-

EchoLens Brand Poster
-

“Privacy-First AI” Concept Image
-

“Empathy in Technology” Human-Centered Image
-
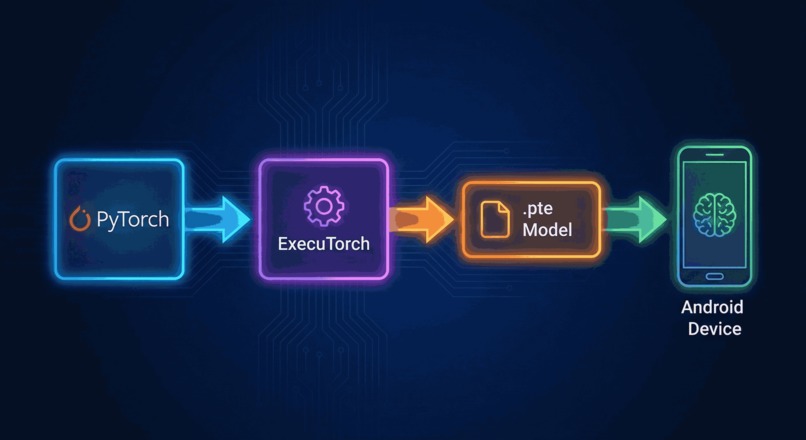
“ExecuTorch Pipeline” Illustration
-

“EchoLens App Mockup” Minimalist Showcase
-

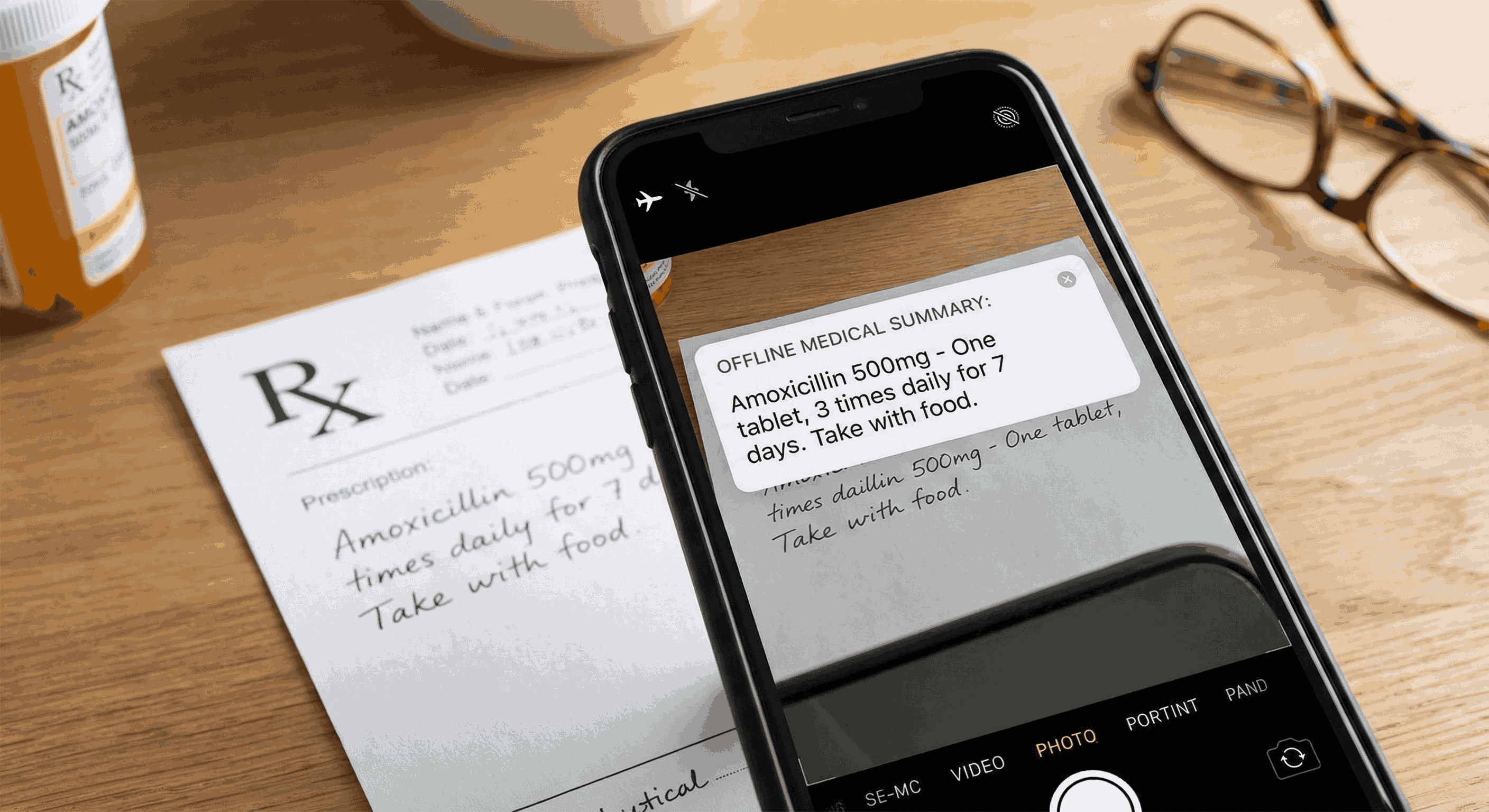
“Reading Medical Documents Offline” Scenario
-

