-
-
-
-
-
-
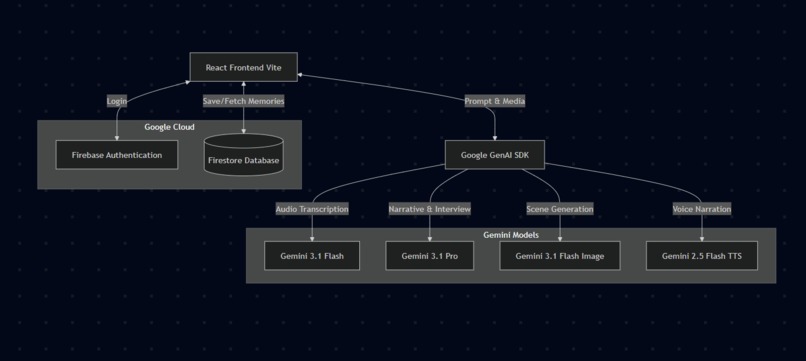
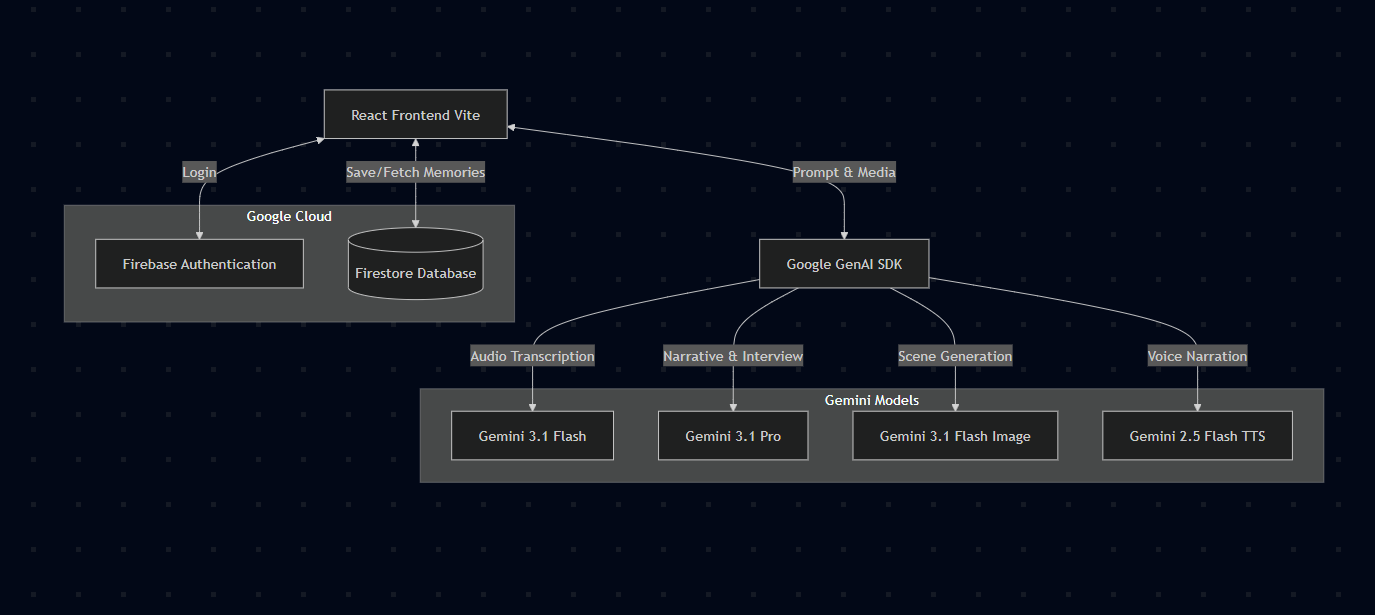
Architecture Diagram
Inspiration
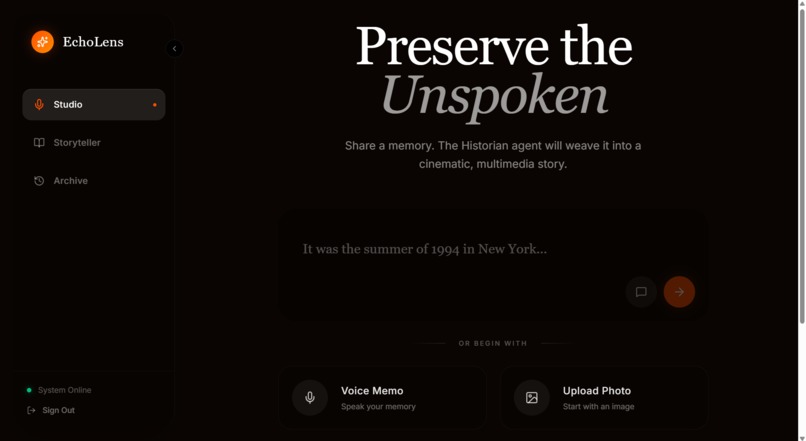
I have thousands of photos sitting in my camera roll, but the stories behind them fade away. Standard journaling feels like a chore, and looking at old photos often lacks the emotional context of the moment. I asked myself: What if an AI could act as my personal Creative Director, turning my messy, fragmented memories into a beautifully preserved cinematic experience? That lightbulb moment led me to build EchoLens.
