We used multi agent reinforcement learning as we did not have test data, we wanted to optimise using a number of parameters for multiple agents dependent on each other.
Dynamic visualisation to show the user the specific new predicted
What it does
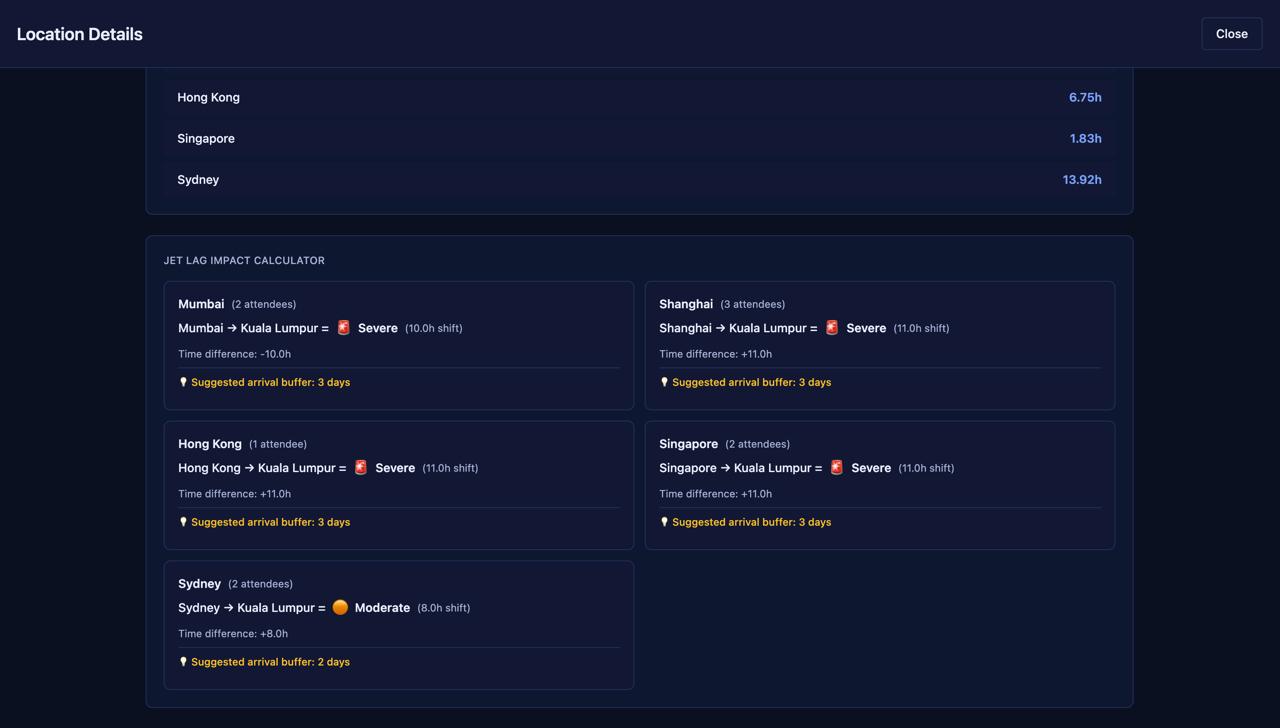
The environment learned a policy using PPO, to maximise the reward which included factors such as CO2 emissions, travel time, availability
The action space are the airports (including the offices)
