-
-

EchoLens Homepage
-
EchoLens Features
-
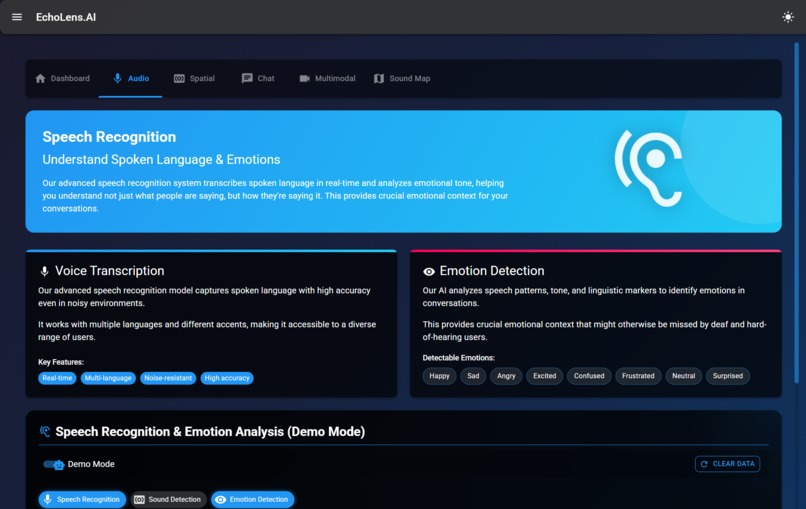
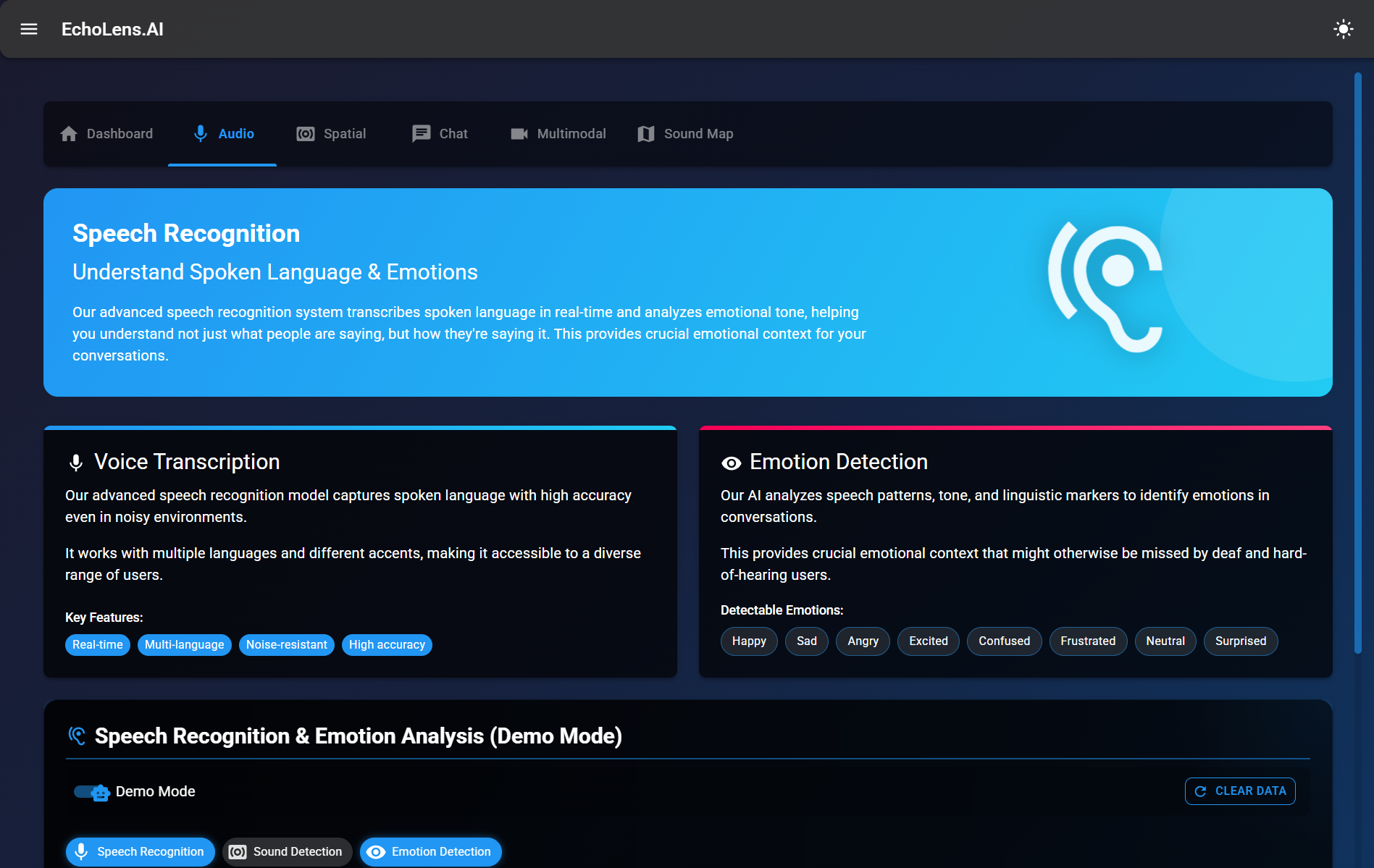
Speech Recognition
-
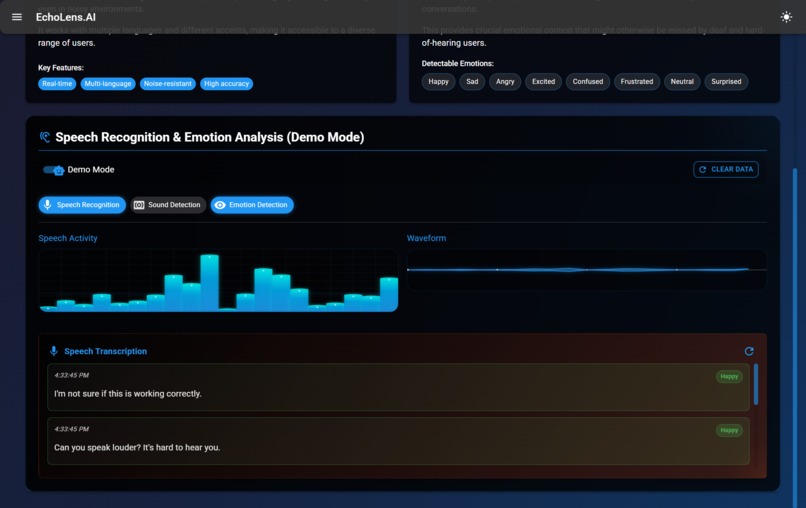
