-
-
eco gpt LLM answer
-
add scientific paper
-
home page
-
Inspiration
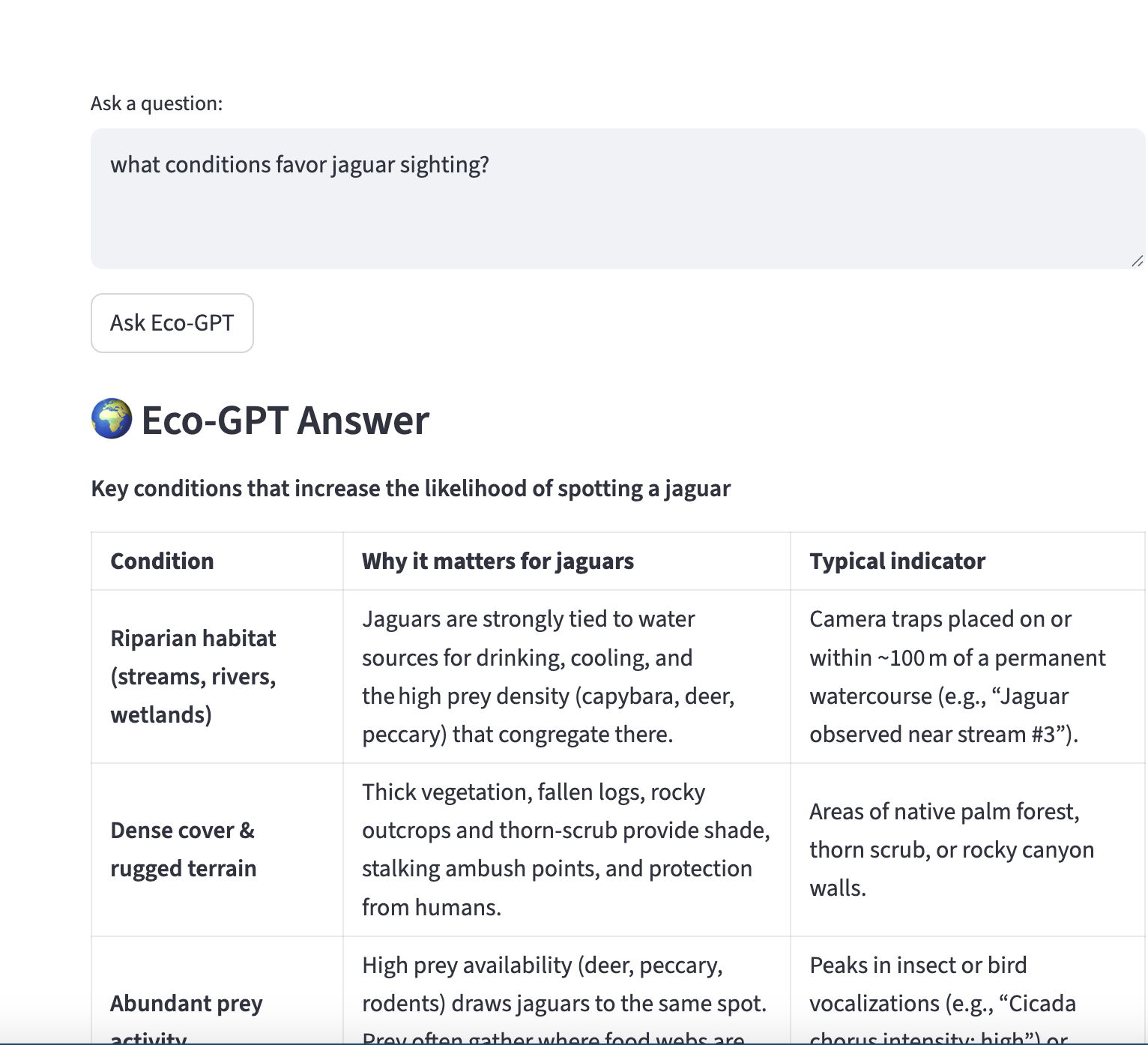
Can great Researchers provide services for conservation efforts in the wildlife .For conservation teams , getting running updates on happenings in the ground matters can influence decisions. It can be used to create the conservation balance and was Inspired by Gpt -oss model design environment, part of a team of international researchers from studies show the benefits of developing conservation.
