-
-
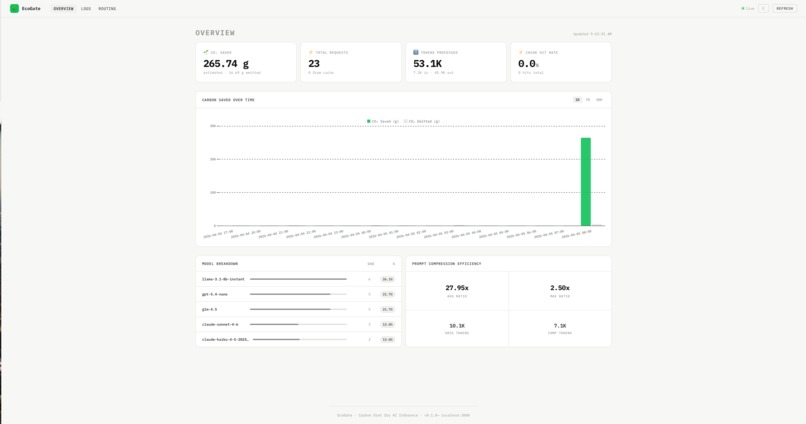
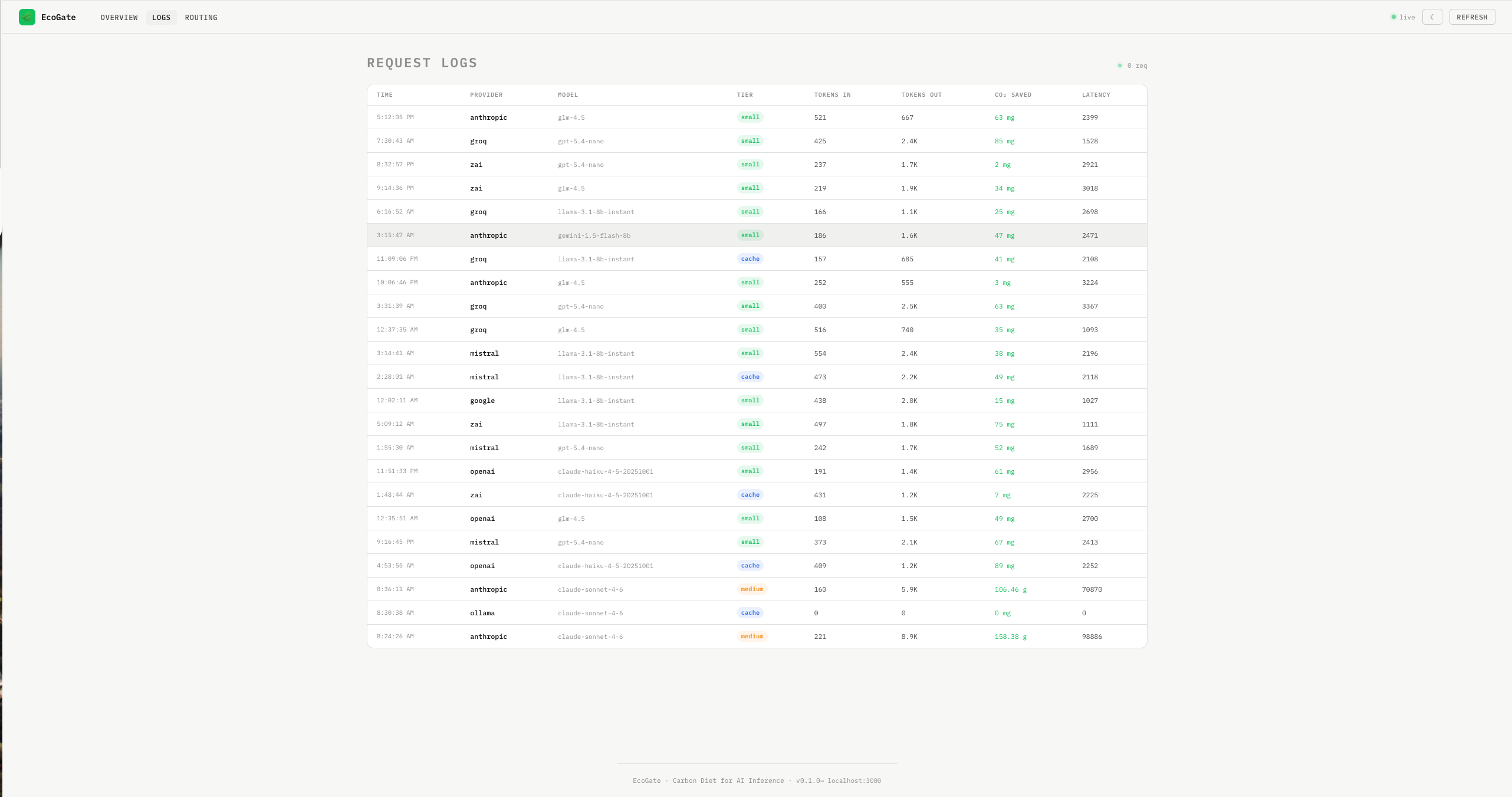
Request Logs Page
-
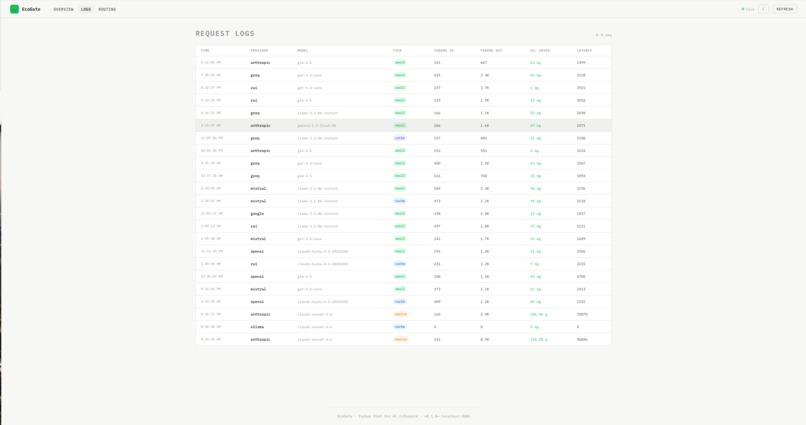
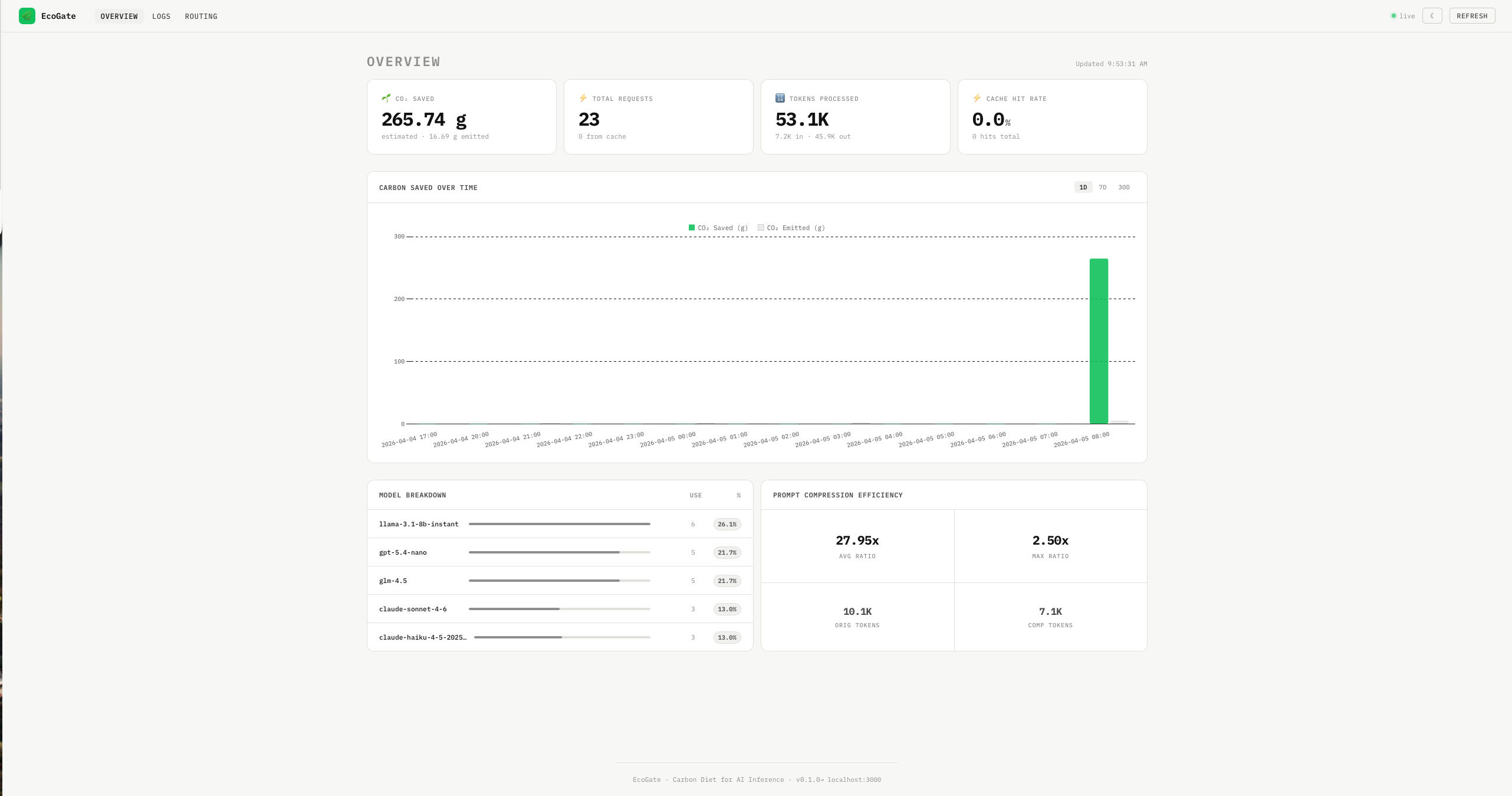
Overview Page
-

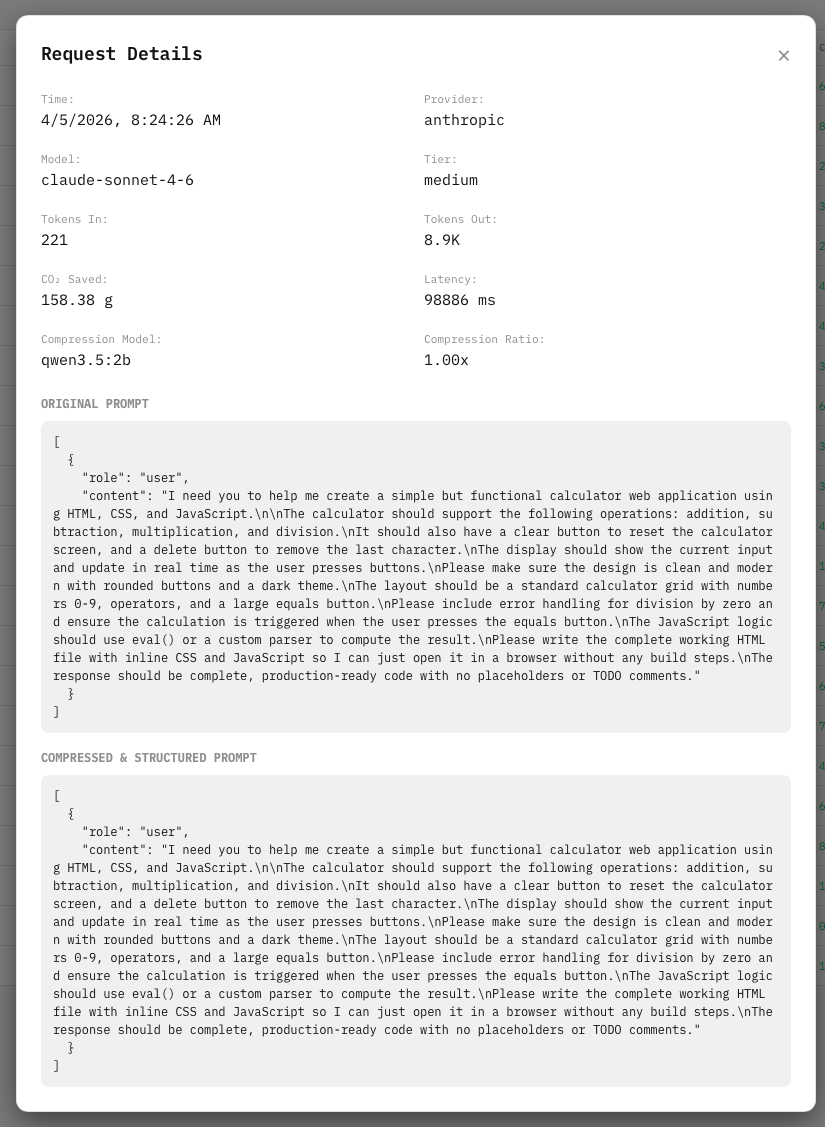
Prompt Session Detail
-

Routing Page
EcoGate: The Sustainable AI Inference Proxy
Built by Vedang Sharma and Aarti Harish Nemade for Innovation Showcase 2
Inspiration
As developers rapidly adopt Large Language Models (LLMs) to power modern web applications, two massive problems have emerged: skyrocketing API inference costs and an increasingly alarming carbon footprint. Every unnecessary token processed by massive, energy-heavy models contributes to inefficient cloud spending and environmental impact. We wanted to build a solution that allows teams to scale AI sustainably—optimizing token consumption and environmental cost without forcing developers to switch ecosystems or sacrifice output quality.
