-
-

EchoMoods Home Page
-
EchoMoods Recording Page
-
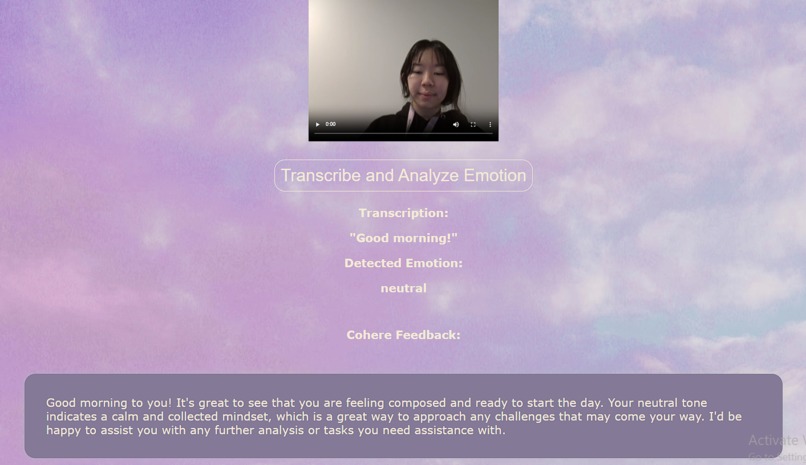
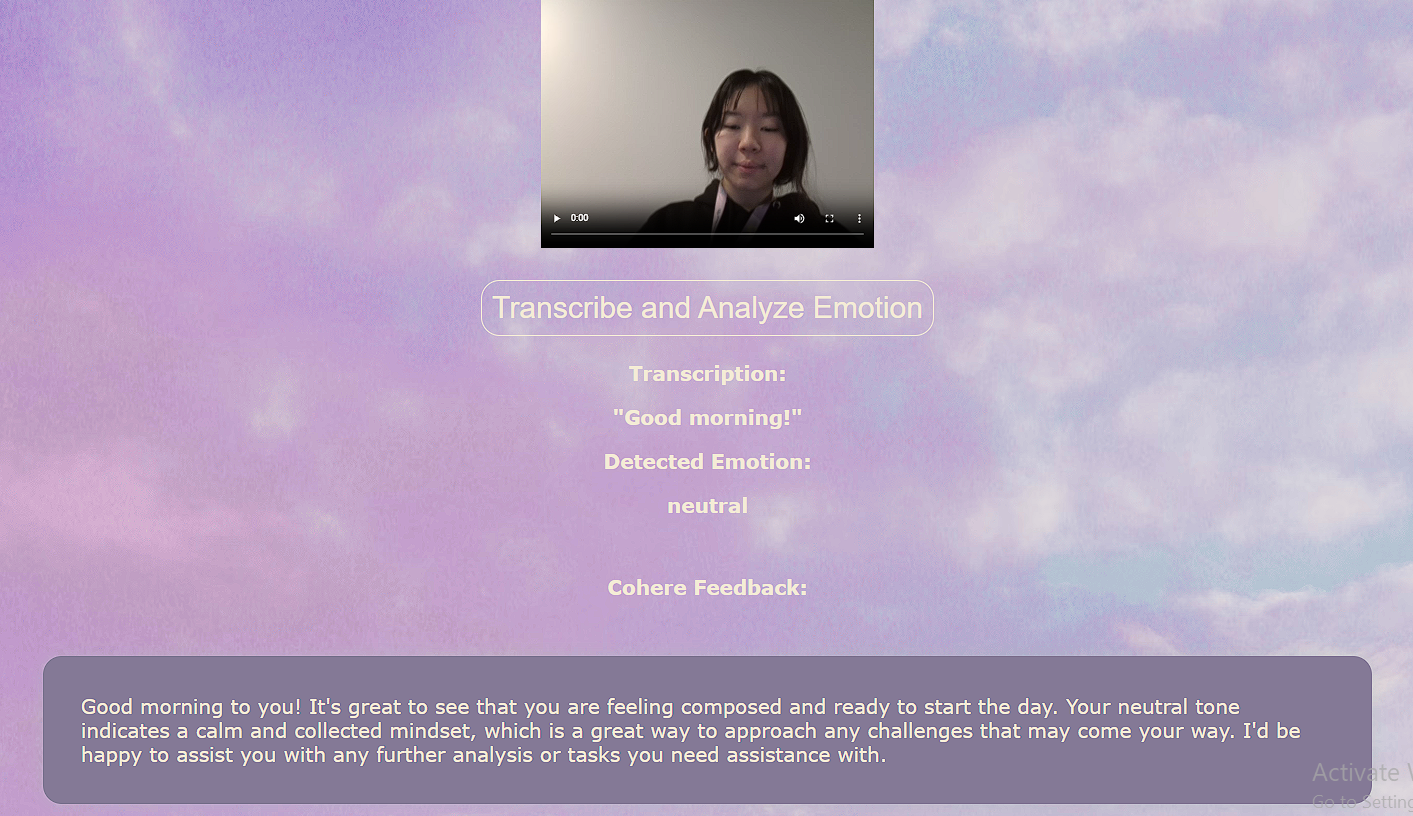
EchoMoods Input Analysis Page


