-
-
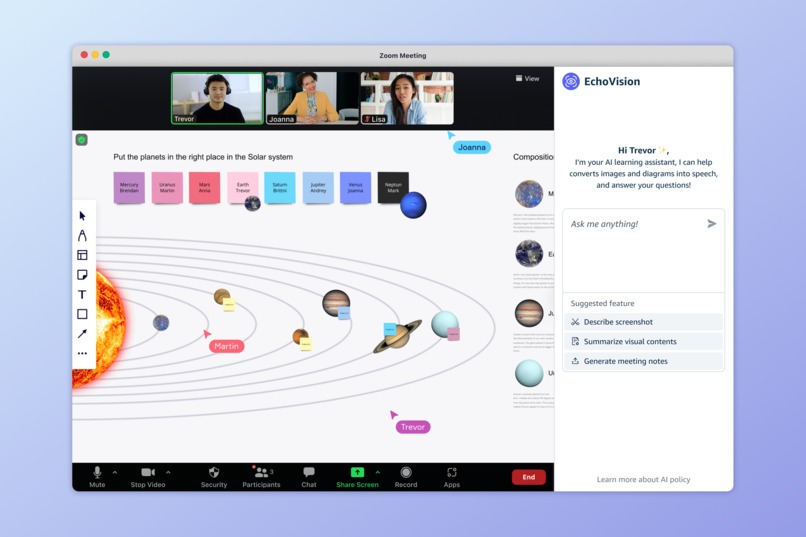
Overview
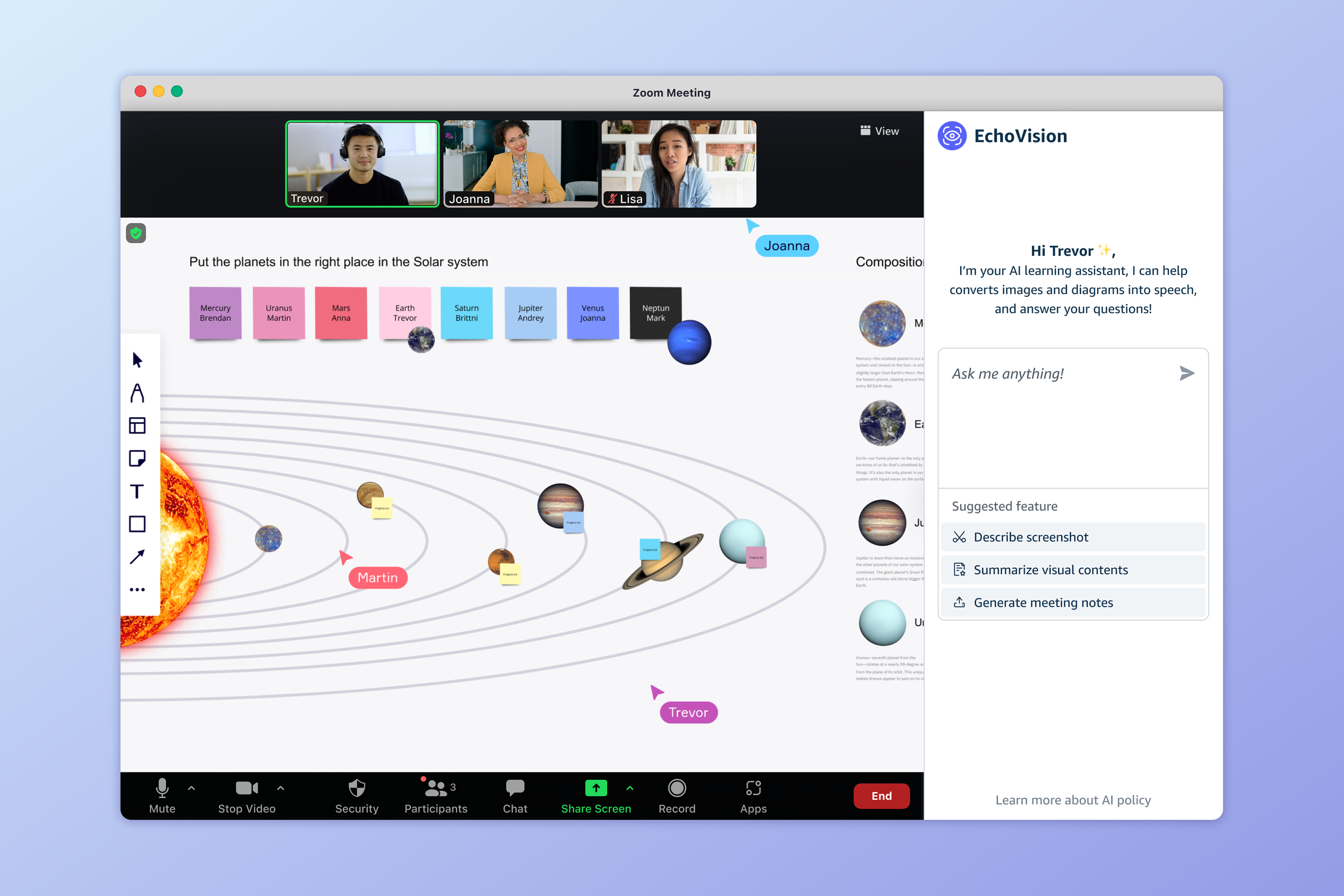
Inspiration
We were inspired by the need to close the accessibility gap in online education. As online learning continues to scale globally, we noticed that students with visual impairments or reading disabilities are still left behind—especially when it comes to visual materials like charts, diagrams, and infographics. We wanted to build a tool that turns these silent visuals into inclusive learning opportunities.
What it does
EchoVision is an AI-powered browser plugin that converts images shown during online classes into descriptive audio, in real time. It detects visual content (including uploaded slides, shared screens, or in-browser images), extracts meaningful context, and provides accurate, dynamic audio narration. It’s designed to work seamlessly with screen readers and helps all learners better access visual information.
How we built it
When an image is detected, it’s sent to an AWS Lambda function, which calls Amazon Bedrock to generate a text description. The result is stored in S3, then passed to Amazon Polly to produce audio, which is played back to the user in real time.
Challenges we ran into
1.Ensuring real-time processing with minimal lag during live lectures 2.Handling low-resolution or visually dense slides (e.g., handwritten notes or screenshots) 3.Aligning audio output with existing screen reader workflows without causing overlaps or confusion 4.Balancing technical accuracy of descriptions with human-like narration for better comprehension
Accomplishments that we're proud of
1.Built a working prototype within a short timeframe that accurately converts complex visuals into spoken content 2.Created a plug-and-play experience that works across multiple learning platforms
What we learned
1.Collaborating across design, frontend, and ML pipelines taught us how to move fast while staying aligned on impact 2.Accessibility is not just a feature—it’s a mindset. Building for inclusivity from day one leads to better outcomes for everyone
What's next for EchoVision
1.Expand language support to make the plugin multilingual 2.Improve visual context detection for more abstract images (e.g., graphs or art) 3.Pilot the plugin in partnership with schools and edtech platforms to test at scale 4.Open-source parts of the project to invite broader accessibility innovation
Built With
- amazon-web-services
- amazonpolly
- bedrock
- lambda
- s3


Log in or sign up for Devpost to join the conversation.