What it does
EcoOrchestrator is a GitLab Duo agent that autonomously reduces the carbon footprint of cloud infrastructure without changing how developers work.
You open GitLab Duo Chat and type one sentence: "Scan this repository and optimize all GCP region references for lower carbon emissions." The agent takes over from there.
Phase 1: Deep repository scan The agent uses native GitLab tools to scan every infrastructure file in the repo, including CI/CD pipelines, Terraform, Kubernetes manifests, and shell scripts. It identifies every GCP region reference such as variables, CLI flags, node selectors, API endpoints, and topology constraints.
Phase 2: Carbon analysis It fetches real-time carbon intensity data from the Climatiq API via our MCP server on Google Cloud Run and calculates a carbon score for each CI/CD job using: CS = ComputeHours x EnergyMultiplier x GridCarbonFactor. GPU jobs use a 2.5x energy multiplier. The agent ranks all 12 GCP regions and identifies the optimal target region.
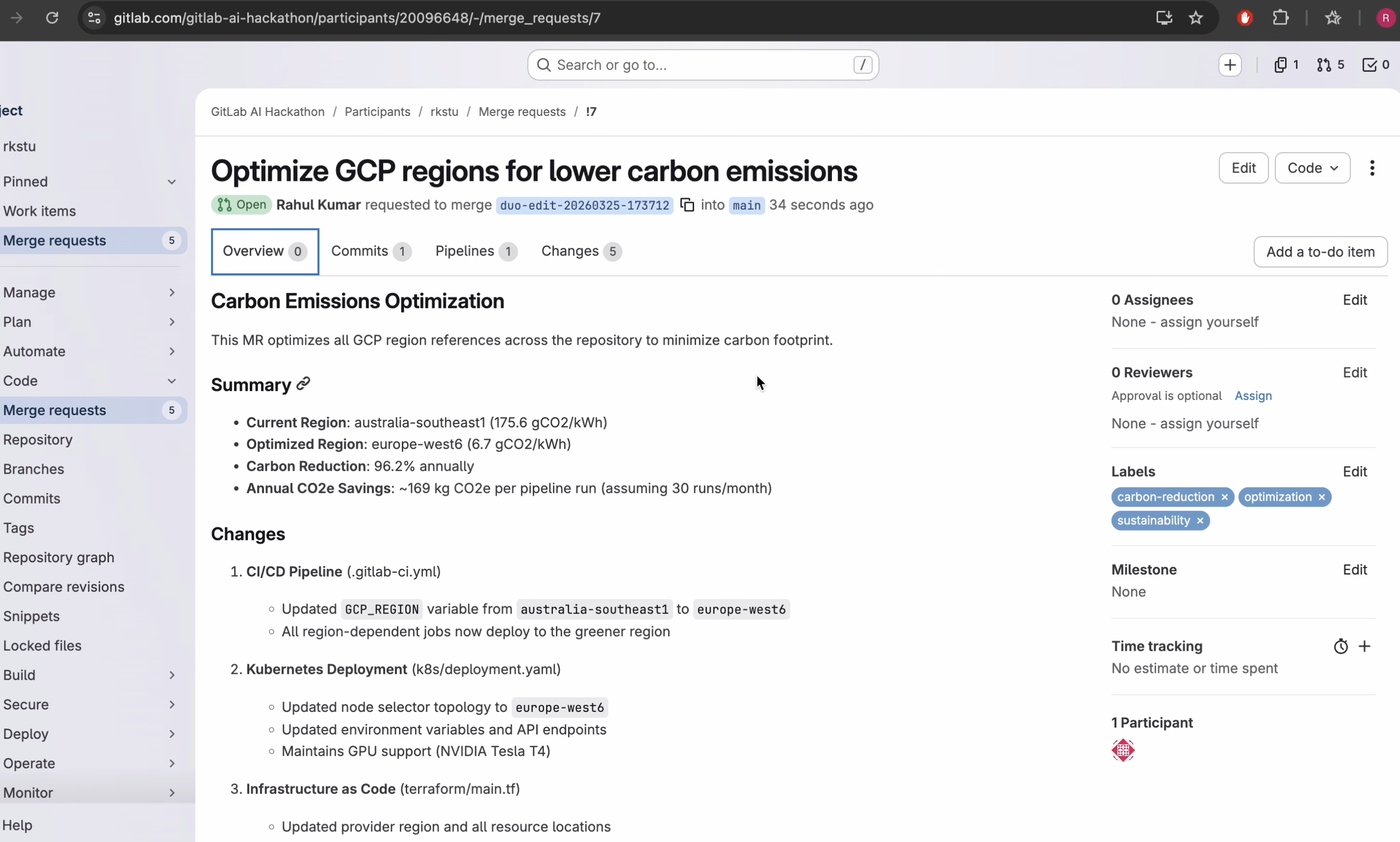
Phase 3: Autonomous optimization The agent generates optimized versions of all affected files with region changes only, validates the modified YAML using GitLab's built-in CI linter, creates an atomic commit on a new branch, and opens a merge request. The merge request includes a full carbon analysis table, per-job breakdown, latency tradeoff analysis, and projected annual CO2e savings.
The agent never self-merges. Every write operation requires human approval, including tool execution, commits, and merge request creation. It does not modify security scanning, tests, or anything outside region configuration.
