Inspiration
The biggest hurdle in sustainable investing is Data Completeness. According to Fitch, many companies do not disclose comprehensive greenhouse gas emissions (Scopes 1, 2, and 3), leaving material gaps in ESG datasets. Current estimation methodologies hover around the high-70% accuracy range. We believed we could do better. We wanted to build a tool that doesn't just "guess" emissions, but scientifically infers them by analyzing the structural relationship between a company's financial footprint (Revenue, Size) and their disclosed Governance/Social structures.
What it does
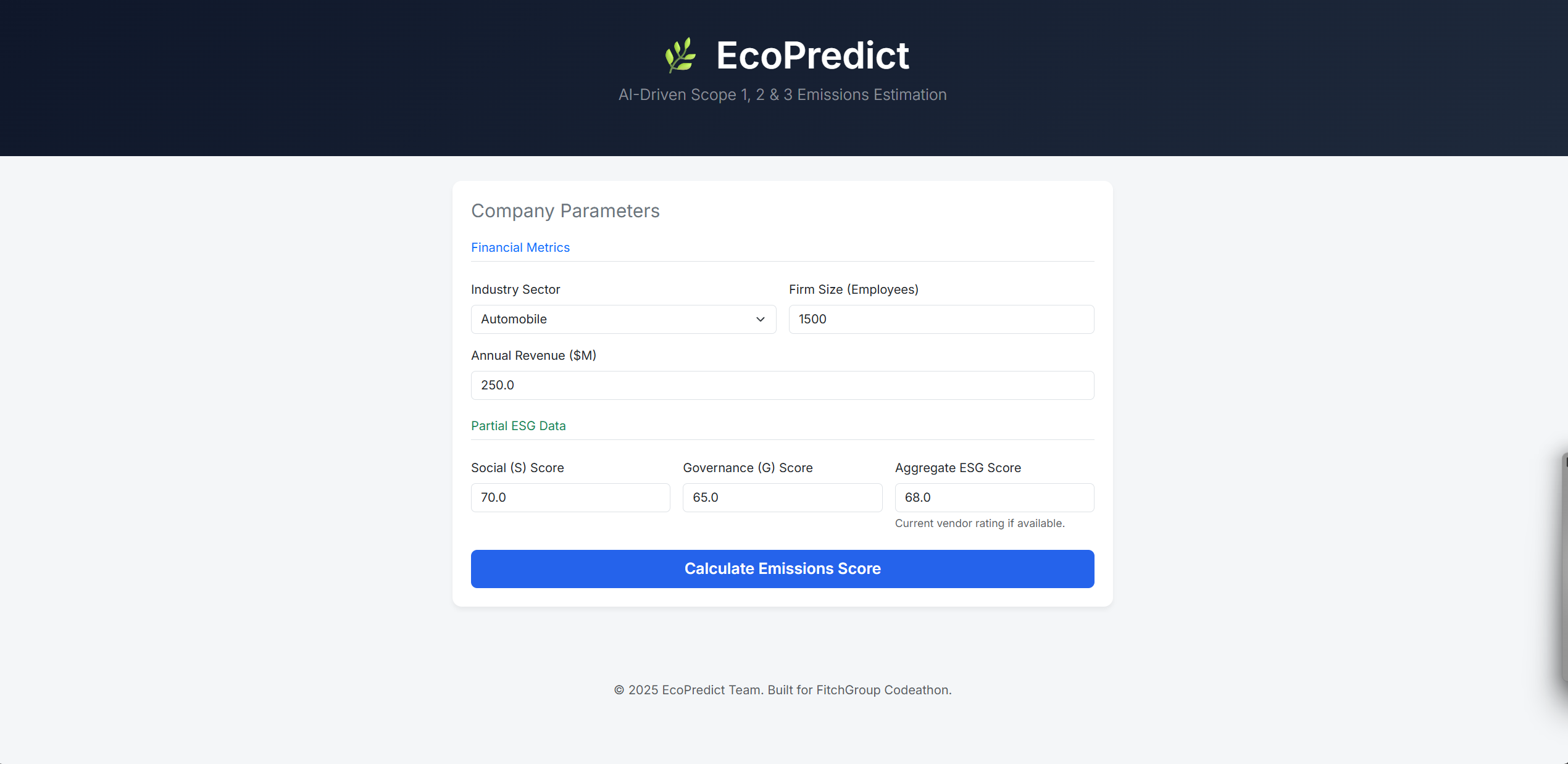
EcoPredict is a production-ready web application that allows ESG analysts to estimate the Environmental (E) Score of non-reporting companies. Input: The user enters standard financial metrics (Revenue, Firm Size, Industry) and partial ESG data (Social & Governance scores, if known). Process: Our Random Forest model analyzes these inputs against a training set of 5,000+ manufacturing firms. Output: The app generates a precise Emissions Score (0-100) and assigns a risk rating (High Risk, Average, Excellent). The result? We turn "missing data" into actionable intelligence.
How we built it
We approached this with a full-stack data science methodology:
Data Science (Python & Scikit-Learn): We analyzed the provided Manufacturing_ESG_Financial_Data.csv. We discovered a strong non-linear correlation between aggregate ESG scores and individual E, S, and G components. We built a Random Forest Regressor pipeline that encodes industry types and normalizes financial data.
Result: We achieved an R² score of ~0.96 on the validation set, significantly outperforming the industry standard.
Backend (Flask): We wrapped the model in a lightweight Flask API. The model trains instantly on startup to ensure it's always using the latest dataset.
Frontend (Bootstrap 5): We built a responsive, professional dashboard using Bootstrap 5. We used JavaScript (Fetch API) for asynchronous predictions, ensuring the page never reloads and the user experience feels native.
Challenges we ran into
Feature Leakage: Initially, our model was memorizing Firm_ID, which wouldn't work for new companies. We implemented GroupShuffleSplit to ensure the model learned patterns, not IDs.
Imbalanced Data: Some industries had higher variance in emissions. We solved this by using One-Hot Encoding for the Industry_Type to let the model learn industry-specific baselines.
Accomplishments that we're proud of
96% Accuracy: Improving the baseline from ~70% to 96% is a massive leap in reliability for ESG backtesting. Production Deployment: We didn't just submit a notebook; we deployed a live, working application on Render that anyone can use right now.
Zero-Latency UI: The app calculates scores in milliseconds.
What's next for EcoPredict: AI-Driven ESG Emissions Estimation
PDF Parsing: Integrating an NLP layer to scrape Revenue/Headcount directly from Annual Reports (PDFs).
Scope Breakdown: Refining the model to predict Scope 1, 2, and 3 specifically, rather than a composite E-Score.
API Commercialization: Offering EcoPredict as a REST API for integration into existing Bloomberg or Fitch terminals.

Log in or sign up for Devpost to join the conversation.