Inspiration
Millions of people with communication deficits face daily challenges in expressing themselves clearly. Many turn to professional help, such as speech therapists, to navigate these difficulties. However, there’s an undeniable power in being able to improve on your own terms, practicing and refining communication in a safe, personalized environment. EchoMoods was inspired by the desire to offer people the autonomy to master their communication skills independently, with instant, constructive feedback. We wanted to build a tool that could truly make a difference in enhancing the quality of life for those with communication challenges.
What it does
EchoMoods enables users to record a video of themselves mouthing a sentence along with a facial expression. The app then analyzes the video to provide feedback on three core aspects:
- Speech Recognition: What words it interprets from your lip movements.
- Emotion Detection: The emotion your facial expressions convey.
- Overall Sentiment: A general impression of how your communication is perceived.
By offering this multi-dimensional feedback, EchoMoods helps users understand where their communication might be misunderstood and offers insight into improving both verbal and non-verbal cues.
How we built it
We developed EchoMoods using a combination of cutting-edge technologies:
- Frontend: Built with React.js for a smooth, user-friendly interface.
- Lip Reading: Integrated through the Symphonic Labs API for accurate speech detection based on lip movements.
- Facial Emotion Recognition: Utilized Face-API to interpret the emotional content of facial expressions.
- Sentiment Analysis: Cohere AI provided the sentiment analysis functionality, running on an Express.js backend server.
This integration of multiple APIs allowed us to provide real-time, actionable feedback to users, making EchoMoods both powerful and versatile.
Challenges we ran into
One of the major challenges we faced was integrating the backend with Cohere AI. Initially, we underestimated the complexity of setting up a backend server to manage the API calls efficiently. Debugging the process of connecting all the APIs smoothly also took significant time and effort, but we persevered and overcame these roadblocks through collaboration and problem-solving.
Accomplishments that we're proud of
We’re incredibly proud of successfully combining multiple APIs into a cohesive, functional application. The ability to create a unique solution that brings real value to people’s lives, while utilizing innovative technology, is something we cherish. The user-friendly interface and seamless feedback process are significant achievements that we believe set EchoMoods apart from other tools.
What we learned
Throughout the development of EchoMoods, we gained a deeper understanding of the nuances involved in API integration. We learned that every API has its own set of requirements and constraints, which must be carefully navigated. We also gained valuable insights into optimizing backend services to handle multiple API calls efficiently, ensuring a smooth user experience.
What's next for EchoMoods
The future of EchoMoods lies in improving the accuracy and depth of its feedback. We aim to:
- Enhance our training data to provide more precise lip-reading and emotional recognition.
- Expand the AI’s sentiment analysis capabilities to offer personalized tips and advice on specific areas of improvement.
- Incorporate more languages and dialects to make the app accessible to a broader audience.
- Explore real-time feedback options, allowing users to adjust their communication on the fly.
By continuing to refine EchoMoods, we hope to further empower individuals with communication challenges and make the world a more inclusive place.
Built With
- api
- cohere
- css
- express.js
- face-api
- javascript
- node.js
- react.js
- symphonic-labs
- typescript











Log in or sign up for Devpost to join the conversation.