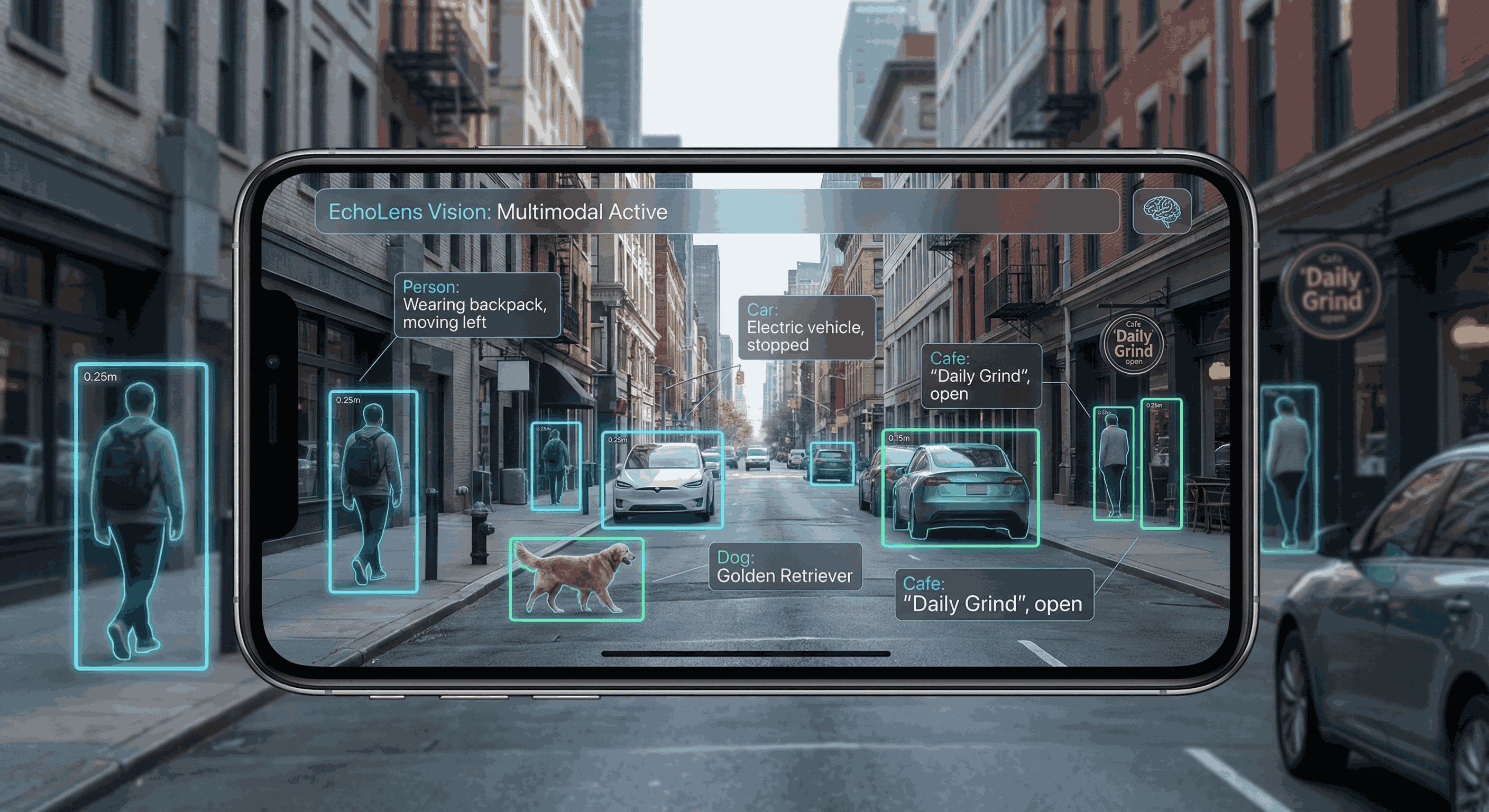
“Future Vision: Multimodal” Concept Art
-

