-
-

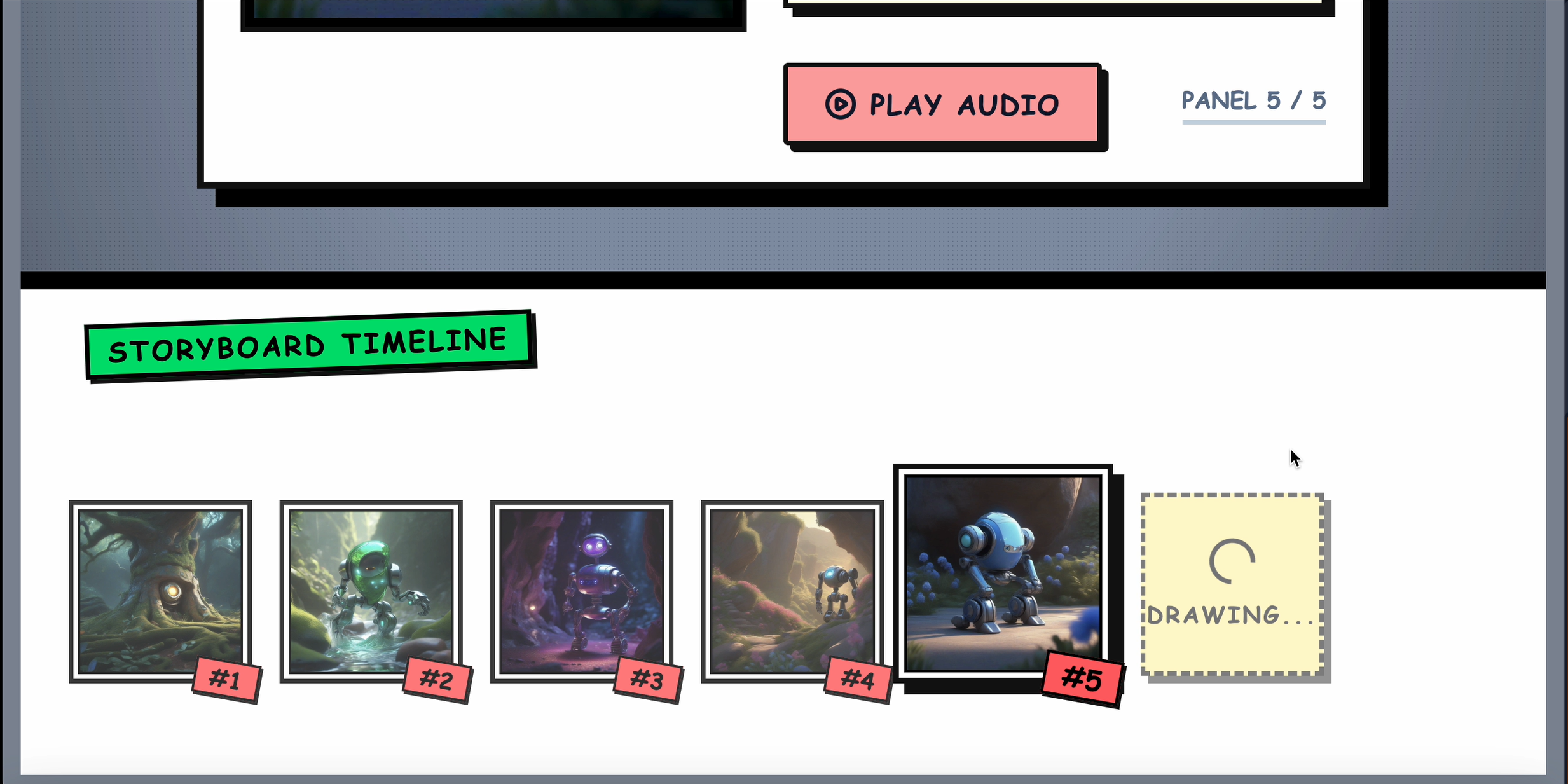
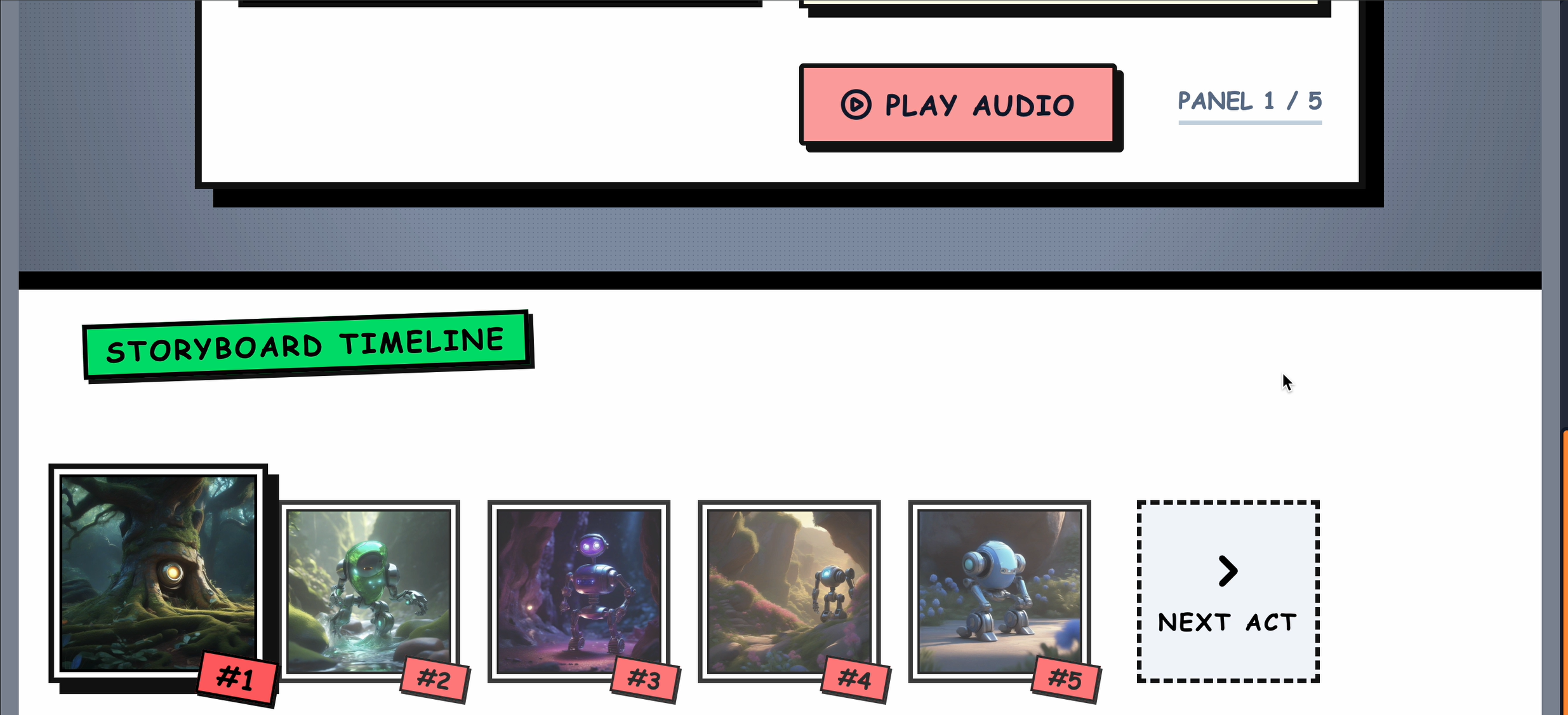
All 5 panels complete!
-
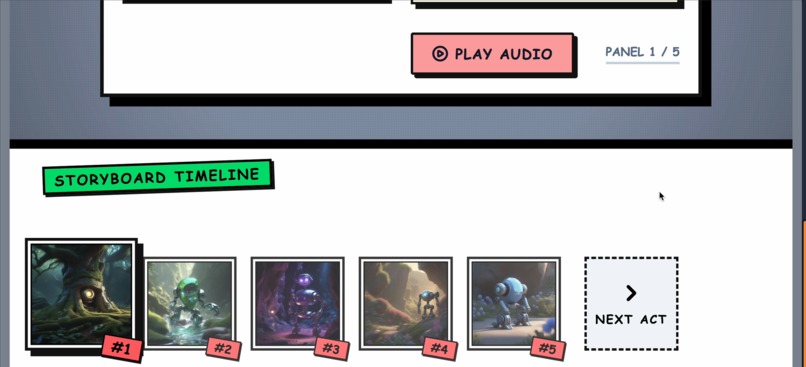
Panel narration comes alive
-