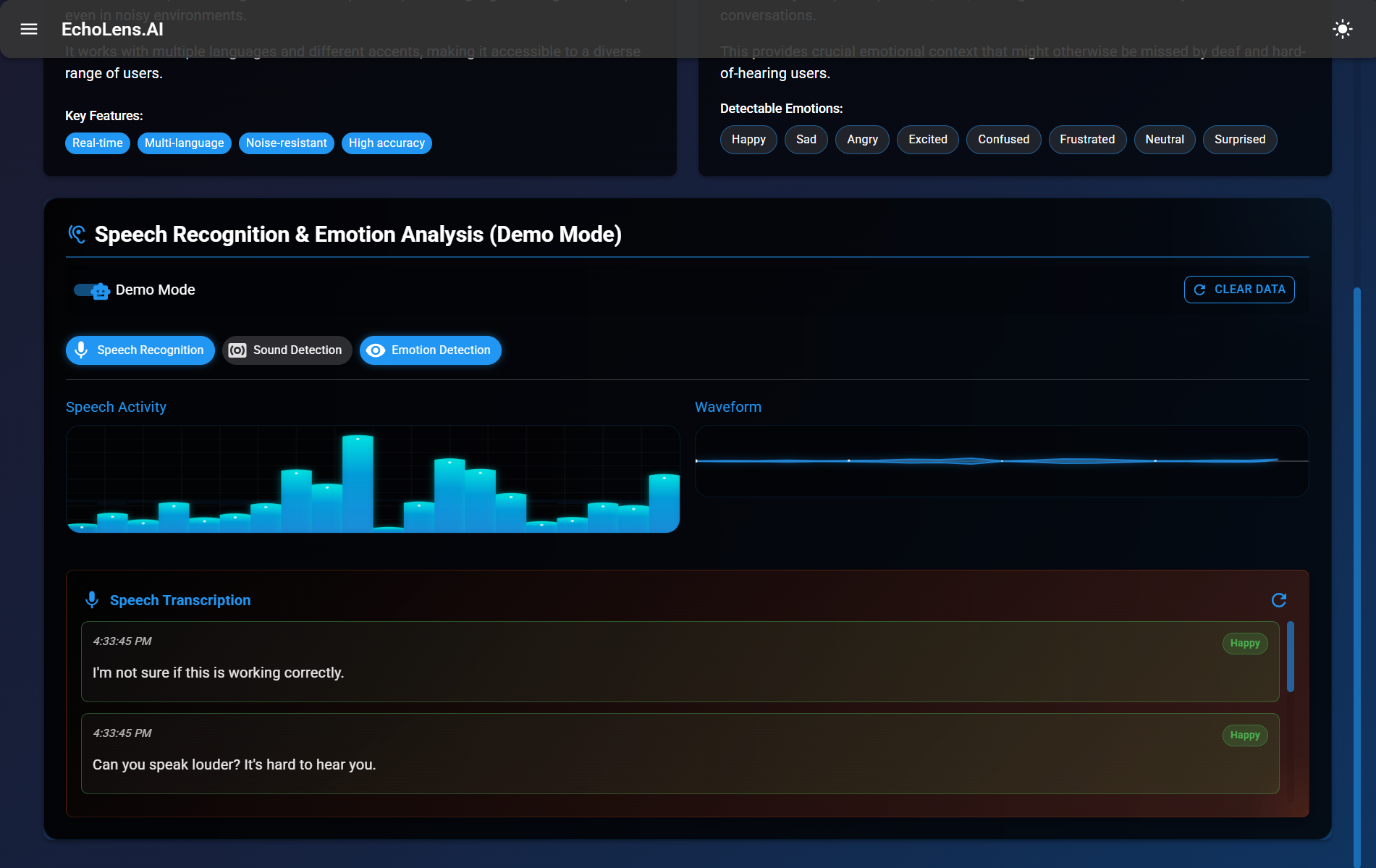
Speech Recognition and Emotion Analysis
-
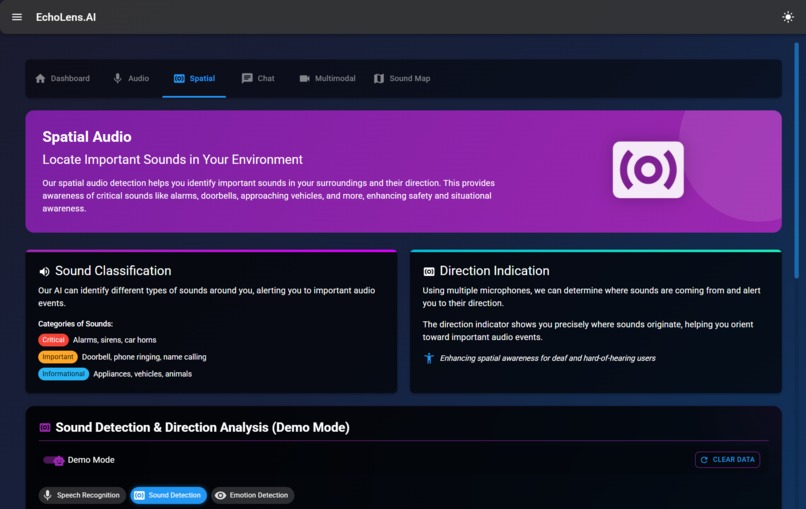
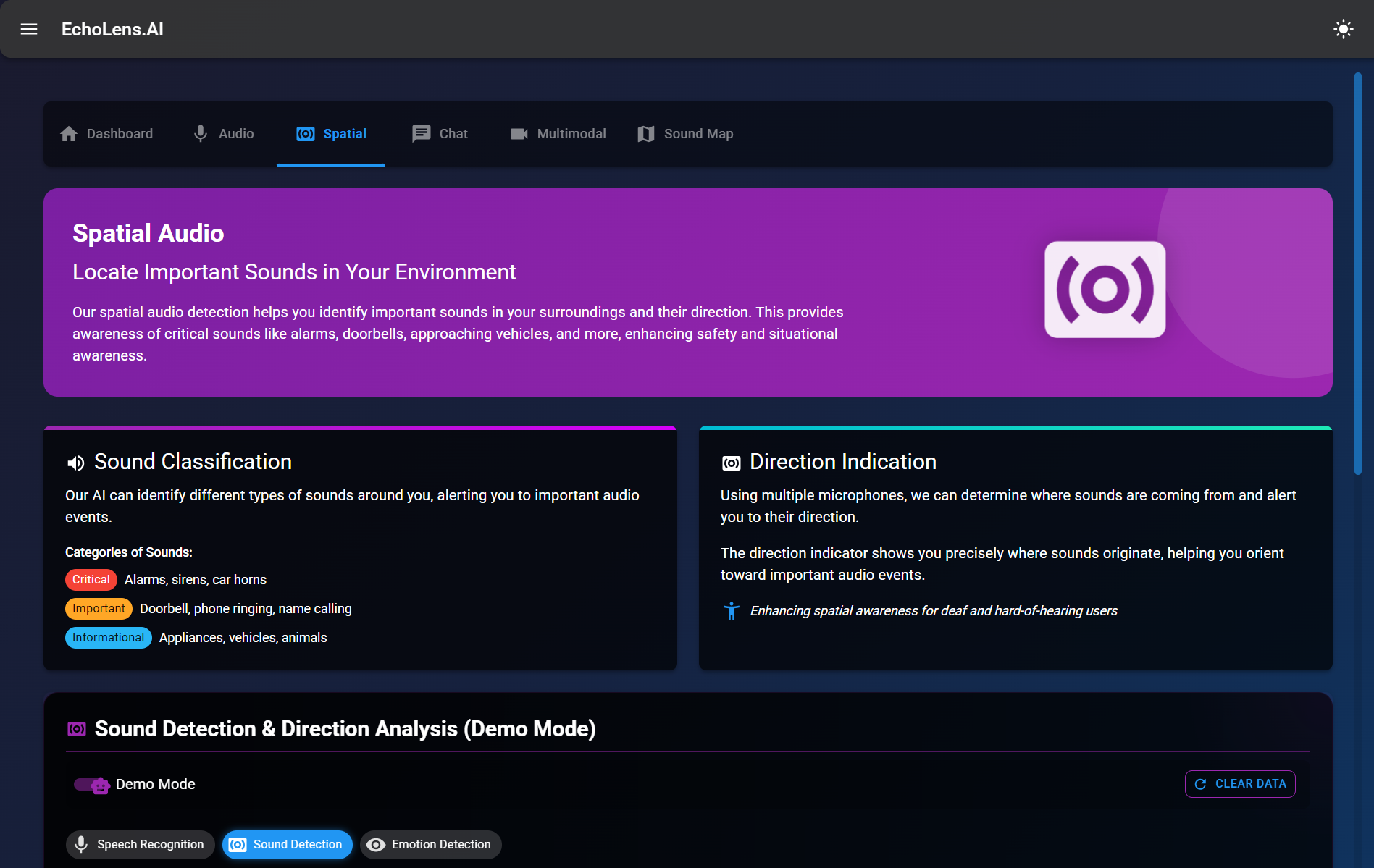