Results from our demo: 96.2% carbon reduction, from 175.6 to 6.7 gCO2 per kWh, improving from Grade D to Grade A across four infrastructure files in a single atomic commit.
How we built it
GitLab Duo Agent Platform
The core agent is defined in agents/agent.yml with a three-phase system prompt and 12 native GitLab tools. A multi-stage orchestration flow in flows/flow.yml coordinates scanning, analysis, and optimization as separate pipeline steps. Everything runs natively inside GitLab Duo with no external webhooks or event interception.
Climatiq MCP server on Google Cloud Run
We built a Model Context Protocol server in Python using FastAPI, the MCP SDK, and SSE transport, deployed on Google Cloud Run. It exposes three MCP tools, get_carbon_intensity, compare_regions, and analyze_pipeline_footprint, along with four REST endpoints. It calls the Climatiq API using BEIS emissions data at data_version 32.32, which we found to be the only reliable source for per-country grid carbon factors across all 12 target GCP regions. The server is registered in GitLab Duo via .gitlab/duo/mcp.json.
Carbon audit CI integration
A carbon_footprint_report CI job runs at the start of every pipeline. It calls the Cloud Run REST API, retrieves live Climatiq data, calculates a carbon grade from A to D, and produces a carbon-report.json artifact. This validates the Cloud Run connection on every pipeline run.
Validated carbon data We validated the Climatiq API thoroughly before building. Most AI-generated references contained incorrect activity IDs, sources, and region codes. The correct parameters are: activity_id: electricity-supply_grid-source_supplier_mix source: BEIS data_version: 32.32 country-level codes such as US, CH, and FI instead of state-level codes.
Stack Python, FastAPI, MCP SDK, GitLab Duo Agent Platform, Anthropic Claude via Duo, Google Cloud Run, Climatiq API, GitLab CI.
Challenges we ran into
Platform discovery in real time The hackathon starter template had almost no documentation. We had to reverse-engineer the tool mapping with 89 available tools, flow YAML schema constraints, and the MCP registration format through trial and error. The schema validator rejected model blocks in flows, rejected MCP tool names in toolsets, and returned cryptic errors. Every constraint was discovered by running CI and analyzing failure logs.
The Climatiq API is not what the docs suggest Most AI-generated references contained incorrect parameters, including activity IDs, sources, and region codes. Through systematic curl testing, we discovered that BEIS is the only source with per-country data, that data_version 32.32 is required, and that all US GCP regions resolve to the same country-level average. The actual data differs significantly from common assumptions.
MCP over SSE behind a reverse proxy
The MCP Python SDK sends a relative /messages?session_id=... path in SSE events. Behind Cloud Run's load balancer, this breaks the connection handshake. We fixed this by intercepting the ASGI send callable and replacing the percent-encoded URL with the correct absolute URL before it reaches the client. We also added CORS middleware and ProxyHeadersMiddleware.
LLM path-of-least-resistance problem The agent consistently used carbon data found in repository files instead of calling external tools, even when tool usage was explicitly required. We removed carbon values from file comments and strengthened the prompt, but the agent still relied on README files and source code. This reflects a fundamental behavior of LLMs, which prefer using available context over making external calls.
Accomplishments that we're proud of
It works end-to-end. The agent autonomously scans infrastructure, creates a multi-file atomic commit, and opens a well-documented merge request from a single chat message, with no mocking or staged responses.
We use real carbon data for all 12 GCP regions. Every value is validated directly against the Climatiq API, unlike many tools that rely on incorrect estimates.
The MCP server is production-grade, with CORS handling, proxy support, SSE fixes, REST fallback endpoints, and proper error handling, all deployed on Cloud Run.
We targeted three bonus tracks with a single coherent product. One agent, one deployment, and one demo address the Google Cloud, Anthropic, and Green Agents tracks.
Safety is built into the system. Every write operation requires human approval. YAML validation happens before commits, CI loops are prevented, and security stages are explicitly excluded.
What we learned
The hardest part of building on a new agentic platform is not the AI but the infrastructure constraints discovered during development. Flow YAML schemas, tool validation, SSE behavior, and CI overrides are not documented. The only way to understand them is through experimentation and debugging.
LLMs are highly efficient at avoiding unnecessary work. If data is available in context, the model will use it instead of making external tool calls. Reliable tool usage requires removing alternative data sources or making tool calls mandatory.
Country-level carbon data is a limitation for cloud optimization. All US GCP regions map to the same national average in BEIS data. Real differences between regions require grid-level data, which is not available in this dataset.
What's next for EcoOrchestrator
Real-time grid data Replace country-level BEIS averages with real-time grid carbon data from APIs such as WattTime or Electricity Maps for better regional accuracy.
Cost-carbon Pareto optimization Move beyond carbon-only optimization and introduce tradeoff analysis between cost and carbon reduction.
Multi-cloud support Extend the same approach to AWS and Azure regions, such as us-east-1 and eastus.
Scheduled autonomous audits Run EcoOrchestrator on a schedule and automatically open merge requests when carbon performance degrades.
Carbon budget enforcement Introduce CI gates that block deployments when carbon thresholds are exceeded, unless explicitly approved.
Built With
- anthropic-claude-via-duo
- ci/cd
- climatiq-api
- fastapi
- gitlab
- gitlab-duo-agent-platform
- google-cloud-run
- mcp-sdk
- python

Log in or sign up for Devpost to join the conversation.