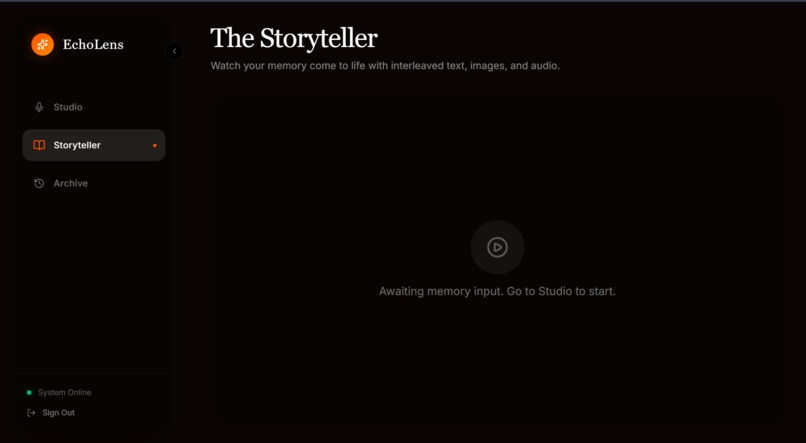
What it does
EchoLens is a multimodal AI agent built specifically for the Creative Storyteller track. It moves completely beyond the standard "text-in/text-out" chat box.
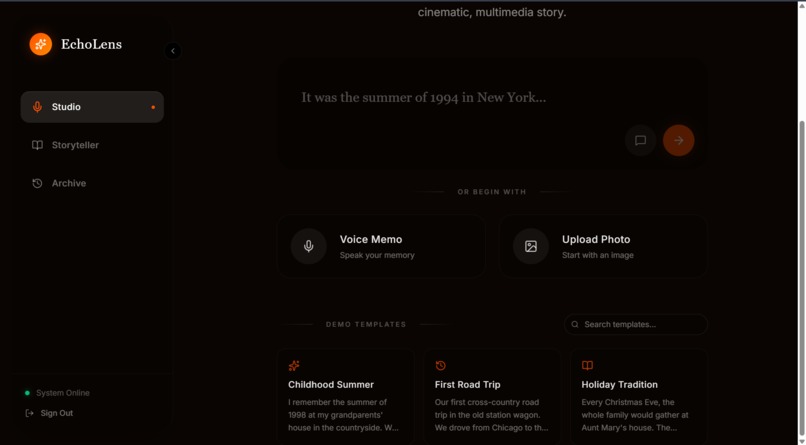
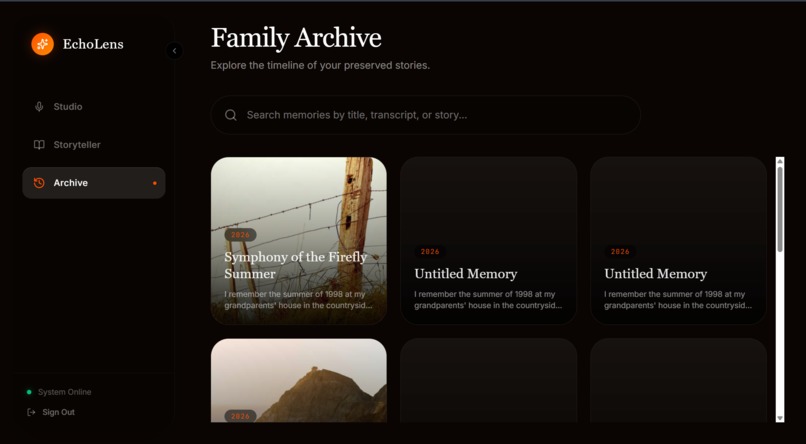
Here is the flow: You simply speak a raw memory into the app. The agent transcribes it in real-time. If your memory is a bit vague, the agent enters Interview Mode, asking a deep, evocative follow-up question to pull out sensory details. Once it has the full picture, the agent leverages Gemini's native interleaved output capabilities to generate a rich, mixed-media response. It seamlessly weaves together narrative text with custom, inline illustrations (generated on the fly to match each scene). Finally, it uses TTS to provide a warm voiceover narration. All of this is securely saved to a personal, searchable archive hosted on Google Cloud.