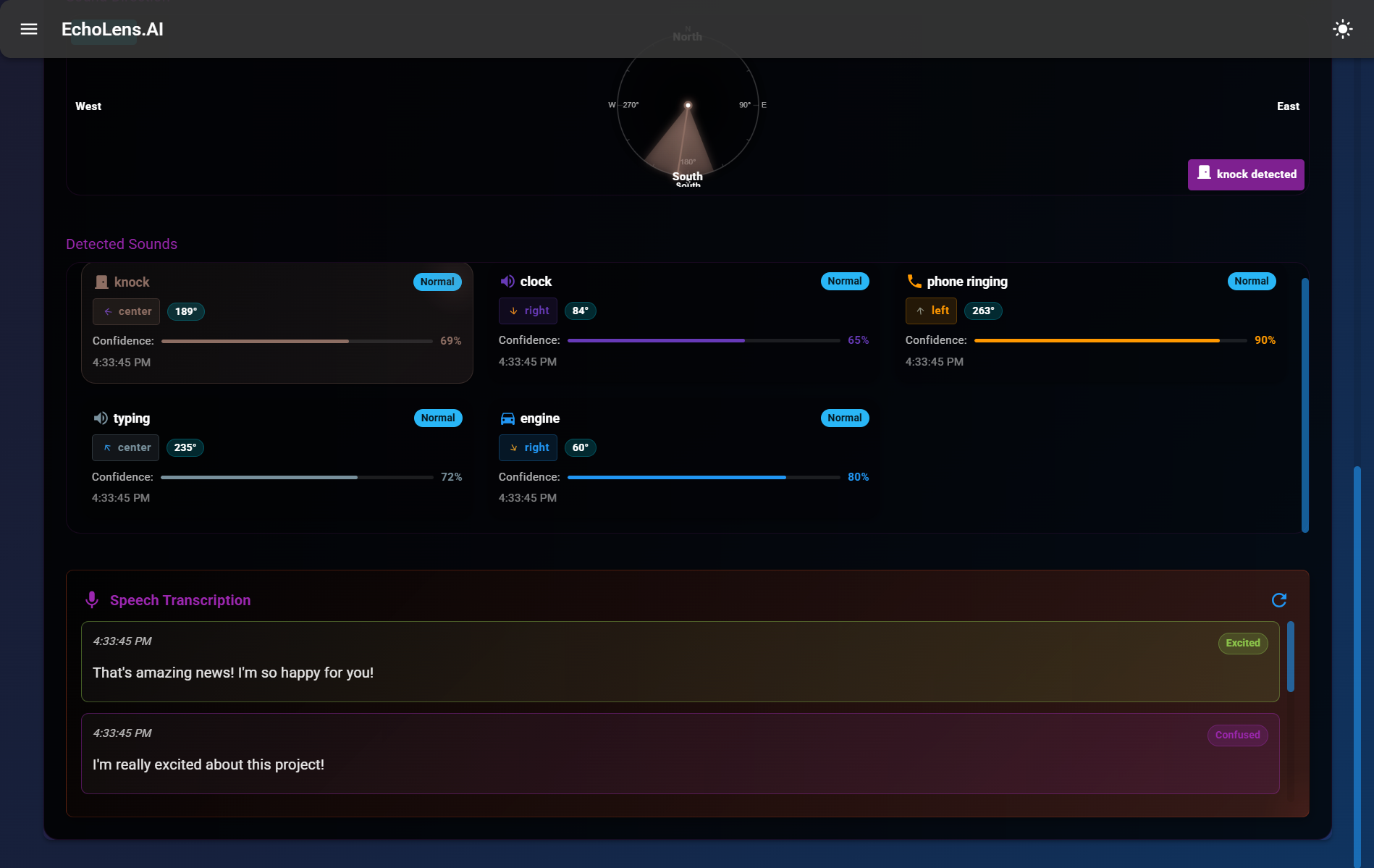
Spatial Audio
-
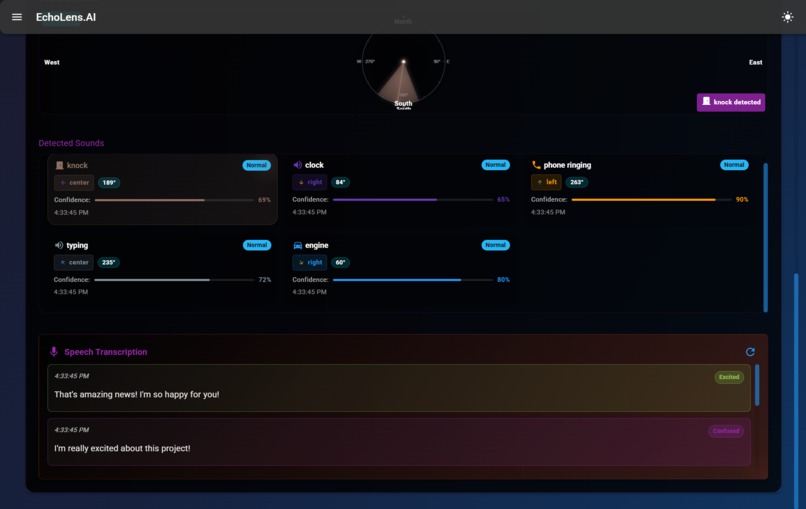
Spatial Audio Detection
-
-
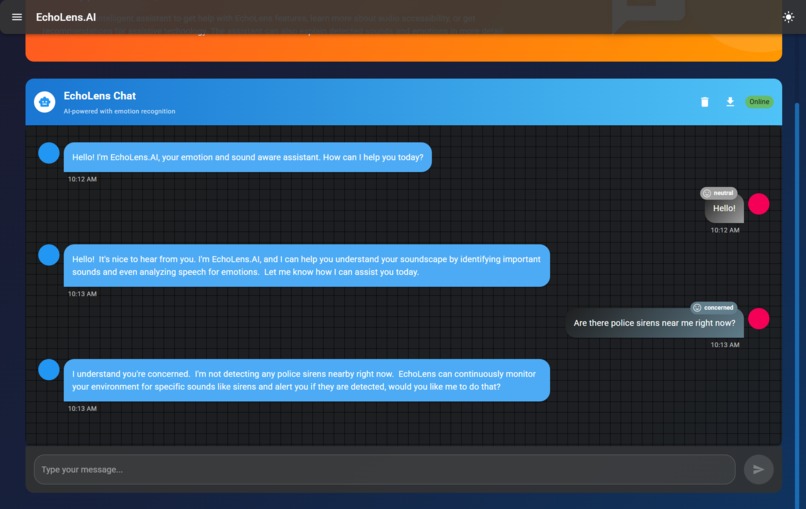
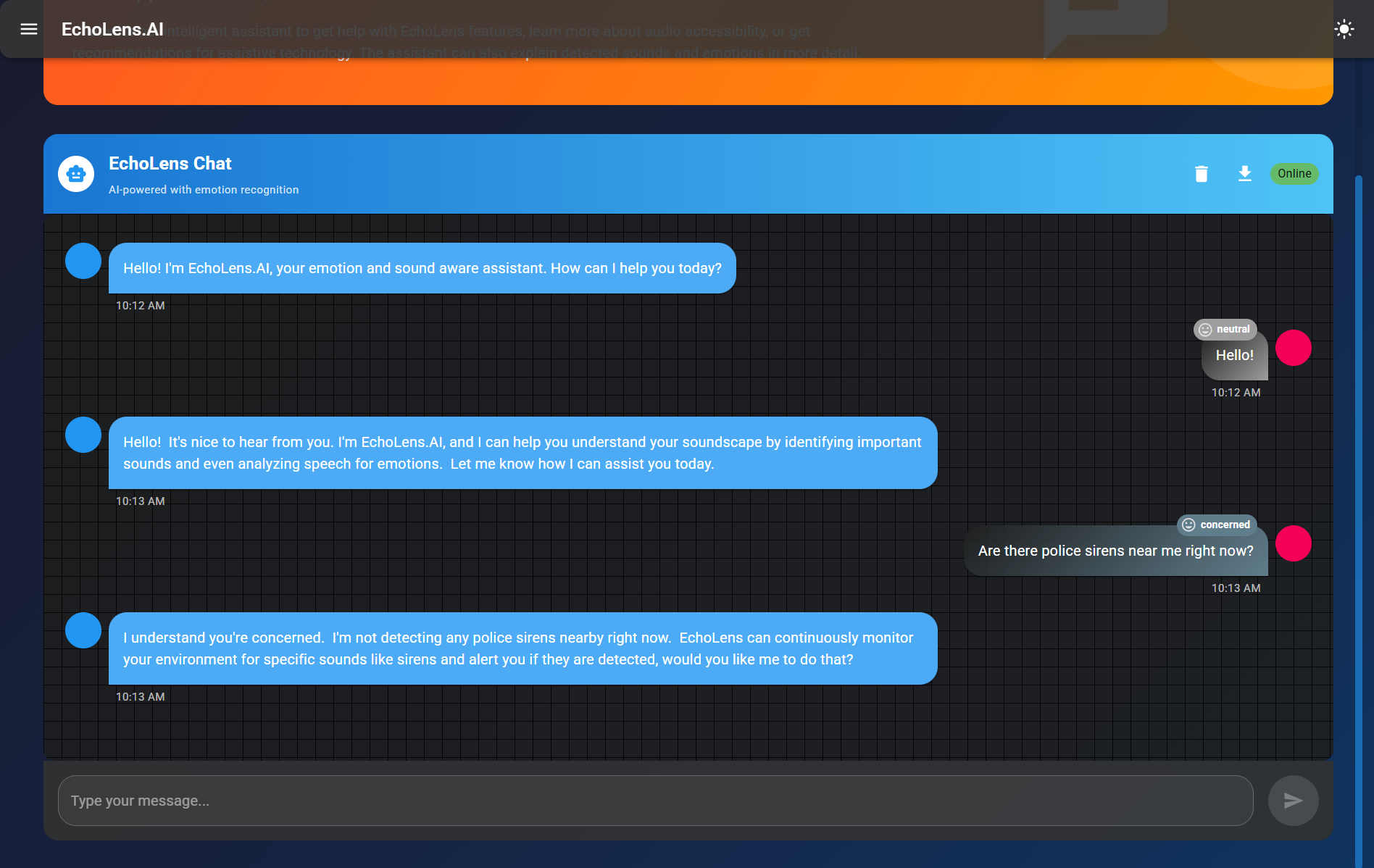
