-

The logo of the EcoCheck
-
Initial look of the web app
-
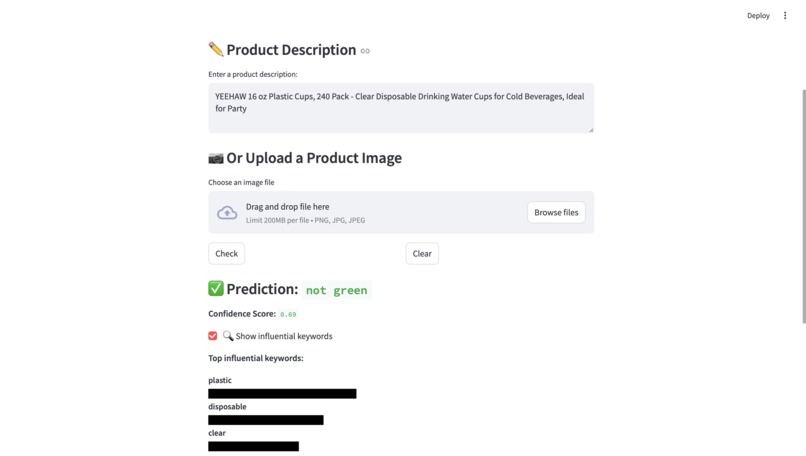
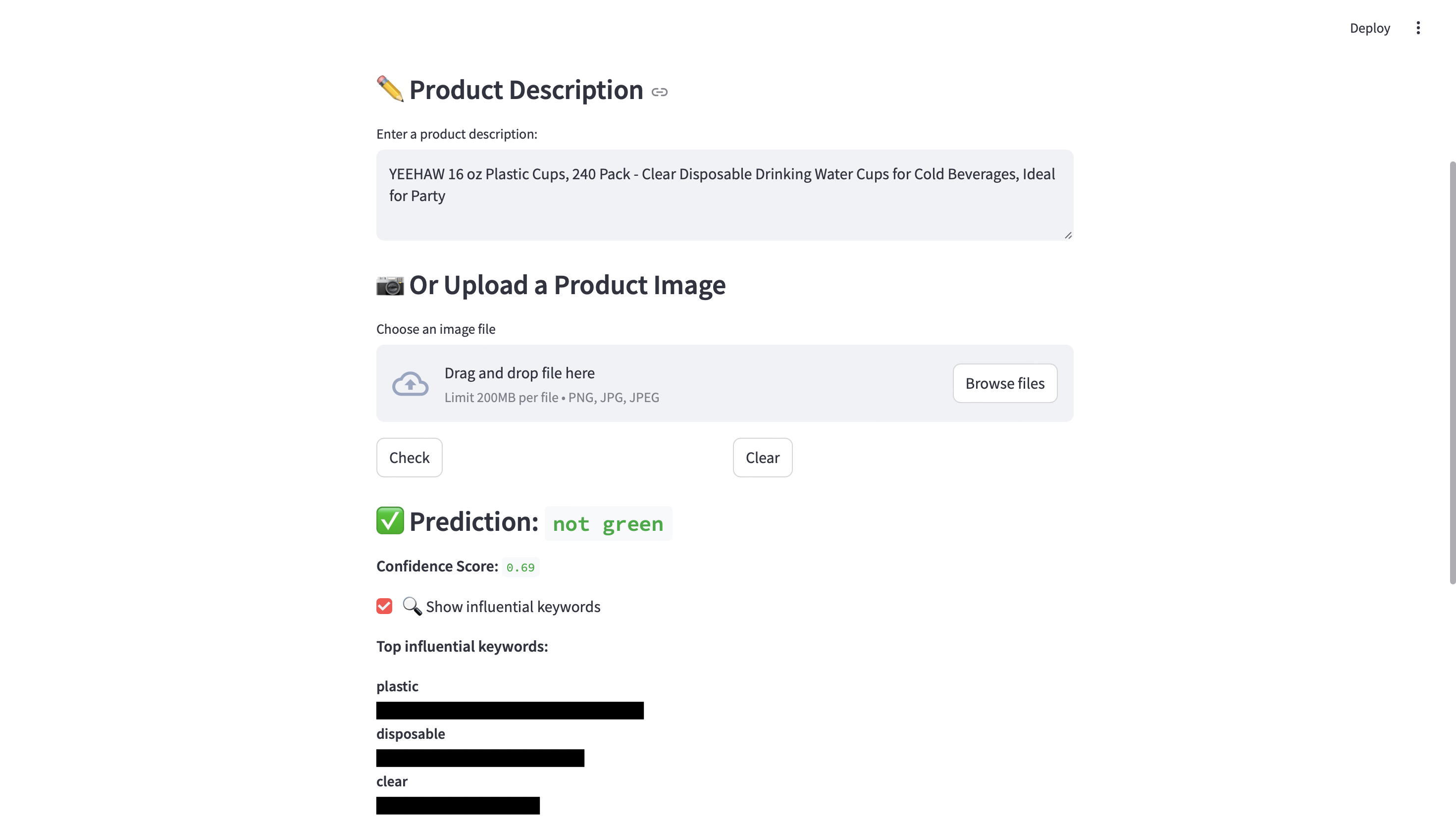
Output looks like this
-
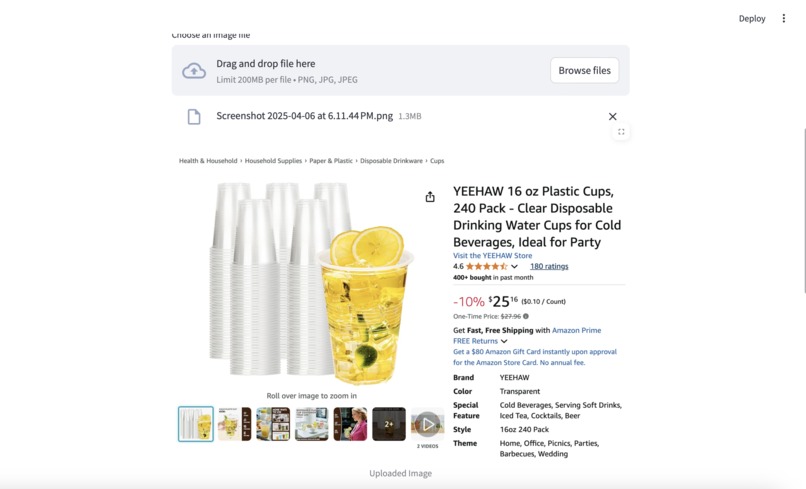
User can upload the image

