-
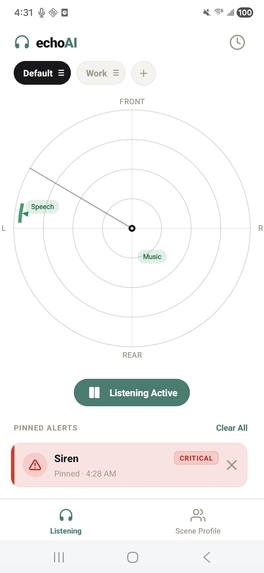
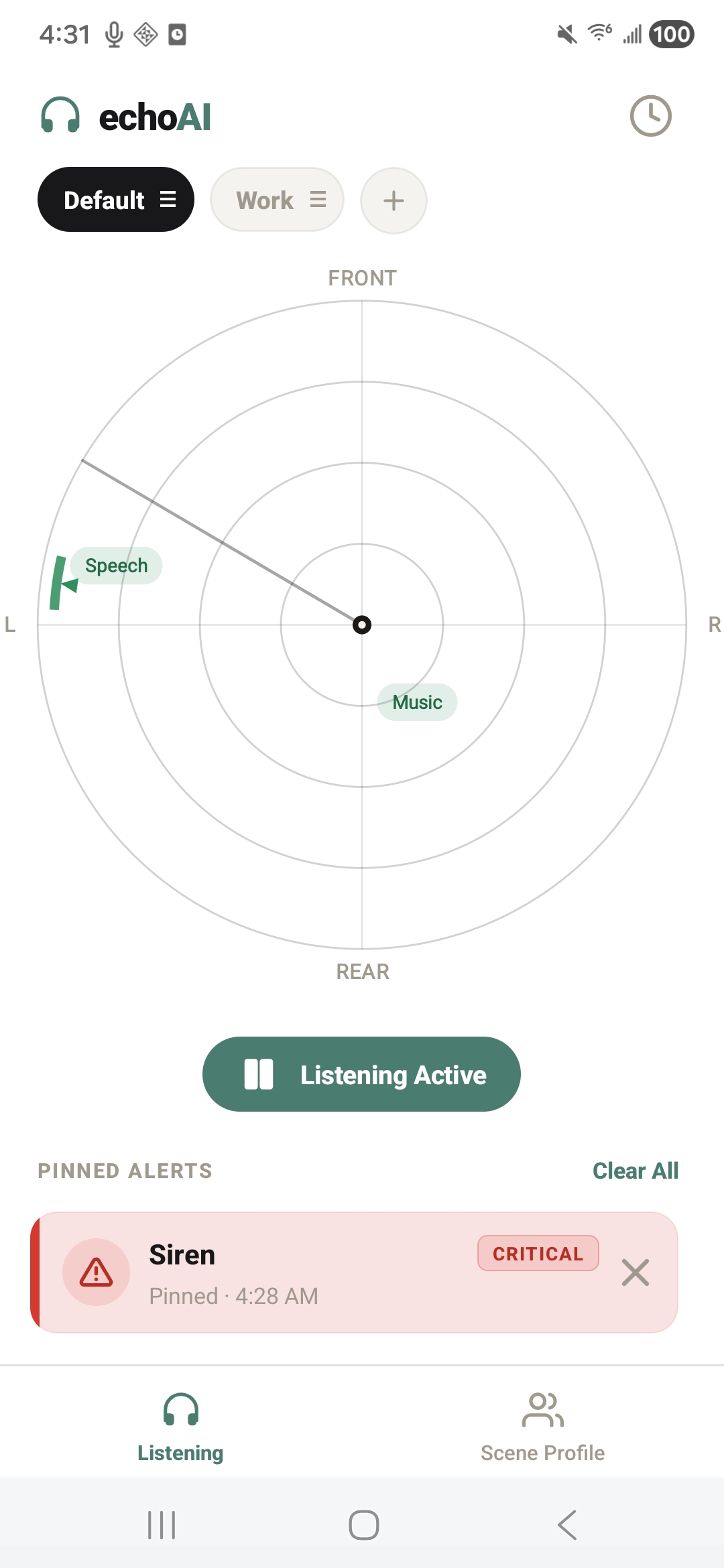
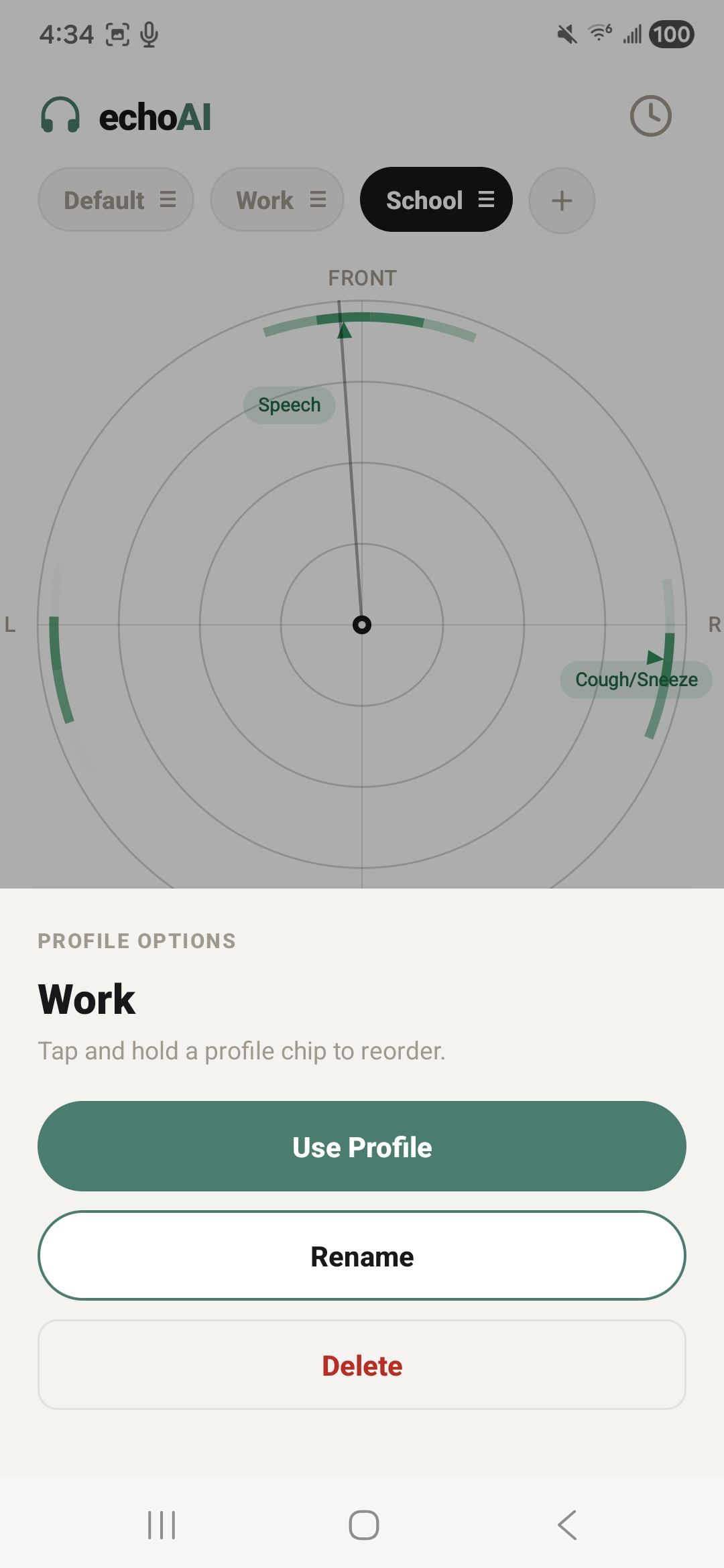
