
Inspiration
We wanted to lower the bar for anyone to run a live stream with an AI-driven virtual host—no green screen, no mocap suit, just a webcam and a browser. The idea was to combine real-time 3D avatar motion capture with an AI that can script and speak in multiple languages, so one product could power both “VTuber-style” streaming and AI-hosted shows.
What it does
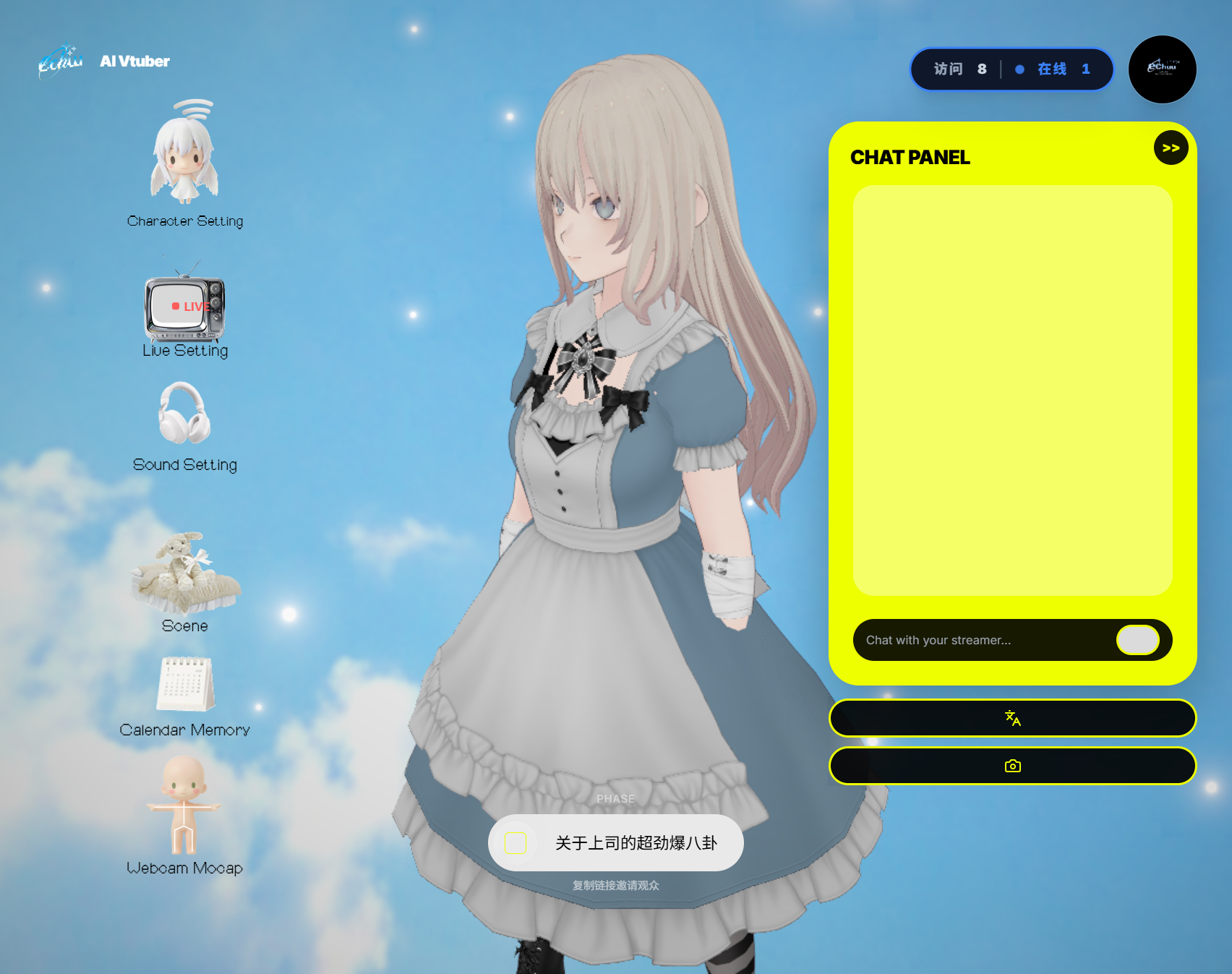
Echuu is an AI virtual streamer that runs in the browser. You pick a topic and persona, hit “Go Live,” and the app generates a script, drives a 3D VRM avatar with your webcam (face, pose, hands via MediaPipe), and speaks the lines with multilingual TTS (Qwen/CosyVoice). Viewers see a single-page live experience: avatar + captions + audio, with optional English/Chinese/Japanese. The frontend is a Next.js app (echuu.xyz); the live engine and TTS run on a FastAPI backend (e.g. on Railway).
How we built it
- Frontend: Next.js 14 (App Router), React Three Fiber + Three.js for the 3D avatar, MediaPipe Holistic for webcam pose/face/hands, Kalidokit to turn landmarks into VRM bone rotations. State is managed with Zustand; we avoid putting high-frequency mocap data in React state to keep 60fps.
- Backend: FastAPI service that runs the “Echuu” live engine: script generation (LLM), TTS (DashScope Qwen/CosyVoice), and WebSocket streaming of script steps and base64 audio. We support multiple LLM backends (e.g. Gemini, Claude) and configurable voice/language.
- Deploy: Next.js on Vercel; backend Dockerized and deployed on Railway, with env-based API keys and CORS/COOP/COEP for MediaPipe.
Challenges we ran into
- VRM orientation and axis mapping: VRM 0.x vs 1.0 face different directions; we had to normalize with
VRMUtils.rotateVRM0and tune axis settings so mocap rotations map correctly to the model. - TTS in production: The backend originally looked for the TTS module under
workflow/backend; in Docker the app runs from/app/backend, so we added a fallback to loadtts_client.pyfrom the current working directory so the same code works locally and on Railway. - Language and audio sync: Getting “English in → English out” and reliable audio delivery to the client required passing a
languagehint from the frontend and hardening the WebSocket/audio enqueue logic so the player doesn’t skip or duplicate chunks.
Accomplishments that we're proud of
- One stack for both real-time VTuber-style mocap and AI-hosted live streams.
- Multilingual pipeline (topic/persona + optional language) so the stream can stay in English, Chinese, or Japanese end-to-end.
- Shipping a working live experience (echuu.xyz) with 3D avatar, TTS, and script generation, deployable via GitHub → Railway with minimal config.
What we learned
- How to keep React and Three.js in sync without re-renders on every frame (refs, object pooling, memo).
- Integrating DashScope’s realtime TTS and designing a simple protocol for script + audio over WebSockets.
- The importance of matching deploy layout (e.g. Root Directory and Dockerfile path) to how the code resolves modules so TTS and engines load correctly in production.
What's next for Echuu-AI Virtual Streamer
- Richer persona and memory so the AI can refer to past streams and viewer context.
- Optional recording/playback and clipping of live segments.
- More avatar and scene options, and tuning finger/hand mapping for VRM so gestures look more natural.



Log in or sign up for Devpost to join the conversation.