-
-
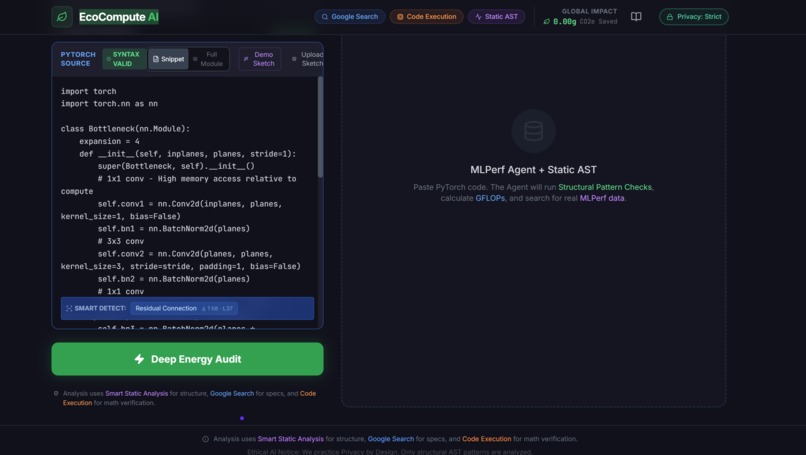
EcoCompute AI: Your virtual Performance Engineer. Uses Gemini 3 to see, search, and verify energy optimizations for your AI models.
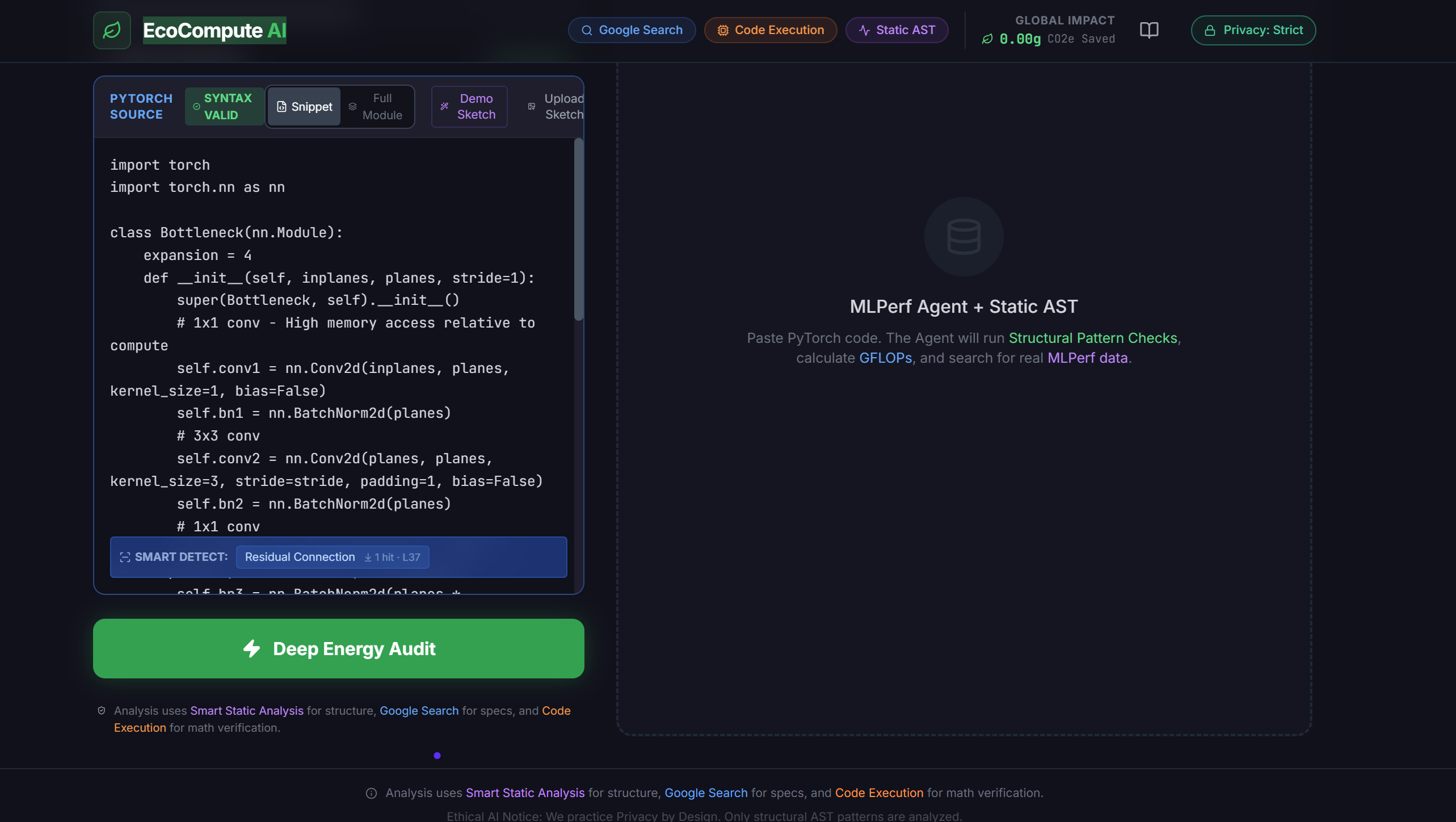
Inspiration The Problem: Training a single AI model emits as much carbon as 5 cars over their lifetime—but for enterprises, the real pain is Cloud Bill Shock. Monitoring tools like Datadog see the symptoms (high CPU); we see the root cause (inefficient code). We asked: What if we could place a "Virtual Senior Performance Engineer" inside the CI/CD pipeline? One that not only blocks expensive code but also explains the ROI to the CFO? Enter EcoCompute V38. We moved beyond a simple linter to build a complete Green FinOps Infrastructure powered by Gemini 3. What it does EcoCompute AI is a Predictive Gatekeeper for AI Engineering. Intercepts: It acts as a GitHub Action / CI Gate, scanning PyTorch PRs (supporting everything from ResNet-50 to Llama 3). Grounds: It searches Google for real-time 2026 hardware specs (e.g., NVIDIA B200) to calculate precise Cloud Cost impacts. Calibrates: It uses a "Scientific Calibration" method—first verifying its physics engine against known baselines (MLPerf) before analyzing novel architectures. Verifies: It uses a Python Sandbox to mathematically prove "Arithmetic Intensity" (FLOPs/Byte), eliminating LLM math hallucinations. Refactors: It automatically generates optimized code (Quantization, Operator Fusion) to cut inference costs by 30-50%. Consults (New V38 Pilot): An interactive Wisdom Pilot that translates technical metrics into financial strategy, helping VPs and CFOs understand why an optimization matters. How we built it (The V38 Hybrid Engine) We de-risked AI optimization by combining Neuro-symbolic Verification with a Tiered Cost Architecture: The V38 Tiered Architecture (L1/L2/L3): To ensure positive unit economics, we built a smart router: L1 (Static Gate): Instant Regex/AST checks ($0 cost). L2 (Flash Router): Gemini Flash-Lite handles documentation & simple fixes ($0.001 cost). L3 (Deep Reasoning): Gemini 3 Pro is reserved for complex architectural