“Llama 3.2 On the Edge” Tech Diagram Art
-

“On-Device Summarizer” UI Visualization





Inspiration
Visually impaired individuals often face a difficult choice: trade their privacy for accessibility, or struggle with daily tasks. Most existing "AI for the Blind" tools rely on cloud APIs, meaning sensitive letters, medical bills, or legal notices are sent to remote servers to be processed. We asked ourselves: Why should accessibility cost privacy?
We wanted to build a solution that empowers users to understand their surroundings and documents instantly, without a single byte of data leaving their hands. Inspired by the release of Llama 3.2 1B and Arm’s KleidiAI, we realized we finally had the tools to build a truly private, offline "narrator" that lives entirely on the edge.
What it does
EchoLens is an offline, privacy-first Android application that acts as a digital companion for the visually impaired.
- Instant Summarization: The user can paste text (or use OCR) from complex documents like medical prescriptions or bank statements.
- On-Device Intelligence: The app uses a local AI model to simplify this jargon into clear, empathetic, and short summaries.
- Voice Output: It speaks the simplified text aloud to the user.
Crucially, it works 100% offline. Whether the user is in a subway with no signal or handling a confidential document, EchoLens responds instantly with zero latency and zero data risk.
How we built it
We adopted a "Mobile-First" architecture, heavily leveraging the Arm AI software stack to ensure the app could run smoothly on standard hardware:
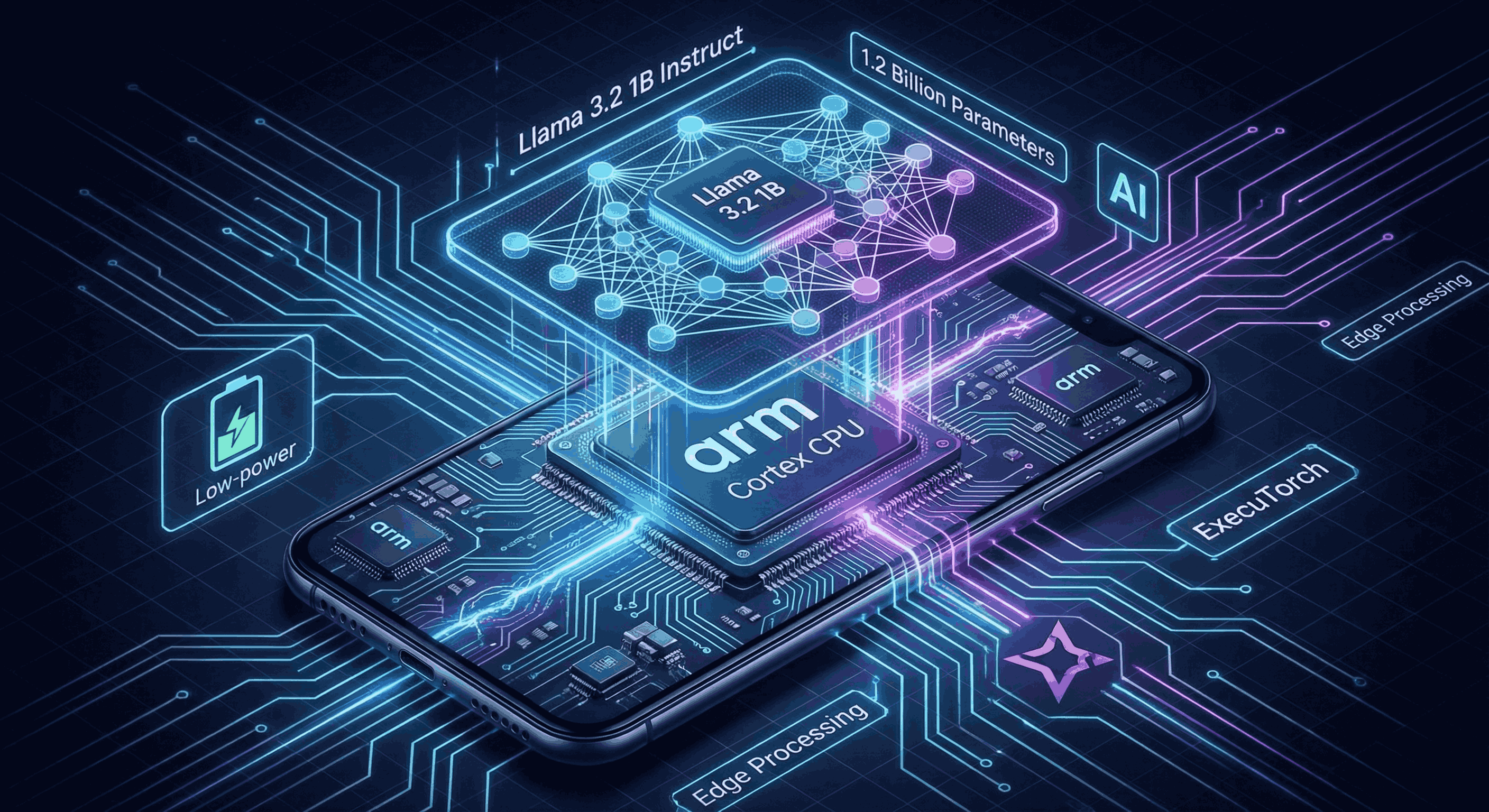
- The Brain (Model): We selected Llama 3.2 1B Instruct, a model optimized for edge devices.
- The Engine (ExecuTorch): Instead of standard PyTorch, we used ExecuTorch for the runtime. We set up a custom export pipeline to convert the model to a
.pte(PyTorch Executable) format. - The Optimization (Arm KleidiAI): This was the game-changer. We enabled the XNNPACK backend during export. This allowed us to utilize Arm KleidiAI kernels, which are highly optimized for Arm CPUs. We applied 4-bit quantization (Groupwise) to shrink the model size to under 1GB while maintaining accuracy.
