tie" into "necktie" in the SUBJECT field, and the reviser would propagate it. Hard-coded "NEVER substitute synonyms" at extraction and "if original says X, don't write Y" at revision.
4. Dropped load-bearing constraints
"I can work out 3-4 hours a week" → skeleton CONSTRAINTS: none → revised prompt drops the budget. Fixed in layers:
- Added CONSTRAINTS field to skeleton
- Added SCAN-FOR-CONSTRAINTS list to extractor prompt
- Added
_sweep_constraints()regex safety net that injects missed constraints before revision
The Loop That Shipped It
Every failure mode followed the same rhythm:
- Run test prompt
- Spot a new failure (schema echo, noun leak, dropped constraint)
- Tighten the rule
- Re-run the full test set — does it regress anything else?
- Add a safety net in code if the rule can't be trusted
The scorer made step 4 cheap. Without it, I'd have been guessing whether each fix actually helped.
Takeaway
Small local models + RAG can produce strong results, but only with defensive engineering. The LLM is one component in a pipeline — schema cleaners, regex sweepers, retrieval gates, and scoring loops are the other 70%.
Built With
- fast-api
- human-delta
- jupyter-notebook
- neon-db
- next-js
- ollama
- python


Log in or sign up for Devpost to join the conversation.