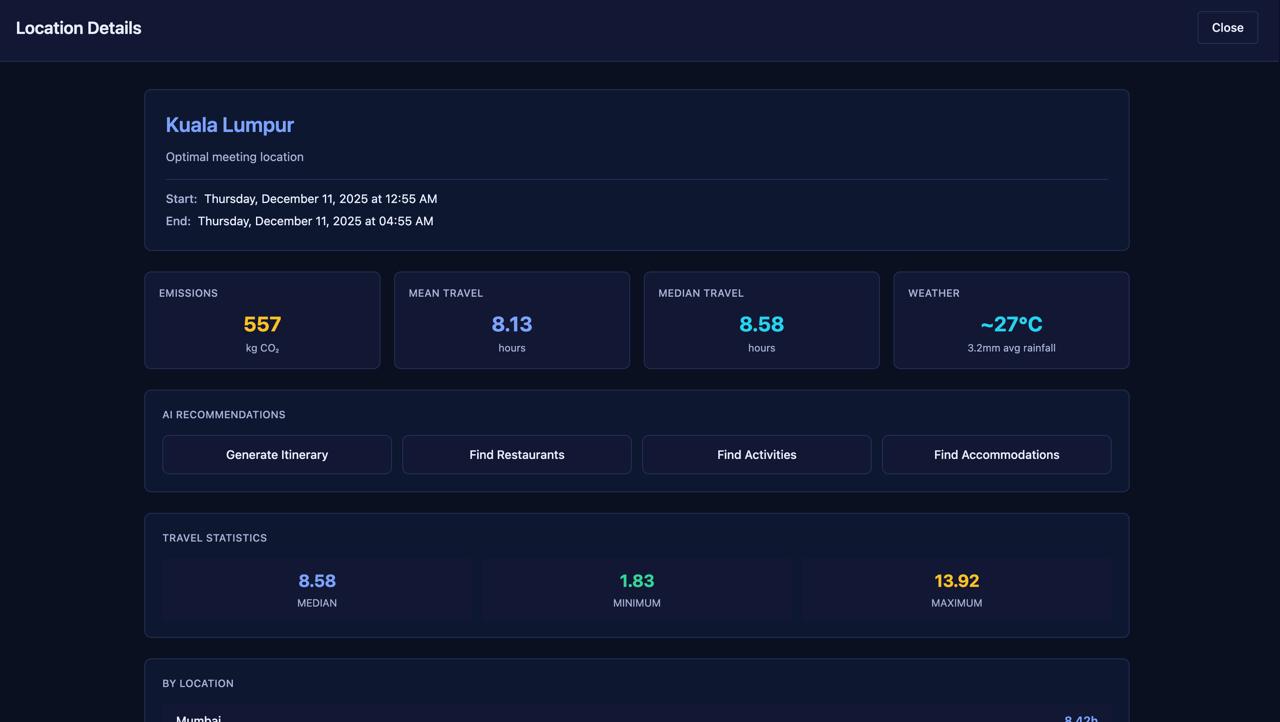
Model compiled and outputs the optimal destination dependent on the factors at current state.
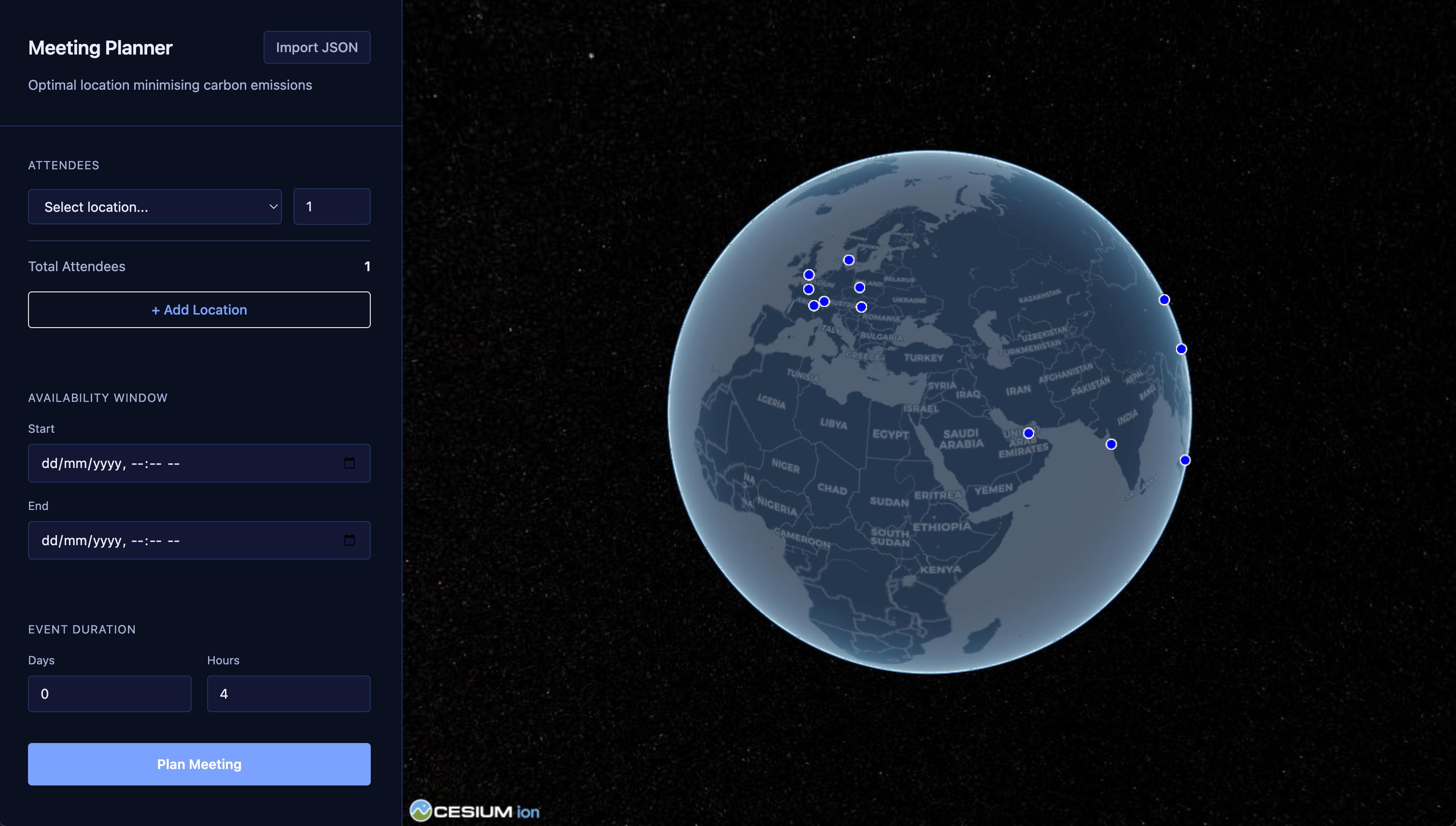
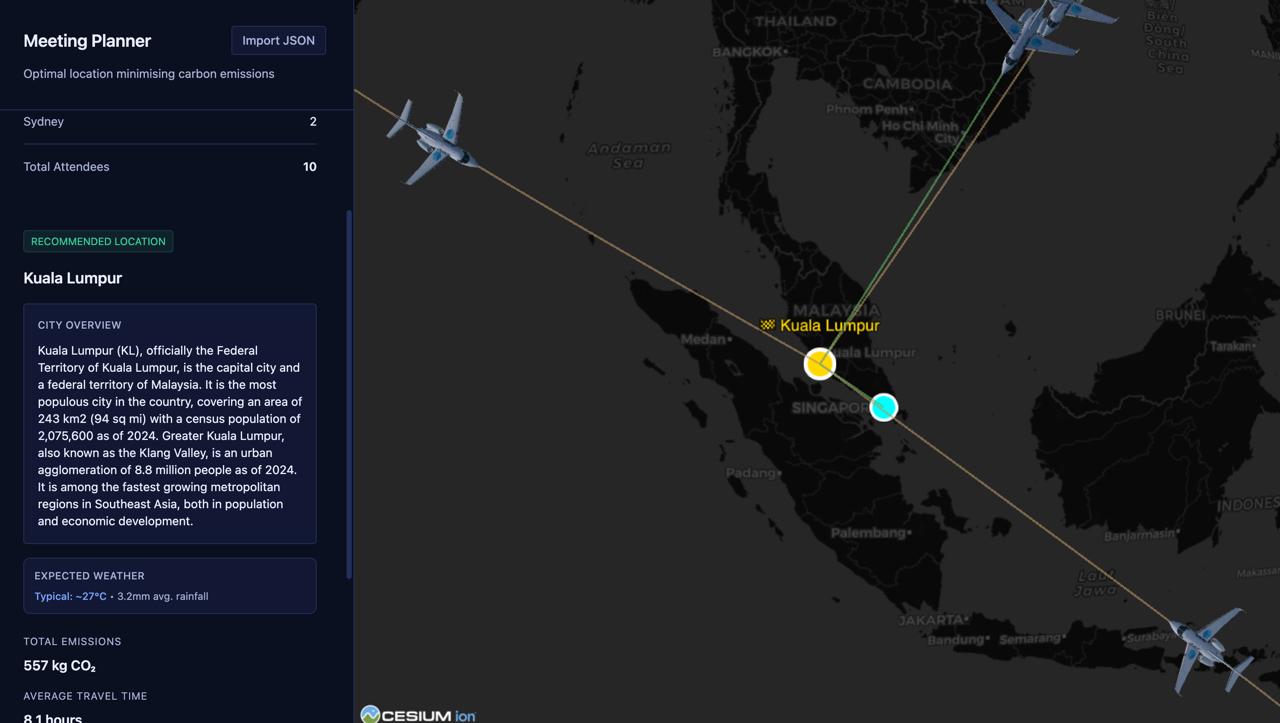