- The Body (Android): We built the frontend in Java/Kotlin, integrating the ExecuTorch C++ library via JNI to load the model directly into RAM for high-speed inference.
Challenges we ran into
- Environment Hell: Setting up the ExecuTorch toolchain on Windows was a major hurdle. We faced significant issues with
flatbuffersversions and C++ build tools (CMake/Ninja) not playing nicely with PowerShell. We solved this by writing custom automation scripts to manage dependencies. - Quantization Balance: Finding the sweet spot between speed and coherence was tricky. We initially tried 8-bit quantization, but it was too slow for real-time conversation. Switching to 4-bit quantization via XNNPACK gave us the massive speedup we needed without breaking the model's ability to summarize correctly.
Accomplishments that we're proud of
- Running Llama Locally: Seeing the first token generate on a phone screen without an internet connection was magical.
- Performance: achieving a "conversational" token-per-second rate. Thanks to the Arm KleidiAI optimizations, the response feels immediate, which is critical for an accessibility tool.
- Privacy by Design: delivering a product that genuinely helps people without exploiting their data.
What we learned
- The Power of Edge AI: We learned that with the right optimization (ExecuTorch + Kleidi), mobile CPUs are incredibly capable. You don't always need a massive GPU to solve real-world problems.
- Model Exporting: We gained deep technical knowledge on the intricacies of the PyTorch export path—specifically how to map operators to XNNPACK to ensure they run efficiently on Arm architecture.
What's next for EchoLens
- Multimodal Vision: We plan to integrate a lightweight vision encoder (like MobileNet) to allow the model to "see" and describe scenes directly from the camera feed, not just text.
- Haptic Navigation: Adding vibration patterns to help visually impaired users center the camera on a document.
- Play Store Launch: Packaging the ExecuTorch runtime properly to release this as a free tool for the blind community globally.

Log in or sign up for Devpost to join the conversation.