-
-
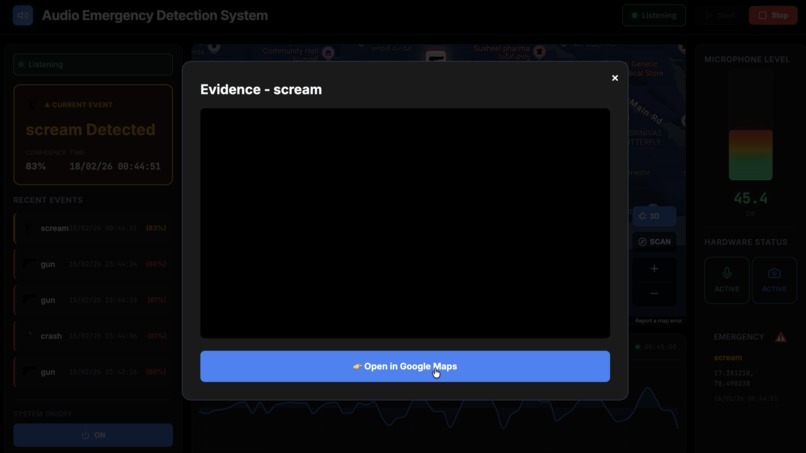
The Video Playback of the Live incident In the Website
-
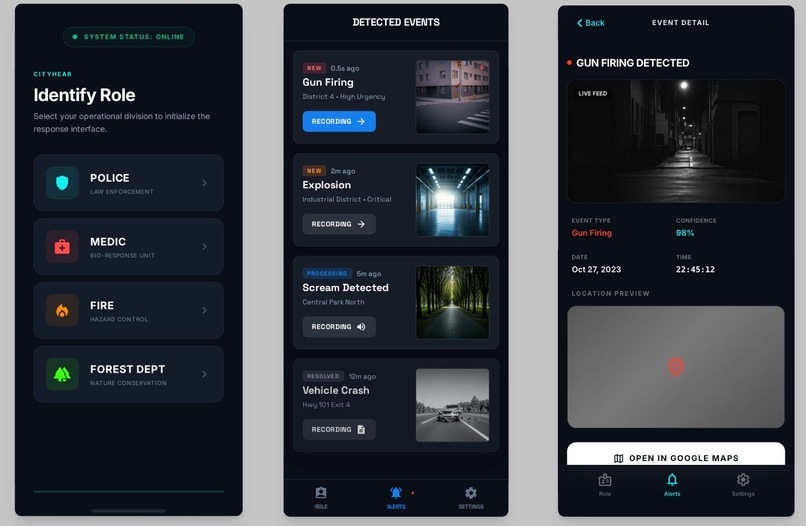
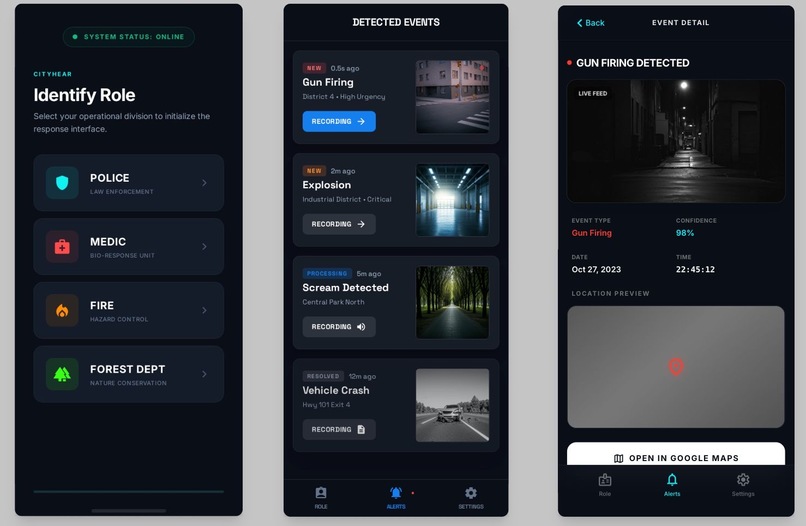
The App UI of the Project
-
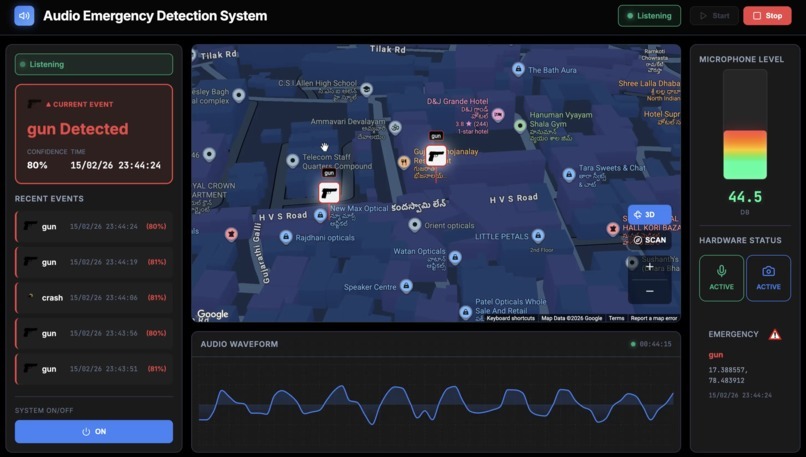
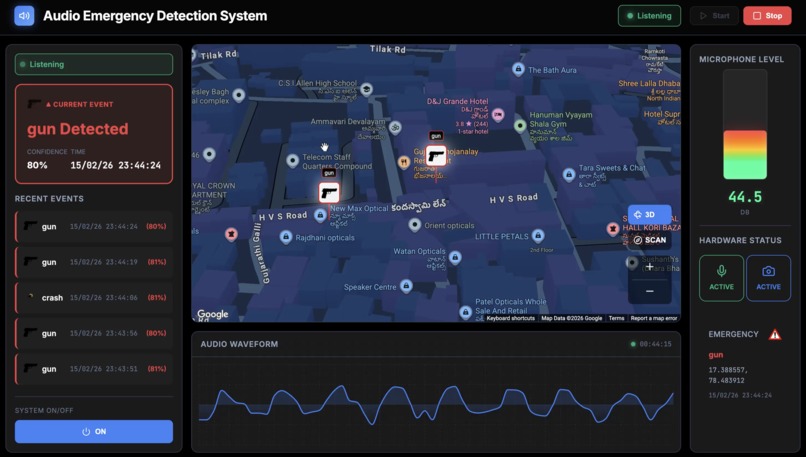
The Dashboard UI of the Project
🚨 EchoAlert — Proactive Edge-AI Acoustic Agents for Next-Gen Surveillance
Fuse passive security infrastructure with revolutionary Edge-AI to create autonomous, privacy-first ecosystems that listen, learn, and react in real-time — featuring on-device embedding extraction, Few-Shot memory banks, and instant cross-platform telemetry.
🚀 Inspiration
Modern surveillance systems have a critical, undeniable flaw: they are entirely passive. They silently record thousands of hours of video, essentially waiting for a human operator to notice a tragedy after it's already begun. But in critical emergencies—like active shooter situations or severe vehicle collisions—sound travels faster than visual confirmation. You hear the danger before you see it.
We realized that an autonomous agent could bridge this gap. By fusing deep learning audio analysis with high-performance edge computing, EchoAlert transforms static cameras into sentient acoustic environments. We wanted to build a system that doesn't just watch blindly, but actively listens, analyzes, and deploys real-time alerts—turning passive observation into active, life-saving protection.
🌌 What It Does
EchoAlert elevates standard security networks into a next-generation autonomous acoustic ecosystem:
🧠 AI-Powered Acoustic Intelligence
Custom Edge-AI Pipeline that continuously monitors environmental audio without relying on cloud computation.
Few-Shot Learning "Memory Bank" that acts as a digital fingerprint scanner for sound, adapting to new acoustic signatures without full neural network retraining.
Contextual filtering algorithms that distinguish between false positives (like a loud door slam) and genuine threats (like a gunshot).
