-
-
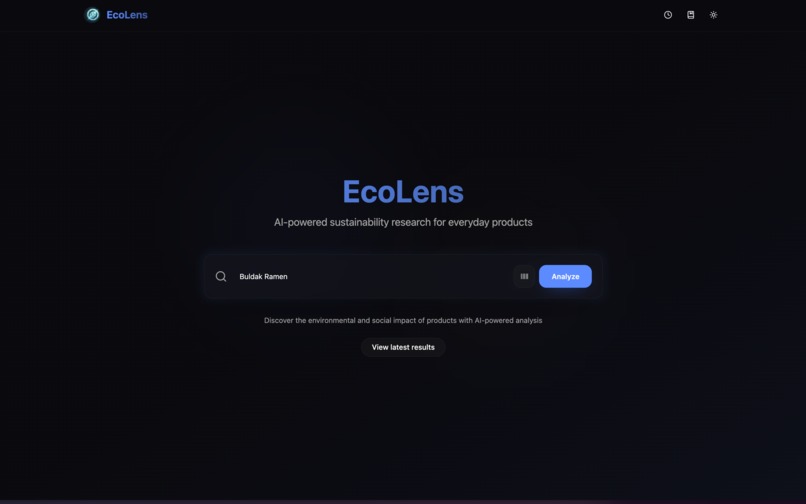
Search Products
-
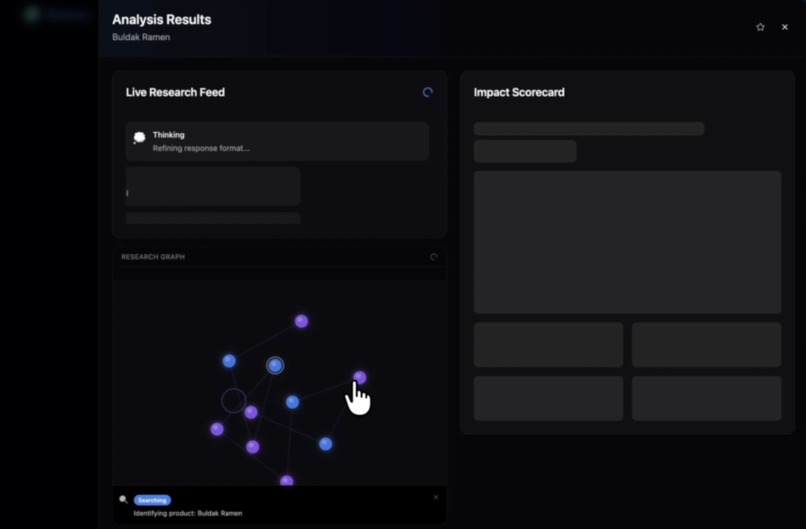
Detailed Graph View
-
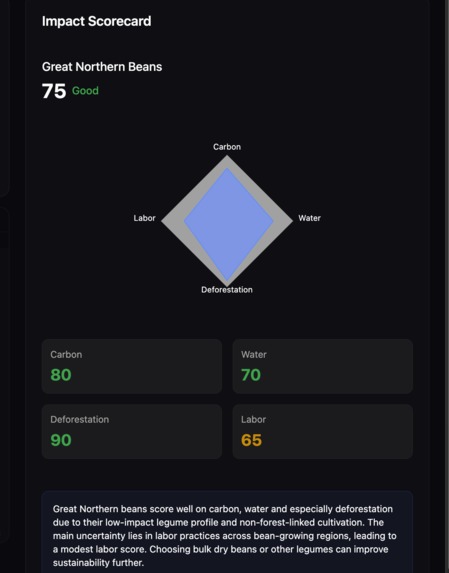
Detailed Analysis
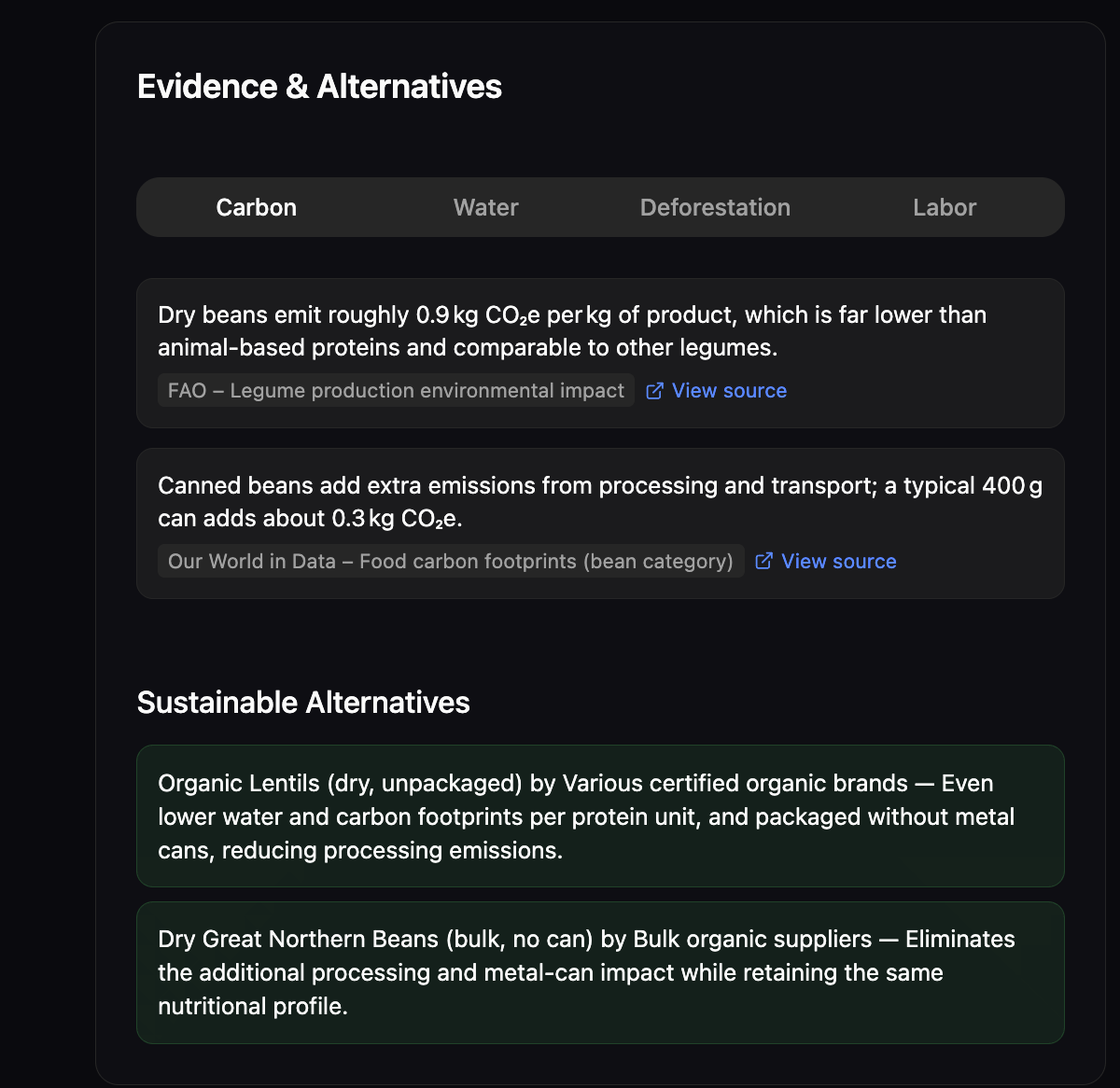
-
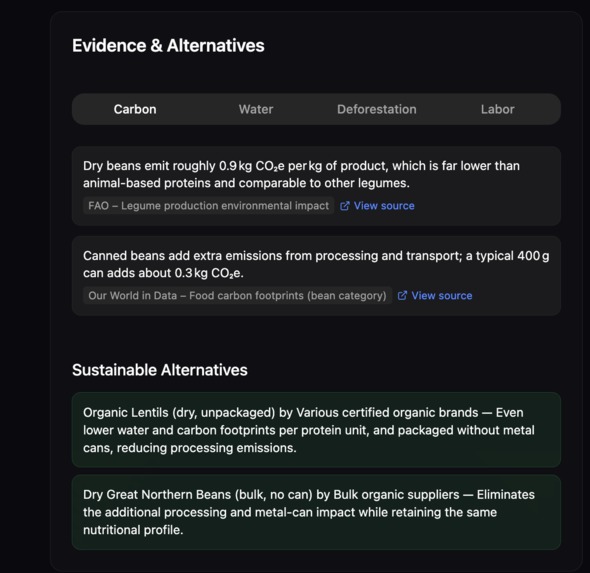
Evidence Based Suggestions
-
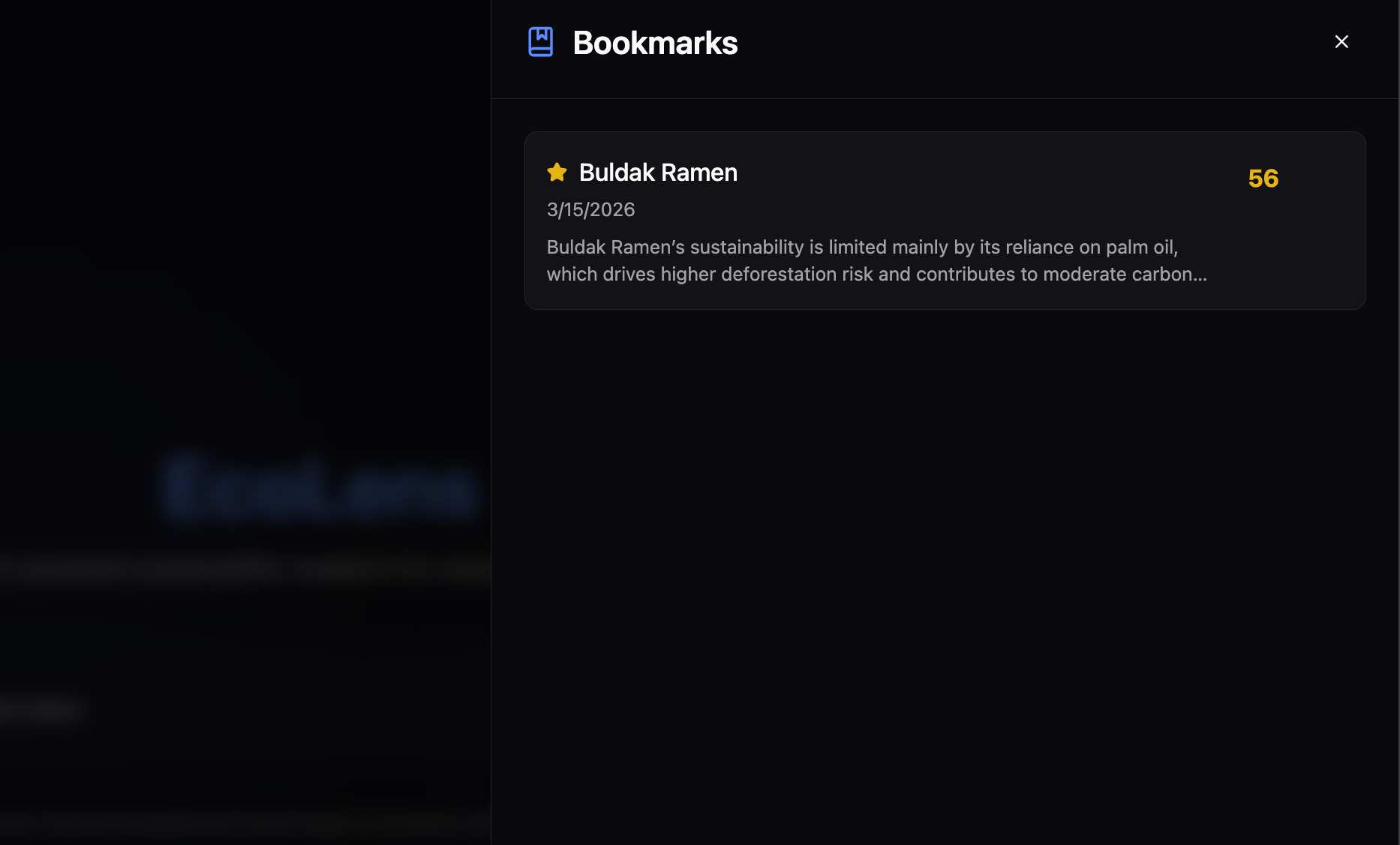
Bookmark Favourites
EcoLens — Project Story
Inspiration
Every day, billions of purchasing decisions are made with almost zero information about their real-world impact. Labels tell you calories and ingredients — they don't tell you that your chocolate bar's palm oil contributed to Indonesian deforestation, or that the cocoa was harvested under exploitative labor conditions. Sustainability data exists, but it's scattered across NGO reports, brand disclosures, academic lifecycle assessments, and paywalled databases. No single consumer can synthesize all of that for every product they buy.
We wanted to build the tool that does it for them — not a calculator with hardcoded estimates, not a chatbot that guesses, but an AI that actually researches the product, reads the sources, and shows its work.
What it does
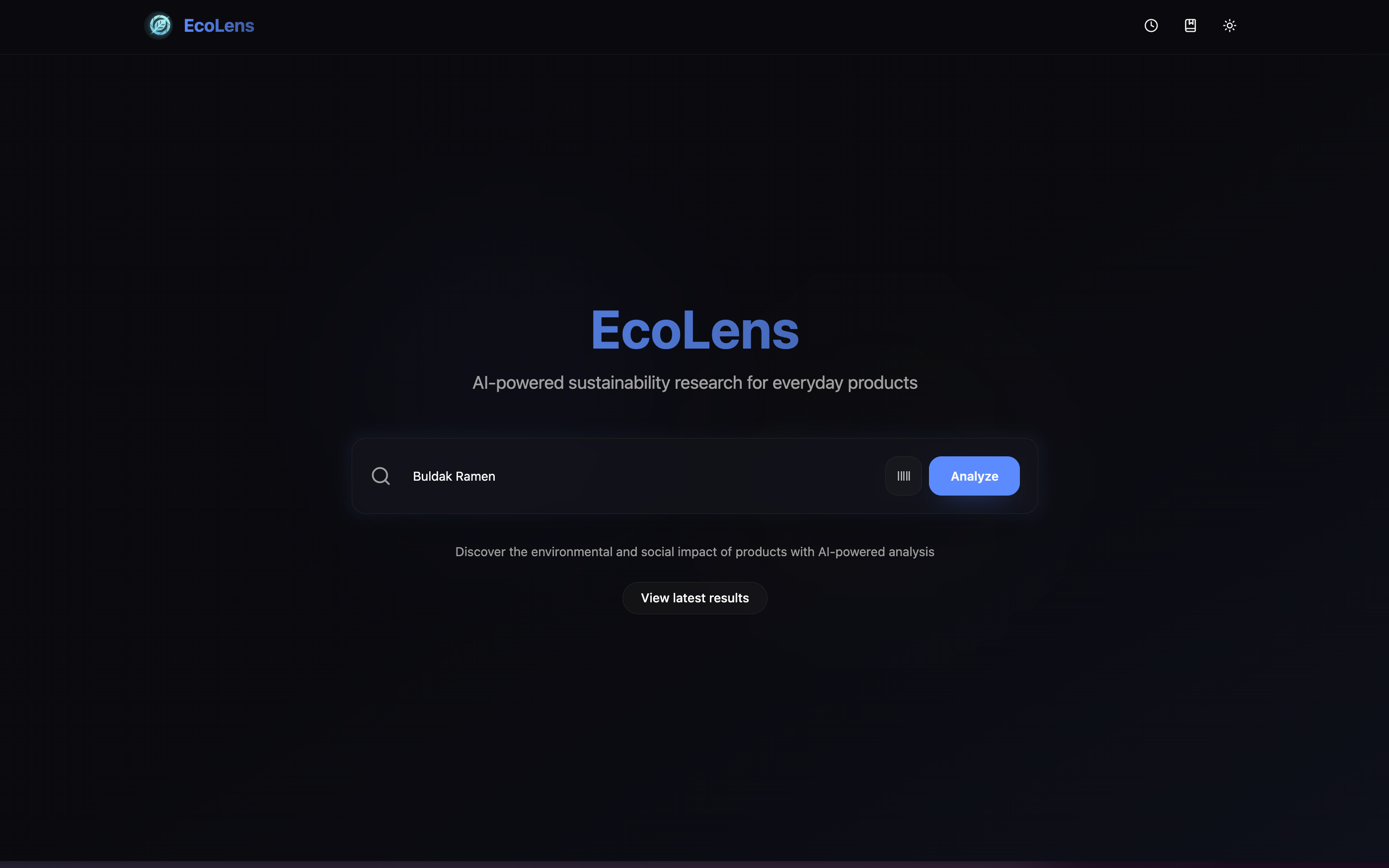
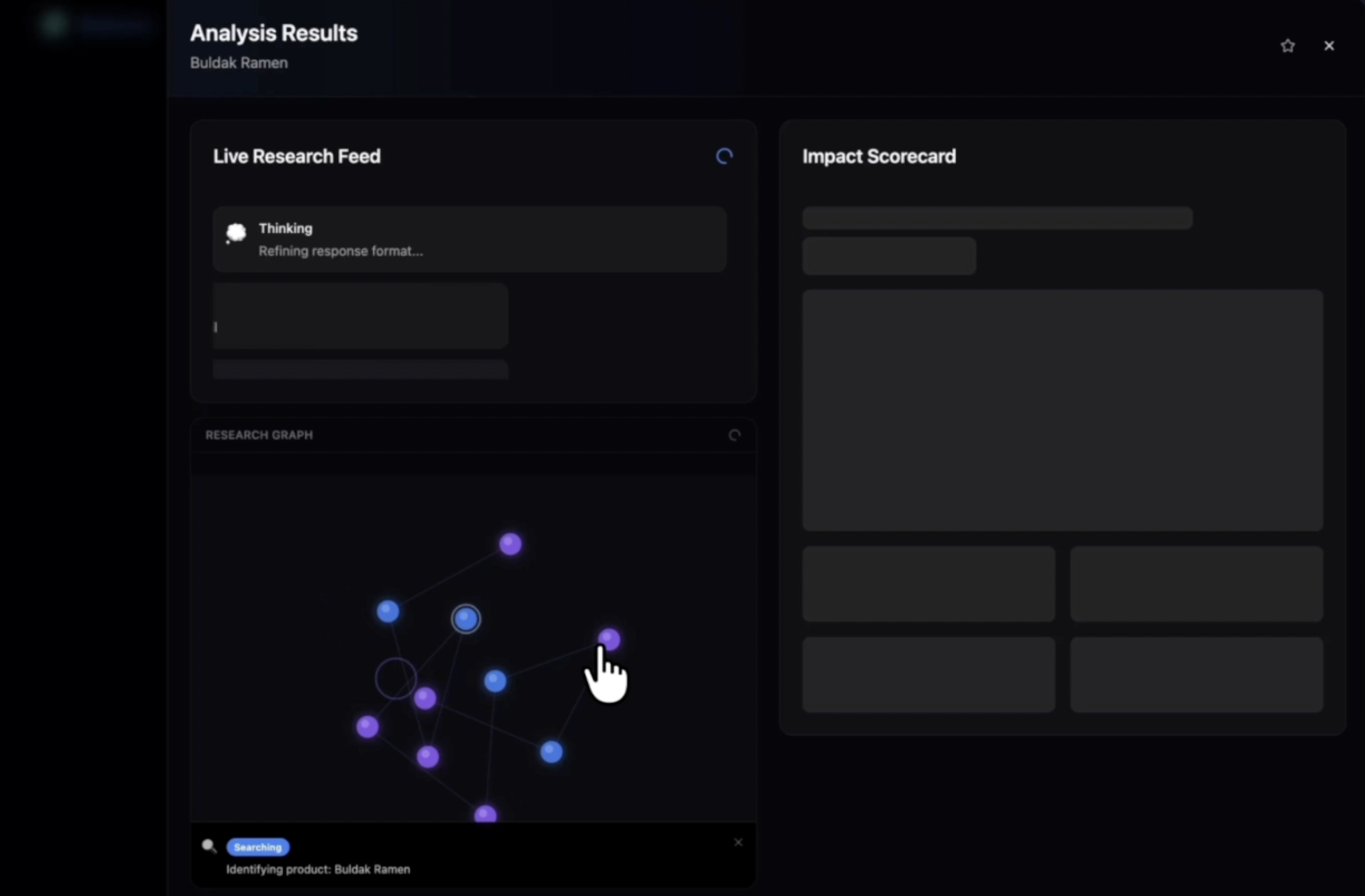
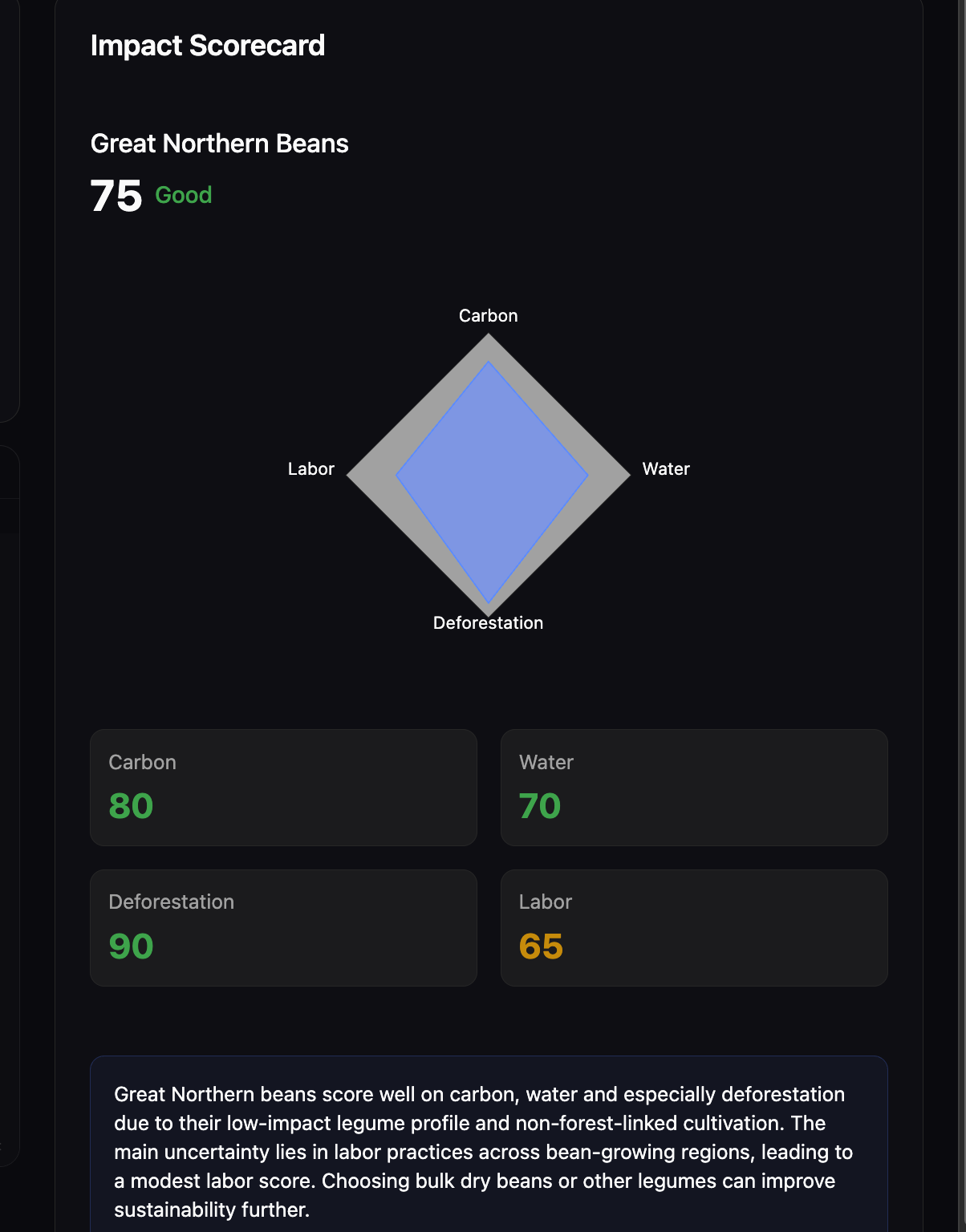
EcoLens is an AI-powered sustainability research agent. You type any product name — Nutella, Big Mac, running shoes — or scan any product barcode with your camera, and a live research agent autonomously investigates it across four dimensions:
| Dimension | What it captures |
|---|---|
| Carbon | Production emissions, transportation, lifecycle GHG |
