
Inspiration
The internet was built primarily for the sighted and able-bodied. For the 2.2 billion people worldwide living with vision impairments or motor disabilities, the web still presents significant barriers.
Traditional screen readers are passive — they read content aloud but do not help users act on it.
We wanted to shift the paradigm from “Screen Reading” to “Agentic Browsing.”
What if the browser could see what you see and hear what you say — and then click, scroll, and navigate for you?
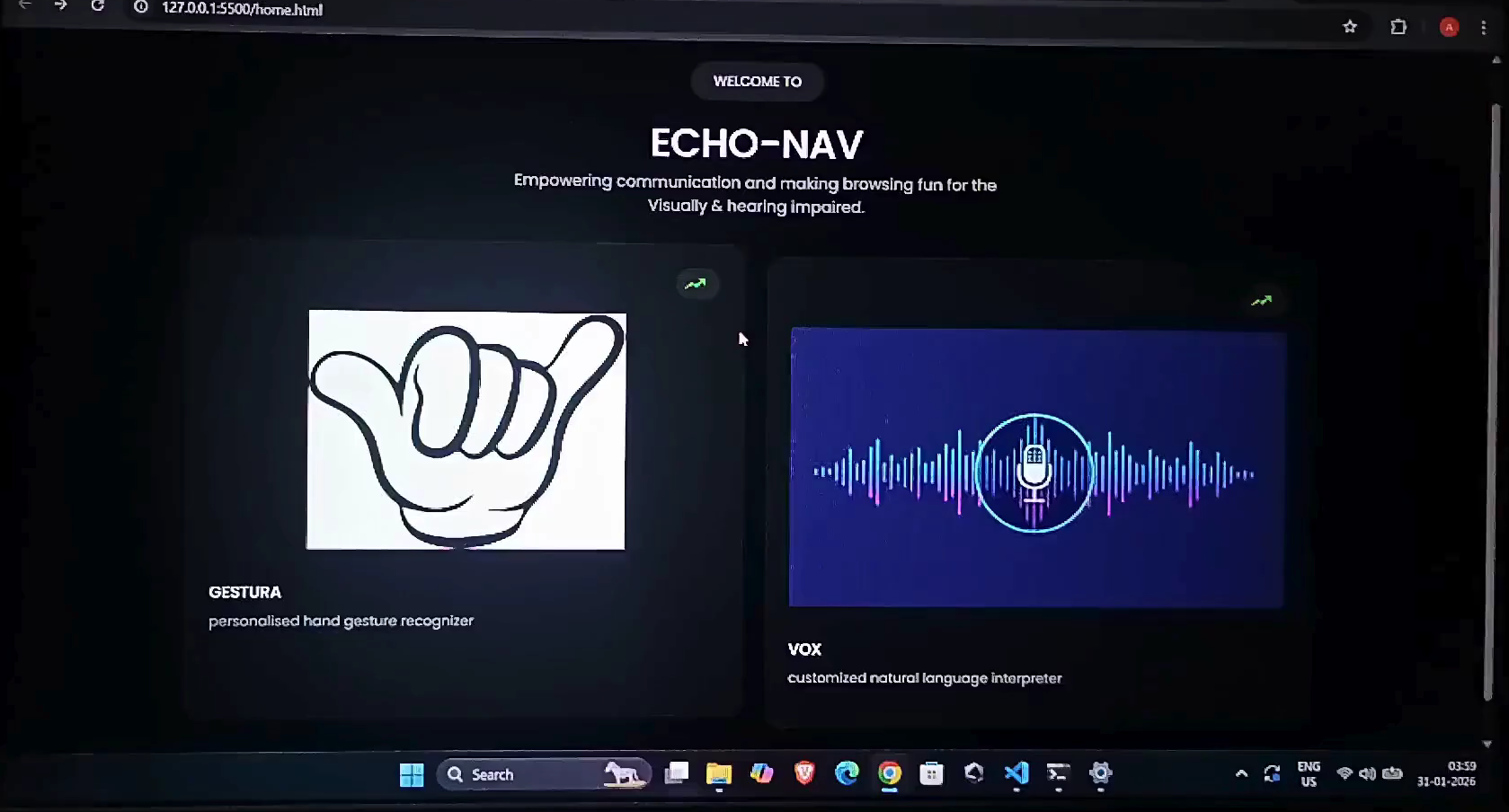
This question led to the creation of ECHO-NAV, a system designed to restore true digital agency by enabling users to navigate the web using only voice commands or hand gestures.