⚡ Ultra-Low Latency Edge Systems
Localized audio processing running entirely on a Raspberry Pi 4, ensuring rapid detection.
TensorFlow Lite optimization pushing inference times to under 200 milliseconds.
Strict Privacy-First architecture guaranteeing that no raw, continuous audio is ever streamed to external servers.
🔮 Integrated Command Technologies
Real-time Command Dashboard providing a bird's-eye view of active alerts via Google Maps integration.
Role-based Mobile Responders pushing specific alerts to specific personnel (e.g., firefighters get explosion alerts, police get active shooter alerts).
Automated visual verification that captures and uploads a secure video snippet only when an acoustic threat is verified.
🛠 How We Built It
🎛 Next-Gen AI Architecture
YAMNet High-Level Feature Extraction — Bypassed standard classification to extract 1024-dimensional semantic embeddings from audio frames.
Metric-Based Meta-Learning — Implemented Cosine Similarity to compare real-time audio embeddings against known danger signatures in our Memory Bank.
Vectorized Audio Preprocessing — Engineered rapid downsampling algorithms (48kHz to 16kHz) and Mel Spectrogram generation for the neural network.
🔬 Cutting-Edge Technologies
Hardware Node — Raspberry Pi 4 Model B acting as the continuous acoustic sensor.
IoT-to-Cloud Backend — Python Flask server orchestrating local data, Cloudinary for video telemetry, and Firebase for real-time state management.
Cross-Platform Frontend — React.js + Vite for the tactical dashboard; React Native + Expo for the mobile field responder application.
💡 Revolutionary Development Process
Conversational AI Prototyping — Leveraged Gemini for rapid iteration on complex system architecture and intelligent agent logic.
Resilient Dual-Stack Networking — Designed a hybrid communication protocol using local APIs for raw speed and Firebase for remote reliability.
Acoustic Fingerprinting — Shifted from rigid supervised learning to flexible embedding comparison to drastically improve real-world accuracy.
⚙️ Challenges
🧠 Acoustic False Positives — Initially, the model confused loud, abrupt noises (claps) with gunshots; solved by implementing the 1024-D embedding Memory Bank for precise digital fingerprinting.
⚡ Edge Compute Load — Running deep neural networks on ARM processors caused bottlenecks; solved by applying TensorFlow Lite quantization and highly optimized NumPy vectorization.
🌐 System Synchronization — Coordinating the edge device, local backend, and cloud dashboard in real-time required a robust, fault-tolerant network orchestration framework.
🌟 Accomplishments
Delivered a fully autonomous AI acoustic agent that processes environmental audio with less than 200ms latency on a Raspberry Pi.
Created a strict privacy-first surveillance standard where no continuous audio is streamed to the cloud, protecting civilian privacy.
Implemented a flexible Memory Bank system that adapts to specific environmental acoustics without requiring massive dataset retraining.
Built a cohesive full-stack IoT ecosystem seamlessly bridging edge hardware, web dashboards, and mobile responder applications.
🧠 Key Learnings
Edge AI Optimization transforms theoretical machine learning into practical, deployable systems when techniques like vectorization and quantization are mastered.
Audio Engineering fundamentals—such as manipulating Mel Spectrograms and sample rates—are just as critical as the neural network architecture itself.
Resilient IoT System Design requires building graceful recovery protocols and fault-tolerant networks to handle real-world connectivity drops.
🔮 What's Next
🌐 Advanced Agent Evolution
Spatial Sound Triangulation — Deploying a multi-agent wireless sensor network to pinpoint the exact 3D coordinates of a threat.
Acoustic Mesh Networking — Enabling direct edge-to-edge communication so agents can relay alerts even during total internet outages.
🚀 Revolutionary Integrations
Autonomous Drone Response — Automating the deployment of visual assessment drones directly to the triangulated coordinates of a detected event.
Predictive Threat Analysis — Analyzing acoustic escalation patterns to predict and alert personnel before a physical altercation occurs.
Built With
- cloudinary
- css
- firebase
- google-maps
- javascript
- python
- react
- react-native
- tailwind
- vite
- yamnet

Log in or sign up for Devpost to join the conversation.