changes, utilizing its 1024-token thinkingBudget to plan audits and verify math. Scientific Calibration Strategy: To address the critique that "LLMs don't know physics," we implemented a calibration loop. The agent grounds itself on public MLPerf data (ResNet-50) to determine error margins before predicting the energy usage of complex custom models. Agentic Tool Use: Google Search: Used to find dynamic data like "Carbon Intensity of Iowa Data Centers" or "H100 On-demand Pricing". Code Execution: Used to calculate FLOPs. We force the agent to write Python code to verify its own assumptions. Challenges we ran into Hallucination vs. Physics: LLMs are notoriously bad at arithmetic. We solved this by forcing Gemini 3 to use the Code Execution sandbox for all FLOPs/Byte calculations, effectively giving the LLM a calculator. Balancing Token Costs: Running a large reasoner model on every line of code is expensive. The V38 Architecture solves this by routing 80% of traffic to cheaper layers (Static/Flash), saving the heavy lifting for Gemini 3 Pro. Visualizing "Thinking": Streaming the raw "thought process" (e.g., "Checking MLPerf DB...") to the UI without breaking the JSON output required a custom stream parser. Accomplishments that we're proud of Scientific Rigor: We don't just guess; we provide Error Bars and Confidence Scores based on real MLPerf data. Measurable Impact: In our demo, we achieved 32.8% energy reduction on Llama 3 GQA blocks, translating to $12.50 saved per 1M inferences on NVIDIA H100. The "Dual-Persona" Interface: We built a tool that speaks Code to engineers (via PR Comments) and Money to executives (via the V38 Pilot), bridging the gap between DevOps and FinOps. What's next for EcoCompute AI Dynamic Tracing: Integrating torch.fx to capture complex dynamic graphs beyond static analysis. Enterprise Pilot: Onboarding 3-5 design partners from FinTech and Autonomous Driving sectors. IDE Plugin: Bringing the "Green Gatekeeper" directly into VS Code for real-time energy linting. Let's Code Green & Lean!
Built With
- apis
- gemini3


Log in or sign up for Devpost to join the conversation.