EchoLens Chat
-
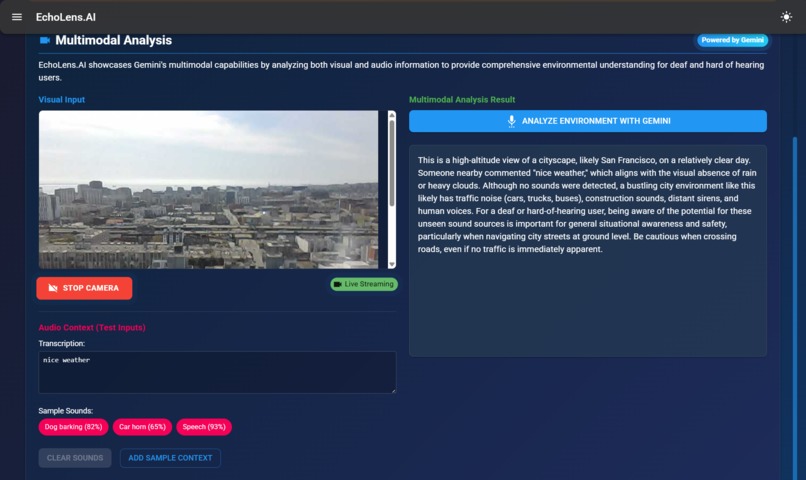
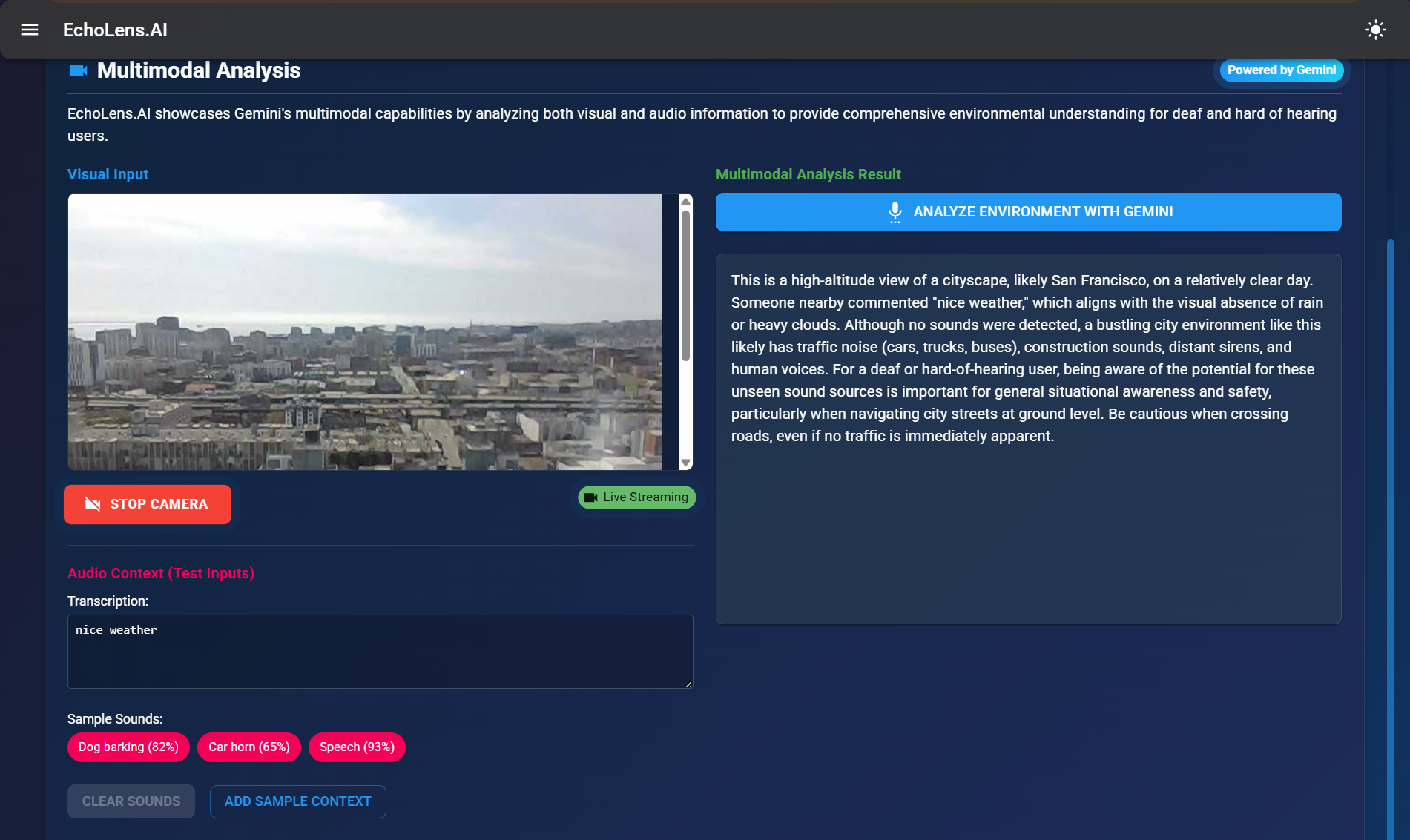
Multimodal Analysis
-
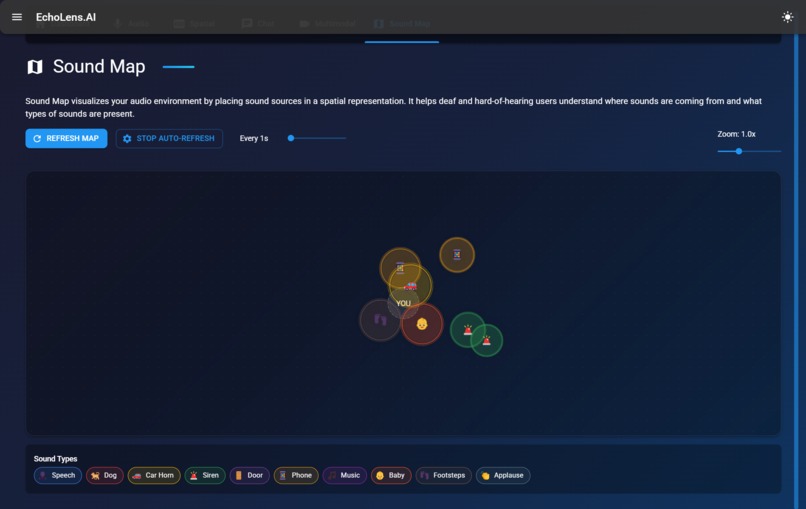
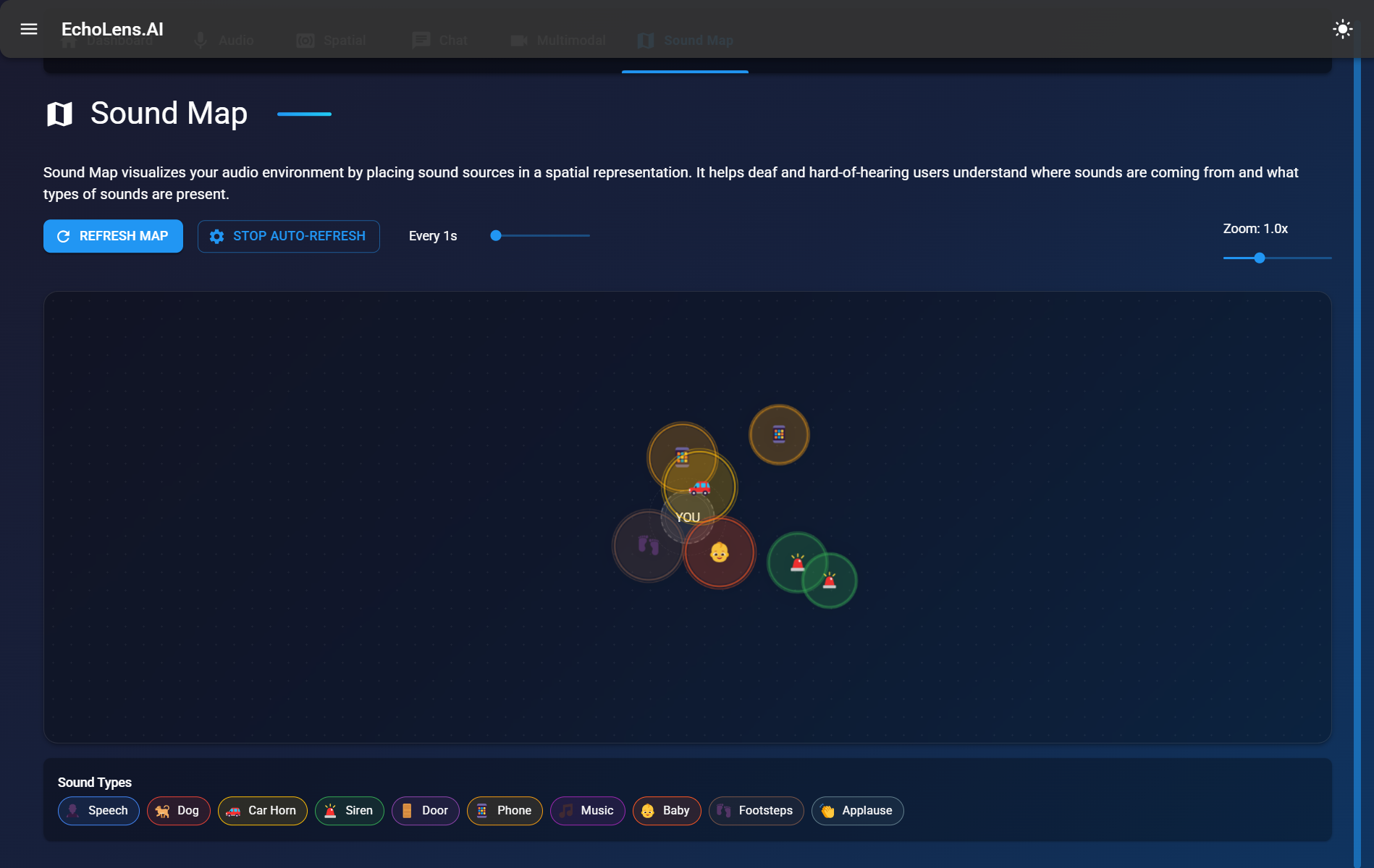
Sound Map
-

Light Mode


Inspiration
Deaf and hard-of-hearing (HoH) individuals often face barriers in accessing the full spectrum of audio cues around them—everything from casual conversations to critical alerts like alarms or someone calling their name. Our team was inspired by a vision of an accessible future where no one is left out of their environment due to hearing loss. We wanted to combine spatial awareness, emotional understanding, and practical utility to create something that truly empowers communication and awareness.