| Water | Freshwater consumption in production |
| Deforestation | Ingredient links to forest clearing (palm oil, soy, beef) |
| Labor / Ethics | Supply chain labor conditions (cocoa, cotton, shrimp) |
Every score is backed by cited evidence with source links. If there isn't enough data, the agent reports insufficient_data rather than inventing a number. While it works, you watch it in real time: a live research feed streams each step as it happens, and a force-directed node graph builds itself as evidence is gathered — each node is a research event you can click to inspect.
How we built it
Stack: FastAPI · GPT-OSS 120B · Open Food Facts API · DuckDuckGo web search · React + Vite + Tailwind · Server-Sent Events
The core architectural decision was to use an AI agent rather than a static data pipeline. Sustainability data is incomplete, paywalled, and inconsistent across product categories. Instead, we designed GPT-OSS as the pipeline itself — it reasons about what to search for, calls tools to fetch live evidence, and synthesizes a structured report.
The agent loop:
User query
→ identify_product() # Open Food Facts — brand, ingredients, category
→ lookup_ingredient_impact() # local table — 60+ ingredients, EN + FR
→ search_web() # DuckDuckGo — live sustainability news & reports
→ fetch_page() # extract evidence text from URLs
→ synthesize + score # evidence objects → dimension scores
→ stream SSE events # frontend renders in real time
Scoring model
Each of the four dimensions produces a raw score $s_d \in [0, 10]$ from the agent, where $10$ is most sustainable. The frontend maps this to a 0–100 display scale:
$$S_d = \lfloor s_d \times 10 \rfloor$$
The overall score is a confidence-weighted average across all four dimensions:
$$S_{\text{overall}} = \frac{\sum_{d=1}^{4} w_d \cdot S_d}{\sum_{d=1}^{4} w_d}$$
where the confidence weight $w_d$ is drawn from the agent's self-reported confidence level:
$$w_d = \begin{cases} 1.0 & \text{high} \ 0.6 & \text{medium} \ 0.3 & \text{low} \ 0.0 & \text{insufficient_data} \end{cases}$$
This means dimensions without reliable evidence are down-weighted rather than anchoring the overall score with a meaningless default.