What it does
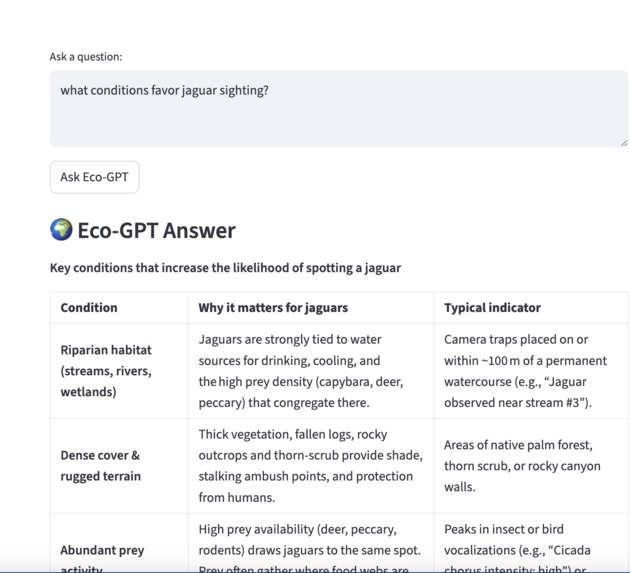
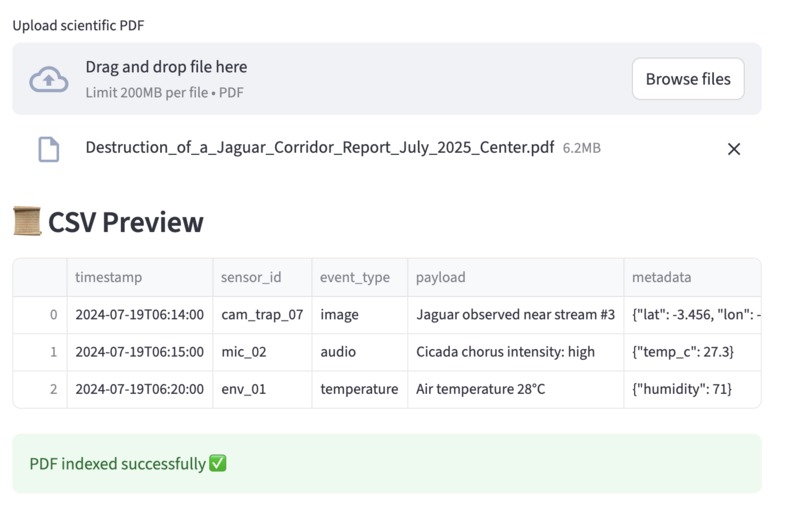
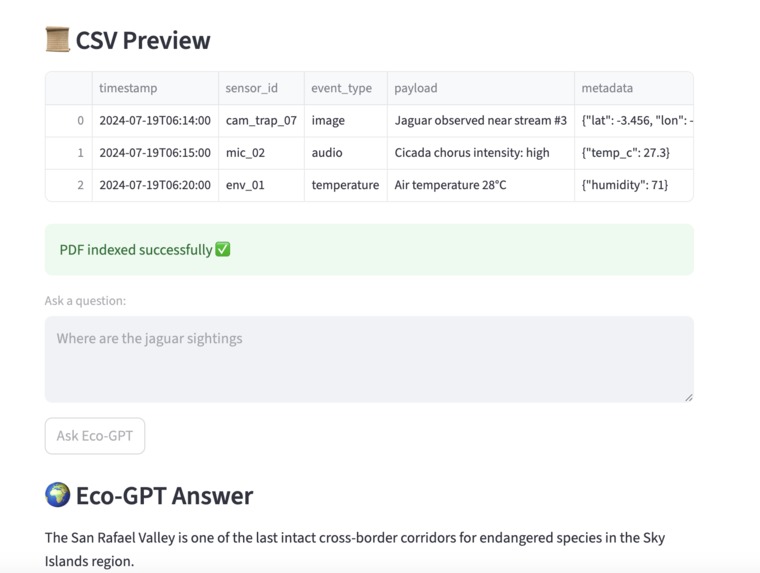
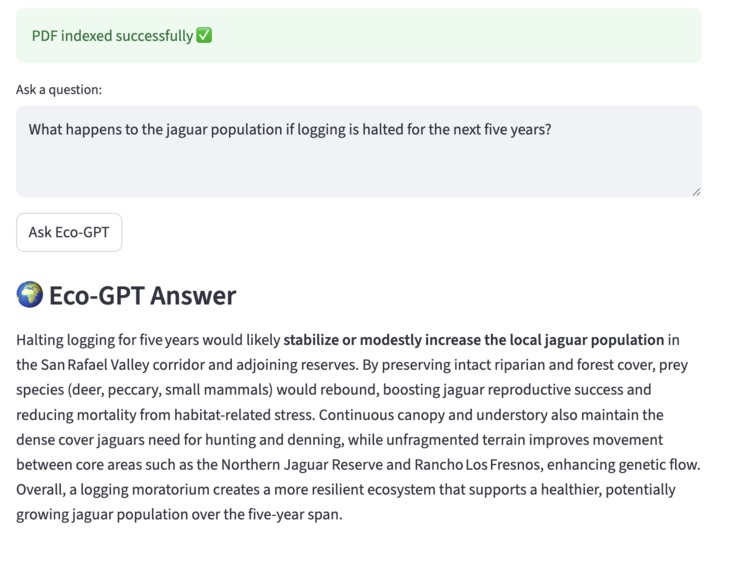
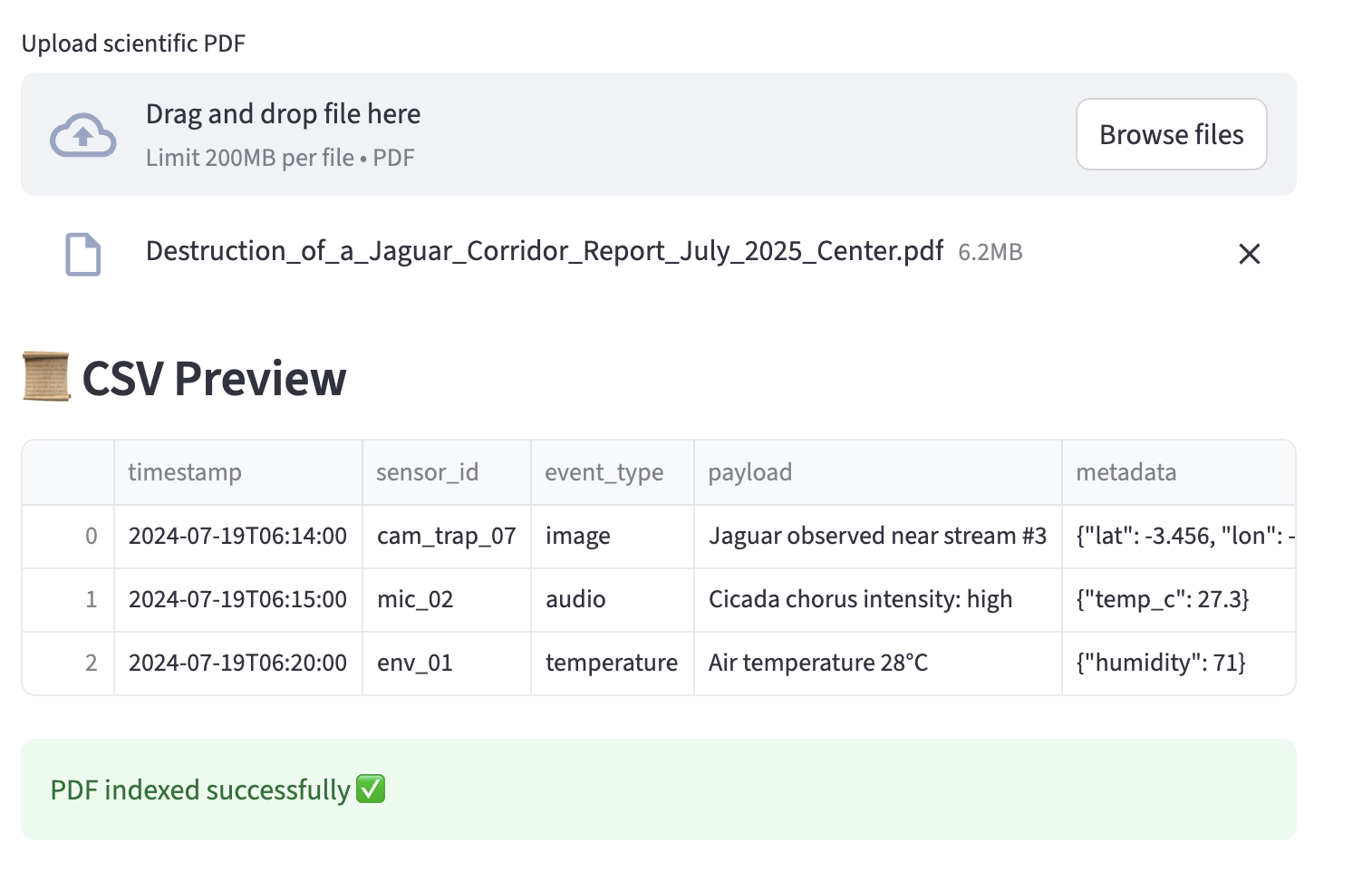
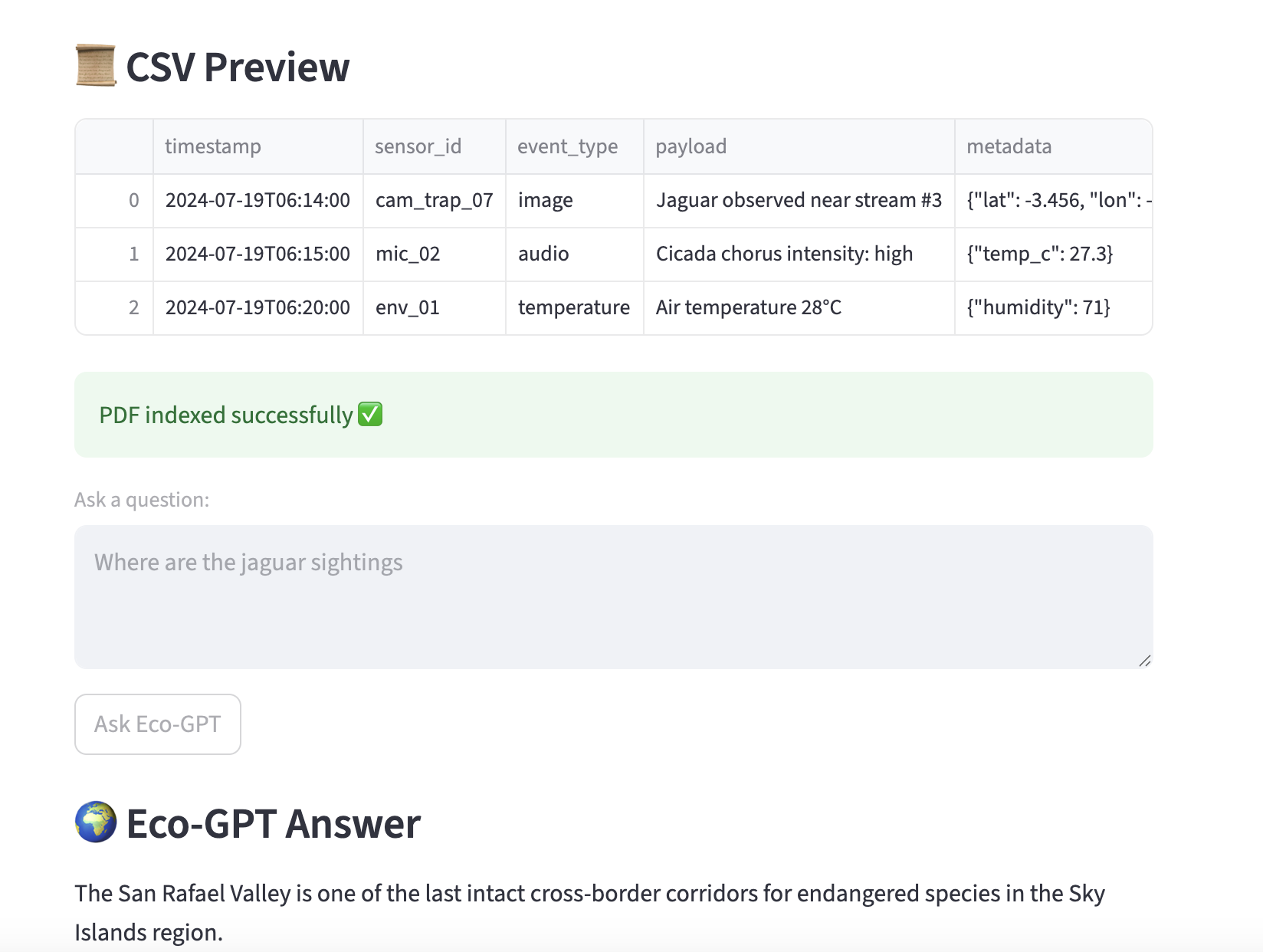
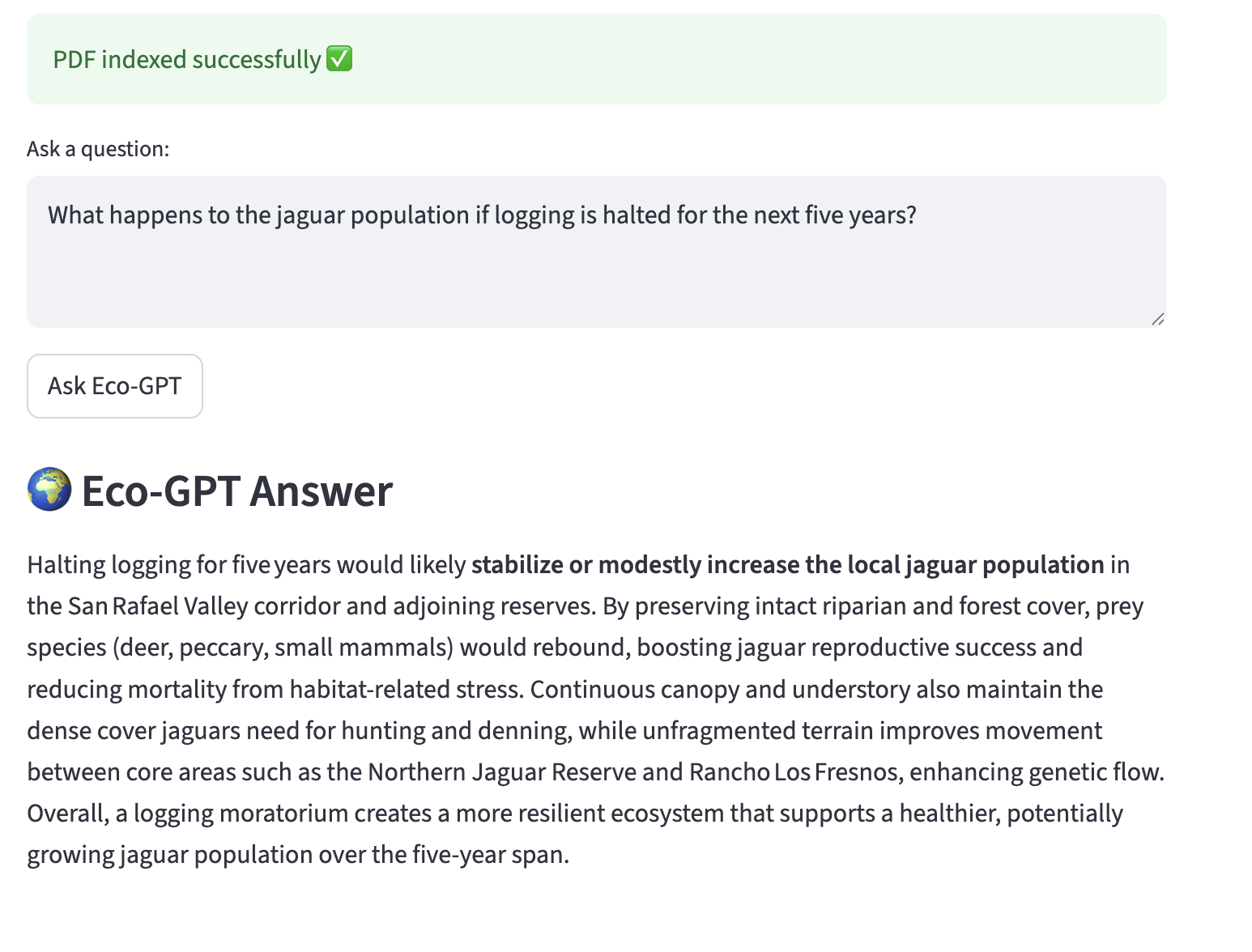
It provides a custom GPT for conducting research operations, drawing connections between observations and scientific papers. when observations is reported then it is logged. Researchers can upload the sensor log CSV + scientific papers PDF and ask natural language