What It Does
EchoLens translates real-world audio—both spoken and environmental—into accessible visual information. It performs real-time speech-to-text transcription with emotional tone detection, classifies environmental sounds (like alarms, door knocks, or footsteps), and displays directional cues to inform users where the sound originated from. It enhances both spatial and social awareness for Deaf/HoH users.
What We Learned
This hackathon challenged us to explore the capabilities of accessible, multimodal computing:
AI Integration:
- Whisper API for real-time transcription
- Gemini AI for emotional tone enhancement
- YAMNet for environmental sound classification
- Deepface (optional) for visual emotion cues
- Multimodal fusion for contextual awareness
- MongoDB used for AI memory and user personalization capabilities
Real-Time Audio Processing:
- Spatial sound mapping with PyRoomAcoustics
- Audio capture and streaming with Sounddevice
- Canvas API for live waveform rendering
- Whisper and SpeechRecognition coordination
Frontend and UX Design:
- Material UI theming for accessibility
- Framer Motion for intuitive animations
- Dynamic transcription panel with emotional tagging
- Directional sound map for spatial feedback
Technical Collaboration:
- Flask API for communication with the frontend
- Real-time backend-to-frontend sync
- Integrating multiple APIs and services under pressure
- Designing for inclusivity in every interface decision
Most importantly, we learned how immersive, accessible design can empower communities and reshape how we think about sound.
How We Built It
Frontend Architecture
- React.js with Material UI for a responsive and accessible interface
- Framer Motion for smooth animations and transitions
- Canvas API for real-time waveforms and particle visualizations
- Custom themes for dark/light mode support
- React Router for dynamic page navigation
Backend Systems
- Flask framework for high-performance REST API endpoints
- TensorFlow, YAMNet, and Google Gemini API for multimodal audio and emotion analysis
- SpeechRecognition and Whisper API for real-time transcription
- Sounddevice and PyRoomAcoustics for audio capture and spatial modeling
- OpenCV and Pillow for visual processing
AI & Audio Intelligence
- YAMNet for sound event classification
- Gemini AI for emotional and contextual inference
- OpenCV and Deepface for visual emotion cues
- Multimodal fusion combining audio and visual cues for enhanced environmental understanding
Data & Storage
- PyMongo for MongoDB integration
- Python-dotenv for secure environment management
Visualization & Interaction
- Interactive sound map with directional indicators
- Dynamic transcription panel with emotion tagging
- Custom animations for different sound types and intensities
- Light mode feature
Challenges We Ran Into
Real-Time Processing:
Balancing performance with accuracy in live audio environments was a significant challenge.
Emotion Detection:
Sarcasm and emotional nuance are difficult to quantify and detect programmatically.
Spatial Sound Mapping:
Translating acoustic direction into intuitive visuals required experimentation with layout and interaction.
Frontend-Backend Communication:
Synchronizing live visualizations with backend predictions in real time was technically demanding.
Accomplishments We're Proud Of
- Created a live spatial sound visualizer with directional indicators
- Built a responsive interface that transcribes speech and detects emotions simultaneously
- Enabled detection and contextual labeling of common household/environmental sounds
Successfully integrated a multimodal AI model (Gemini) into a user-facing tool.
Learnt and integrated several new technologies.
What's Next for EchoLens
Feature Enhancements
- Custom sound training so users can label personal sounds (e.g., a pet’s bark)
- Add haptic feedback for physical alerts
- Improve speaker identification and dialogue grouping
Platform Expansion
- Mobile deployment for on-the-go accessibility
- Extend support to wearable tech like AR glasses
Our goal is to make audio accessibility smarter, more intuitive, and available anytime, anywhere.






Log in or sign up for Devpost to join the conversation.