Evidence-based confidence
The agent is forbidden from emitting a score without attached evidence. Confidence for each claim is derived from:
$$ c = f!\left(n_{\text{sources}},\ q_{\text{source}},\ \delta_{\text{agreement}}\right) $$
where:
- $n_{\text{sources}}$ is the number of corroborating sources.
- $q_{\text{source}}$ rates source quality (NGO report $>$ news article $>$ blog).
- $\delta_{\text{agreement}}$ penalises contradictory sources.
In practice:
- $n \geq 3$ agreeing quality sources → high
- $n \in [1, 2]$ or mixed quality → medium
- $n = 0$ → insufficient_data (no score emitted)
Results are cached in SQLite with a 24-hour TTL. A full analysis history is persisted locally and surfaced in the UI.
Challenges we ran into
The model doesn't support native function calling. The GPT-OSS endpoint returns tool_calls: [] on every request — we discovered this mid-build from debug logs showing finish_reason: stop. The fix was a complete agent rewrite using prompt-based tool calling: the system prompt teaches the model to emit {"action": "tool_name", "args": {...}} as plain JSON, which we parse and dispatch ourselves. This makes the agent portable across any LLM endpoint.
Blocking the event loop killed SSE. The original implementation used the synchronous OpenAI client inside an async generator. Every LLM API call blocked uvicorn's event loop for $$ t \approx 10\text{–}30\text{ s} $$, preventing SSE bytes from flushing. The browser received a stalled then abruptly-closed chunked stream (ERR_INCOMPLETE_CHUNKED_ENCODING). Switching to AsyncOpenAI with await resolved it entirely.
OpenFoodFacts returns French ingredient names. European product pages return ingredients like lait, boeuf, blé — none of which matched our English-only lookup table, causing every fallback score to collapse to $$ S_d = 50 $$. We expanded the table with French aliases and rewrote the matcher to normalise labour → labor and use prefix matching, so "Labor & Ethics" and "Labour" both resolve correctly.
Coordinating parallel development. We built on a feature branch (waleedsearch) off a teammate's active branch (search) to avoid merge conflicts. All new functionality went into new files; shared files received only additive changes.
Accomplishments we're proud of
- A research agent that works on any product in any category — food, fashion, electronics — not limited to a pre-loaded database
- Barcode scanner — point your phone camera at any product in a store and instantly trigger a full sustainability analysis, no typing required
- Every score traceable to a cited source the user can click and verify
- A force-directed research graph that assembles in real time — latency becomes a feature, not a flaw
- A prompt-based tool-calling architecture that works reliably without native function-calling support
What we learned
- Agents beat pipelines when data is messy. A live research agent that admits uncertainty is more honest and more impressive than a calculator with stubbed values.
- Stream everything. The SSE research feed turned a ~20-second wait into a compelling demo.
- Prompt engineering is systems engineering. Getting a model to reliably emit structured JSON, know when to stop calling tools, and fall back gracefully required as much design thought as the backend architecture.
- Scope deliberately. Cutting from 6 dimensions to 4 produced higher confidence scores, lower latency per query, and a cleaner product.
What's next for EcoLens
- Category comparison — parallel agents race to analyze 5 products simultaneously, producing a live-updating sustainability leaderboard
- Personal impact calculator — if you buy this product once a week for a year, your additional carbon burden is approximately:
$$ \Delta C_{\text{annual}} = 52 \times m_{\text{unit}} \times \text{EF}_{\text{product}} \quad [\text{kg CO}_2\text{e}] $$
where:
- $m_{\text{unit}}$ is the product mass.
$\text{EF}$ is the emission factor per kg derived from the agent's carbon score.
Browser extension — surface sustainability scores inline while shopping on Amazon, Instacart, or any retailer
Built With
- beautifulsoup4
- css
- fastapi
- gpt-oss
- httpx
- openai
- pydantic
- python
- react
- runtime
- shadcn/ui
- sqlite
- sse-starlette
- tailwind
- typescript
- vite


Log in or sign up for Devpost to join the conversation.