AI drawing panels in real-time
-

Where your story begins


Inspiration EchoSketch AI was inspired by the idea that anyone should be able to turn a rough idea into a cinematic visual story without needing artistic or technical skills. We wanted to combine modern generative AI with a playful, interactive interface so that kids, writers, educators, and creators could all storyboard like a film studio in just a few clicks.
What it does EchoSketch AI takes a short text prompt and expands it into a structured 5-panel story arc with beginning, buildup, climax, and resolution. For each panel, it generates a stylized illustration, adds expressive text-to-speech narration, and presents everything in a smooth, horizontal comic-strip interface that users can continue with a “What happens next?” engine.
How we built it EchoSketch uses a React + Vite frontend with Tailwind CSS and Framer Motion to create a responsive, animated storyboard experience. On the backend, we built a FastAPI service in Python where Google Gemini (via Google AI Studio APIs running on Google Cloud infrastructure) handles story generation. SDXL through Hugging Face generates stylized illustrations in different art styles, and Edge TTS produces panel-wise narration. These services are orchestrated through a multimodal AI pipeline that synchronizes story text, images, and audio into a cohesive storyboard experience.
Challenges we ran into Coordinating multiple AI services reliably was a big challenge, especially keeping story text, images, and audio perfectly in sync across all five panels. We also faced issues with async behavior and SDK conflicts during image generation, which led us to isolate image generation in subprocess workers to keep the system stable under repeated usage.
Accomplishments that we're proud of We’re proud that a user can type or voice input a single sentence and instantly see a complete, cinematic storyboard with cohesive visuals and voice narration. We’re also happy with how polished the horizontal comic-strip UI feels, and how easy it is for non-technical users to keep extending their story with the continuation feature.
What we learned We learned how to design a robust multimodal AI pipeline that chains together Google Gemini large language models, image generation models, and text-to-speech systems without breaking the user experience.
What's next for EchoSketch AI Next, we want to add multi-character dialogue, branching “choose your own adventure” storylines, and eventually video generation from the storyboard panels. We’re also planning to deploy EchoSketch to Google Cloud infrastructure for scalable public access, enabling users to generate stories instantly from anywhere.


Log in or sign up for Devpost to join the conversation.