What it does
EcoGate is an intelligent, drop-in LLM proxy gateway. Instead of sending raw user prompts directly to expensive AI providers, EcoGate intercepts the request and routes it through a specialized prompt compression pipeline. By stripping away redundant words, fixing coreferences, and semantically distilling the prompt, EcoGate dramatically shrinks the payload before forwarding it to your specified provider (like OpenAI, Google, or Z.AI).
Coupled with a sleek React-based dashboard, EcoGate visualizes real-time metrics including Prompt Compression Efficiency, per-model API usage, and most importantly, the aggregate Carbon Saved Over Time. It acts as an invisible layer that speeds up inference, cuts costs, and saves the planet.
How we built it
The core of our gateway is an asynchronous Node.js proxy server responsible for dynamic request routing, tracking analytics via SQLite, and serving our React + Recharts dashboard. To achieve maximum prompt optimization, we built a custom, synchronous Python sidecar and orchestrated local models using Ollama.
Our core innovation runs on a Three-Stage Compression Pipeline:
- Deterministic NLP Pipeline: The prompt first enters our Python sidecar where it undergoes strict deterministic tasks: coreference resolution, redundancy detection, sentence compression, and stop-word removal.
- LLMLingua-2 Model: Next, the cleaned text is passed through the LLMLingua-2 model for powerful, context-aware, token-level compression.
- Local Qwen: Finally, we route the distilled context to a locally hosted, small-footprint
qwen3.5:2bmodel to align and perfectly format the compressed prompt into a strict JSON intent before it is finally fired off to the target LLM API.
We also built an interactive, terminal-based CLI setup tool that pulls the required Ollama Modelfiles and manages environment dependencies automatically, ensuring a seamless developer experience out of the box.
Challenges we ran into
Our biggest challenge was ensuring that our extreme token compression didn't degrade the core intent or logic of complex user requests.
At first, we tried simply prompting a small local LLM to "compress this prompt," but it was slow, inconsistent, and sometimes hallucinated different instructions. Our "aha!" moment came when we realized we couldn't just rely on an LLM. Integrating a strict, deterministic NLP pipeline before feeding the data into the LLMLingua-2 model was the breakthrough we needed. This hybrid approach allowed us to mathematically guarantee that core entities and intent variables were preserved while the LLM efficiently handled the semantic heavy lifting.
We also faced deep architectural challenges in bridging our fast, asynchronous Node.js HTTP proxy with the synchronous, computationally heavy Python NLP sidecar while maintaining low overall network latency.
Accomplishments that we're proud of
- Engineering a highly effective three-stage hybrid compression pipeline that reliably cuts token usage without destroying prompt logic.
- Building a completely frictionless developer experience via our interactive CLI that handles everything from API keys to downloading our custom "thinking-disabled" local LLM weights.
- Creating a beautiful metrics dashboard that translates abstract API interactions into real, understandable environmental impact (visualizing carbon savings $kgCO_2$).
What we learned
Building EcoGate deepened our understanding of the mathematical and linguistic nature of LLM tokenization. We learned how different embedding spaces (like LLMLingua-2 versus Qwen models) "read" distilled text, and we became highly proficient in orchestrating local inference through Ollama side-by-side with external cloud endpoints. Most importantly, we learned that combining deterministic algorithms with generative AI often yields much faster and more reliable results than relying on AI alone.
What's next for EcoGate
Looking ahead, we plan to shift away from generalized local models and completely fine-tune a smaller model specifically dedicated to prompt compression. This will allow us to bypass general-purpose intent models entirely, further driving down local latency.
Additionally, we are expanding our dashboard to include live metrics for project-specific cost tracking, allowing enterprise teams to actively monitor their API budgets and carbon footprint segment-by-segment in real time.


Log in or sign up for Devpost to join the conversation.