Introduction
The development of EcoCheck began with the question of what efforts individuals can make to overcome the ongoing environmental pollution and climate crisis, and what methods can be used to support them. Recently, many consumers are interested in environmental protection and are looking for eco-friendly products when purchasing goods. However, I think many consumers, including myself, do not know exactly what criteria are used to determine whether a product is environmentally friendly. Is compostable plastic environmentally friendly? What does "FSC Certified" mean?
What inspired me
I became interested in this issue, and since I am majoring in data science, I decided to build a machine learning model that can predict which products are actually eco-friendly or not based on the product name and description data from actual shopping malls. By using natural language processing to identify terms often used to describe environmentally friendly and non-environmentally friendly products, I wanted to make the program available to more people to evaluate the environmental friendliness of various products more easily.
How I built it
I trained a logistic regression classifier on a custom dataset from real product names and descriptions on websites like Amazon, Target, and Walmart. I carefully handled multi-word phrases (like “plastic-free”) to preserve meaning and ensure more accurate keyword detection. The app was built using Streamlit and features OCR text extraction from product images, a visual explanation of keyword influence (bar chart), and a clean, friendly UI.
What I learned
- How to build an NLP pipeline with TF-IDF and logistic regression
- How to clean and expand real-world datasets for binary classification
- How to implement phrase-aware preprocessing
- How to use OCR with Streamlit
- How to make model decisions more explainable and human-friendly (by adding visual explanation of keyword influence and adjusting UI)
Challenges I faced
One big challenge was making the dataset manually, as I could not find the proper open dataset for this project. Especially, the issue that I took a lot of time to solve is that words like “plastic” or “eco” appeared in both "green" and "not green" products, especially when phrases like “plastic-free” were split into separate words. I fixed this by creating custom preprocessing that converted phrases into single tokens (e.g., “plastic-free” → “plastic_free”) so the model could treat them more accurately. This improved both the performance and the explainability of the model. (Currently, the accuracy of the logistic regression model I use is about 84%.)
Accomplishments
- Built a full machine learning pipeline from scratch
- Created and cleaned a labeled dataset of green and not-green product descriptions
- Implemented phrase-aware text preprocessing
- Allowed users to input product descriptions easily
What's next
- Add special effects or animations when the analysis results are available (when the time comes)
- AI-applied model
- Distinguish eco-friendly marketing (products that are not actually eco-friendly)
- Describe the eco-friendliness of the product, and recommend alternative products
- Background function (so that it can be used when shopping on other apps/websites)



Log in or sign up for Devpost to join the conversation.