What It Does
ECHO-NAV is an intelligent, agent-driven accessibility system with two multimodal interfaces:
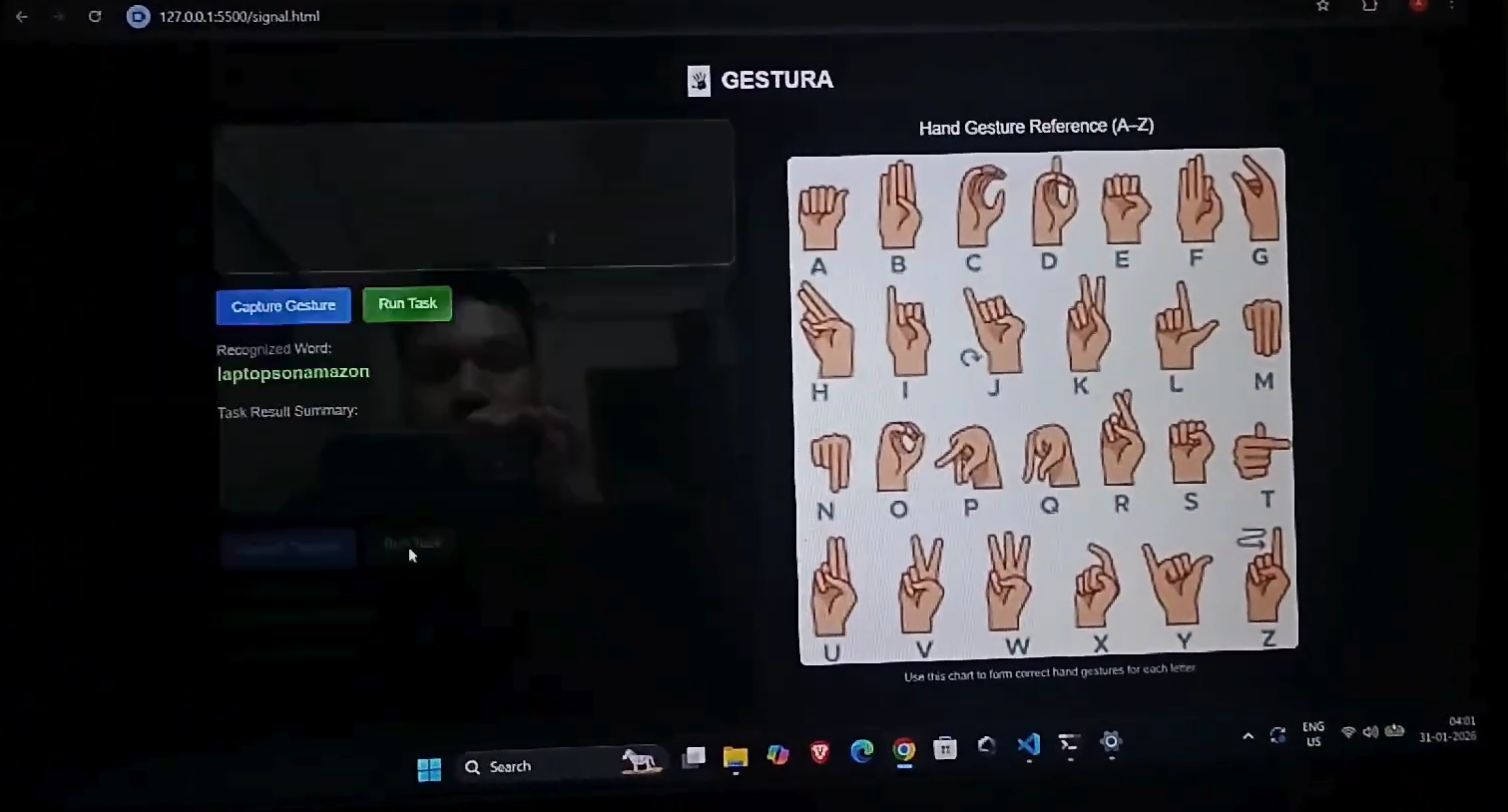
Gestura — Hand Signal Agent
- Uses a camera to track hand gestures in real time
- MediaPipe extracts hand landmarks
- A pretrained ML model predicts alphabets from gestures
- Recognized gestures trigger automated browsing tasks
- Example:
'S'gesture → Perform a search
- Example:
Vox — Voice Agent
- Accepts natural language voice commands
- Autonomously performs browser actions
- Generates and speaks a summary of the completed task
How We Built It
Frontend
- HTML
- CSS
- JavaScript
Backend
- Python
- FastAPI
AI & Machine Learning
- MediaPipe for hand landmark detection
- Pretrained ML model for gesture-to-alphabet prediction
- Real-time inference pipeline
Agentic Core
browser_uselibrary for controlling a headless browser
- Clicking
- Typing
- Scrolling
- Executing workflows
- Clicking
Development Tools
- Jupyter Notebook for model prototyping
Challenges We Faced
Model Latency
Reducing lag between gesture recognition and browser execution.
Gesture Confusion
Fine-tuning the ML model to distinguish similar hand signs (e.g., 'A' vs 'E').
Web Clutter
Preventing the browsing agent from getting stuck on pop-ups and cookie banners.
Accomplishments
Real-Time Action Mapping
Mapped hand sign alphabets to complex web actions instantly.
True Digital Agency
Enabled users to complete tasks — not just consume content — without a keyboard or mouse.
Multimodal Integration
Integrated voice and vision inputs into one cohesive system.
What We Learned
Agents > Chatbots
LLMs combined with browser-control tools can actively navigate digital environments.
ML Pipeline Optimization
Managing the pipeline from:
Built With
- browser-use
- css
- hrml
- javascript
- jupyter
- mediapipe
- python
- sockets

Log in or sign up for Devpost to join the conversation.