sound localization radar
-
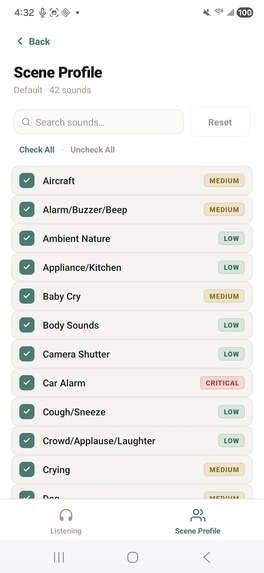
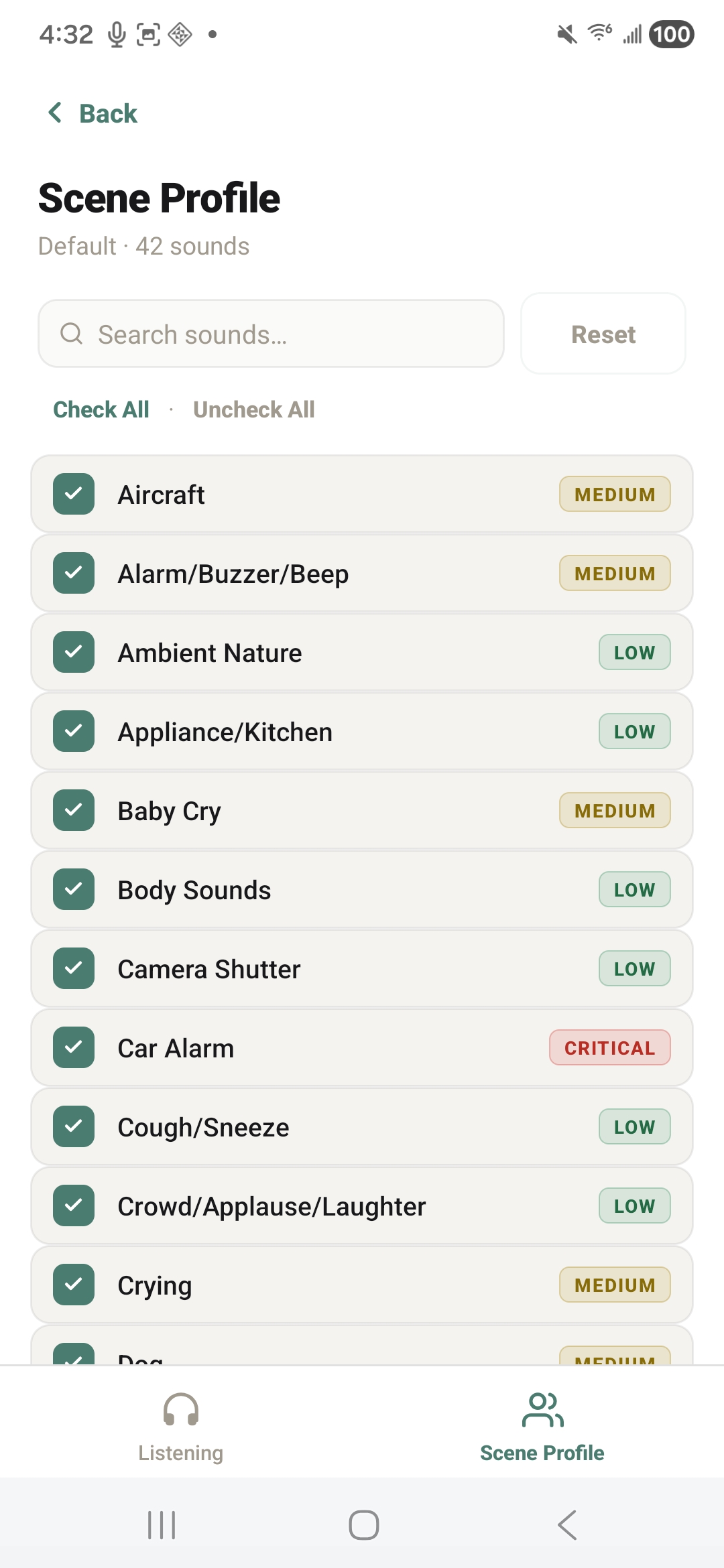