questions about it. For example 'what animal was near stream#2' . or 'what are conditions for jaguar sightings'.
How we built it
we broke it down into micro-steps with precise syntax. Made a Build of the Docker images (runs Dockerfile) A container image that contains the LLM, Streamlit UI, and all Python dependencies. Pulled a version of gpt-oss-120b and place it in ./models/ | . The model file that the LLM will load at runtime. Drop a CSV of observations sensor logs in 'examples`. The app then converted csv and scientific PDF to embeddings. We migrated this to Google Collab to get better performance and make a Public url accessible to testing. . The app was enabled as a notebook on google Collab serving Streamlit .
Challenges we ran into
1. Mixing structured + unstructured data:
CSV logs are structured (timestamps, sensors, payloads)
PDF research papers are unstructured (free-flowing text)
how to combine both into a single context the model can understand.
We flattened CSV rows into text, chunked PDFs, and merged them into a prompt
2. Handling PDFs efficiently
PDFs don’t always have clean text (some are scanned images, some have complex formatting).
how to extract text that the model actually reason over.
Used PyPDF2 for text extraction (works for text-based PDFs)
3.Caching embeddings
Embedding PDFs every run would be slow + expensive.
avoid recomputing embeddings every time the app refreshes.
4.Deploying in Colab
Streamlit normally runs on localhost, but Colab doesn’t expose ports.
Challenge: make it accessible with a public link.
Integrated pyngrok to tunnel the Streamlit app securely
5. Prompt design for retrieval-augmented generation
Provide Logs section (CSV context).
Provide Scientific Notes section (retrieved PDF)
Ask model to be accurate, concise, eco-friendly
6. User Experience
Challenge: keep visual UI simple but flexible.
CSV upload preview.
PDF indexing with spinner
Output area
Accomplishments that we're proud of
the thrill of how it solved a real-world ecological problem bringing with it a sense of accomplishment
What we learned
Outcomes depend from new found understanding of prompt building
What's next for Eco Gpt
include real time sensors
Log in or sign up for Devpost to join the conversation.