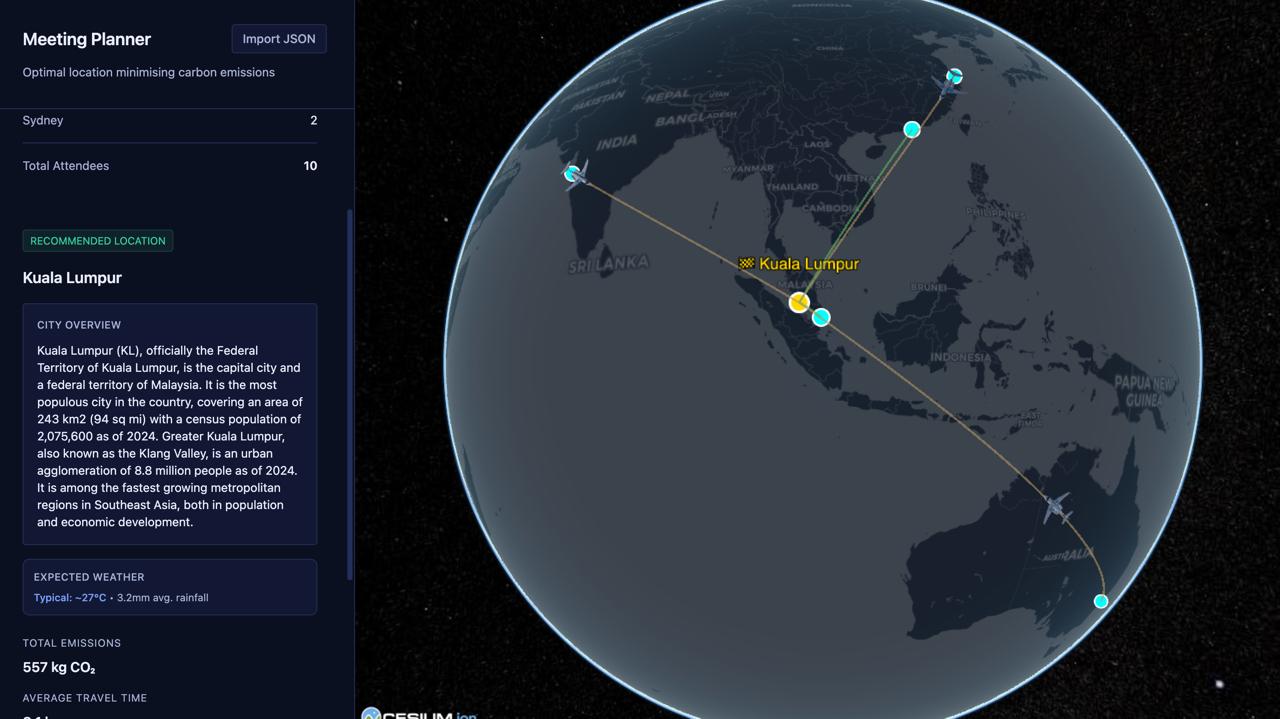
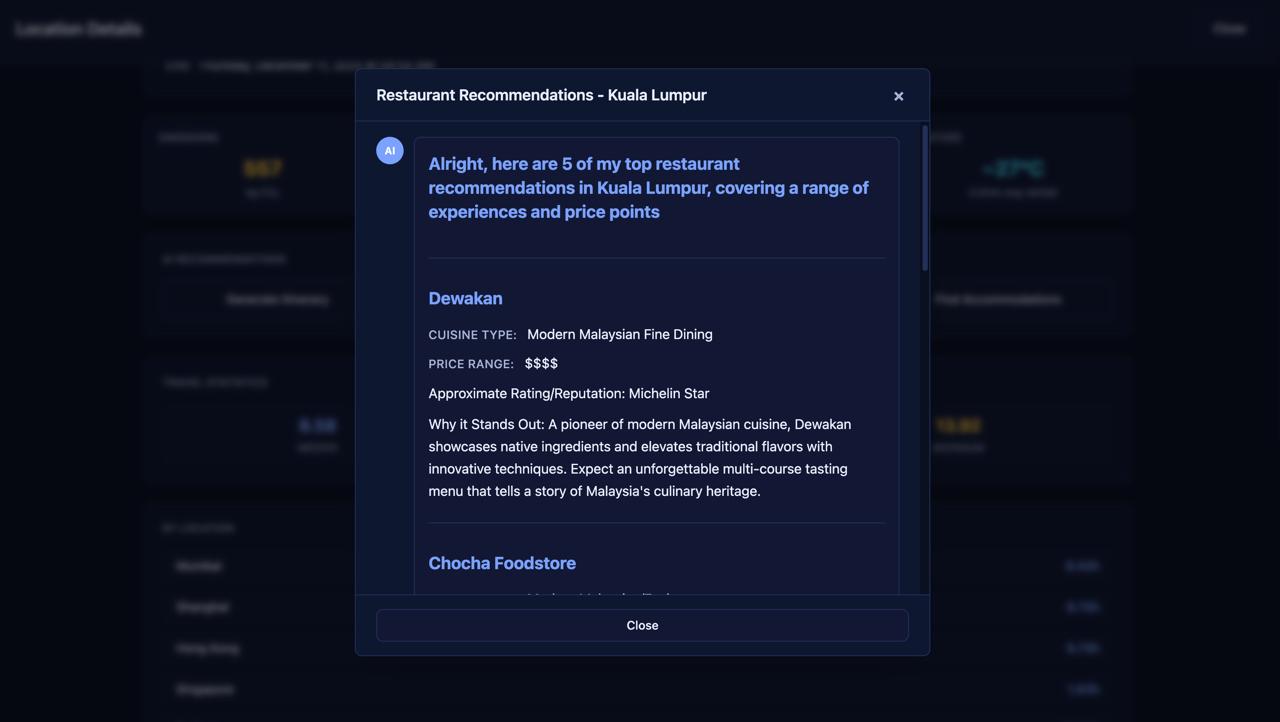
Front end shows flight paths, 3D globe visualisation with markers for QRT offices as the initial state and output is model response in output JSON format.