How I built it
I wanted EchoLens to feel incredibly fast, so I started by setting up a React frontend using Vite and styled it with Tailwind CSS to get that dark, cinematic look quickly. Instead of building a traditional backend, I went completely serverless using Google Cloud. I wired up Firebase Authentication so users could easily log in with their Google accounts, and I used Cloud Firestore as my NoSQL database to save the memories. The real heavy lifting happens on the client side using the Google GenAI SDK. I hooked up the browser's native MediaRecorder API to capture the user's voice and piped that audio directly into Gemini 3.1 Flash for near-instant transcription. Once I had the text, I passed it to Gemini 3.1 Pro, prompting it to act as a "creative director." The coolest part of the build was handling the interleaved output: I wrote logic to parse the narrative stream from Pro, identify scene breaks, and fire off parallel requests to Gemini 3.1 Flash Image to generate those nostalgic polaroid images on the fly. Finally, I took the completed story text and sent it to Gemini 2.5 Flash TTS to generate the audio buffer for the voiceover playback.
Challenges I ran into
My biggest technical hurdle was orchestrating multiple AI modalities concurrently to achieve a true "interleaved" output. I had to design a system that could parse the narrative text stream from Gemini 3.1 Pro, identify scene breaks, and immediately trigger parallel requests to Gemini 3.1 Flash Image without blocking the UI.
Additionally, I hit a wall with database limits. The high-quality base64 image strings returned by the Gemini Image model were massive, quickly exceeding Firestore's 1MB document limit. I hacked together a custom, client-side HTML5 Canvas compression algorithm that compresses the images on the fly before they are saved to Google Cloud, ensuring fast load times and efficient storage without sacrificing visual quality.
Accomplishments that I am proud of
I am incredibly proud of breaking out of the standard "chatbot" UI. EchoLens feels like a premium, cinematic storytelling tool. I successfully integrated four different Gemini models into a single, cohesive workflow that feels instantaneous to the user. Building a fully functional, secure, and multimodal application entirely on Google Cloud infrastructure as a solo developer over a hackathon weekend is a massive win for me.
What I learned
This project was a masterclass in multimodal AI orchestration. I learned how to effectively manage Gemini's native interleaved output capabilities and how to handle complex state management in React when dealing with multiple asynchronous AI streams (text, image, and audio). I also leveled up my Google Cloud skills, specifically around optimizing large media payloads for NoSQL databases.
What's next for EchoLens
I want to expand EchoLens's multimodal inputs to allow users to upload their actual vintage photos. Using Gemini Vision, the agent will analyze the real photos and weave them directly into the generated story alongside the AI illustrations. I also plan to add collaborative "Family Archives," where multiple family members can contribute their own voice memos to build a shared, multi-perspective story of a single event!
Built With
- firebase
- firebase-authentication
- firestore
- framer-motion
- gemini
- gemini-flash
- gemini-pro
- google-cloud
- google-genai-sdk
- react
- tailwind-css
- typescript
- vite

Log in or sign up for Devpost to join the conversation.