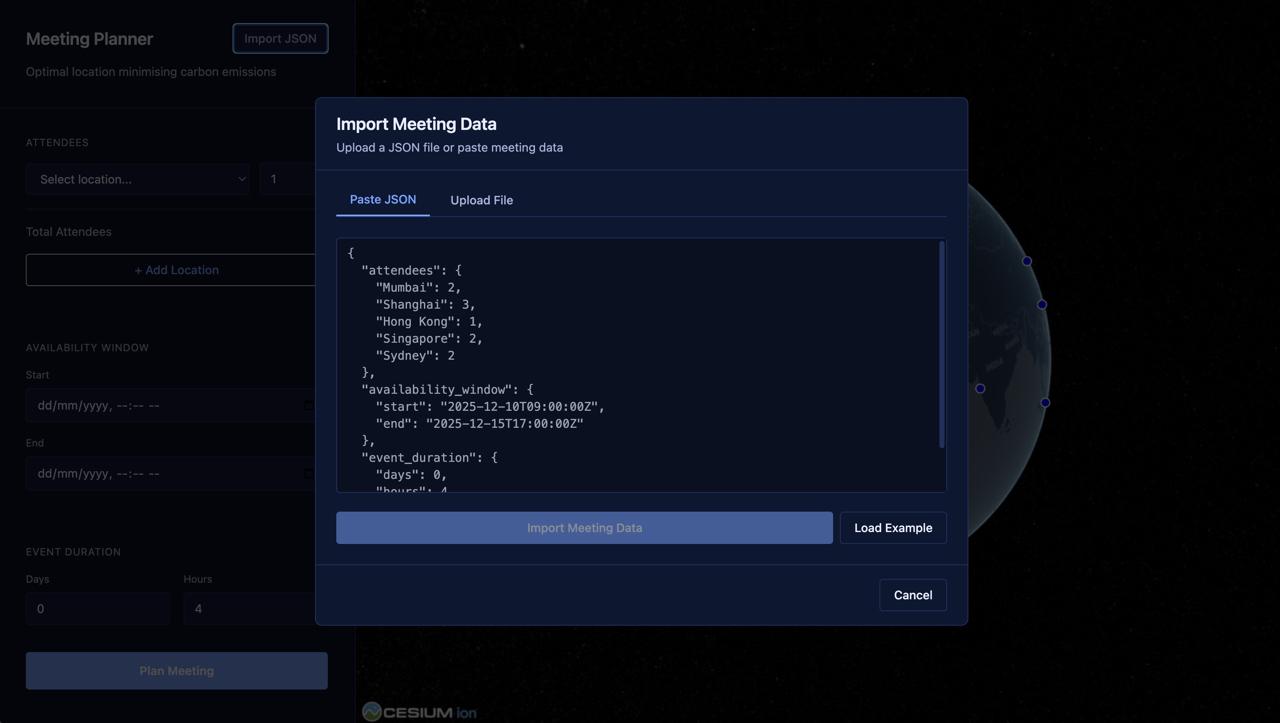
Backend handles the post request of input JSON, preprocesses the JSON and then passes into the model, then constructs the output JSON including the exact coordinate of the airport.,





Log in or sign up for Devpost to join the conversation.