personalize sound detection
-
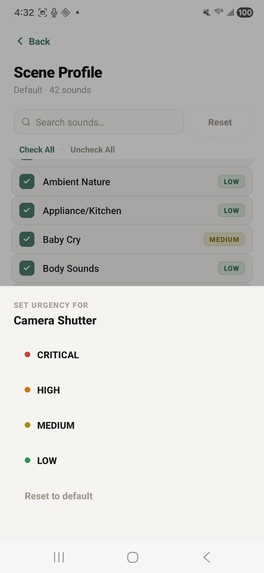
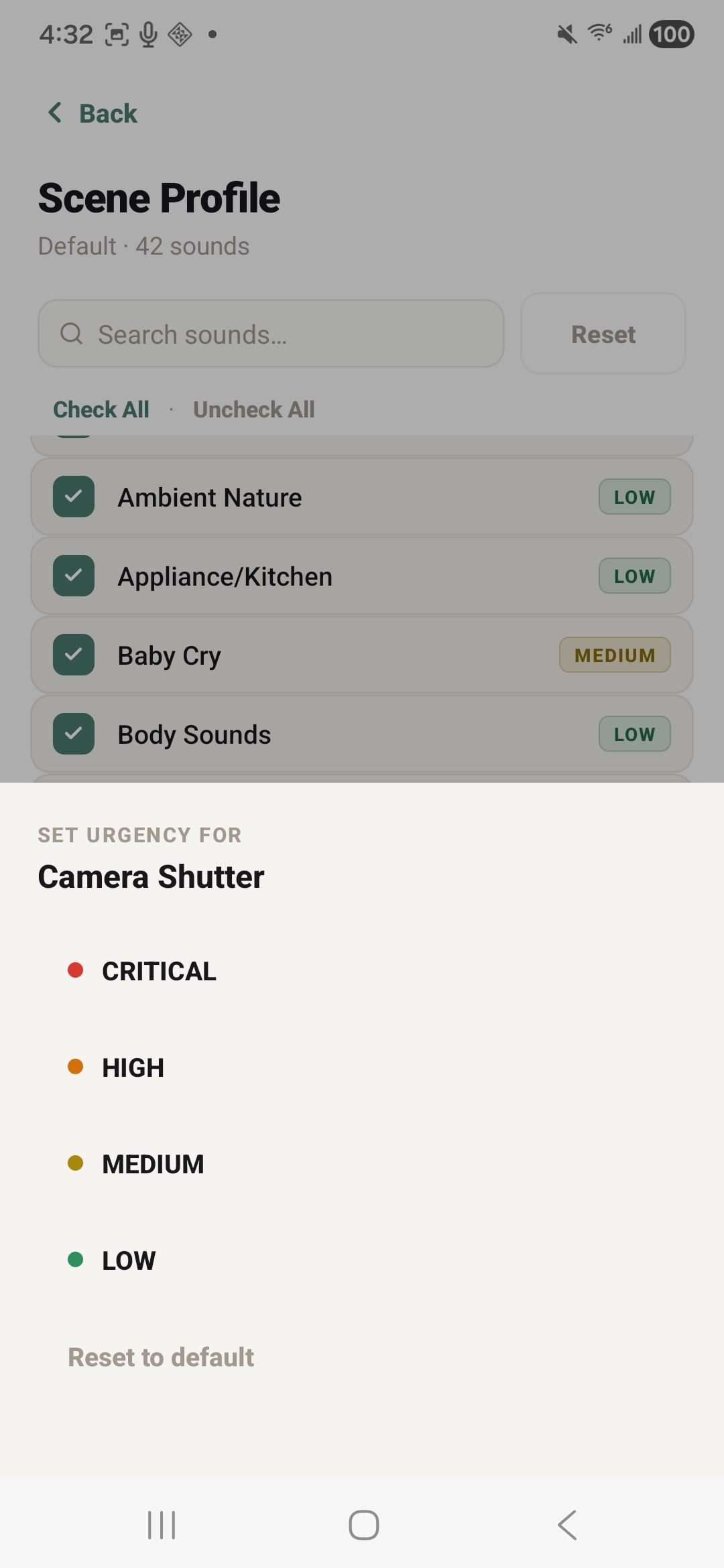
set custom urgency levels
-
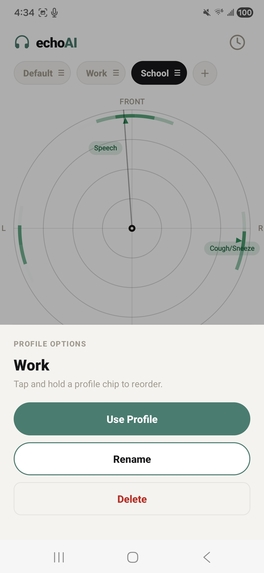
custom environment profiles
-
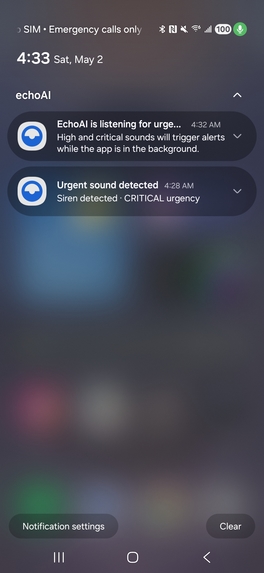
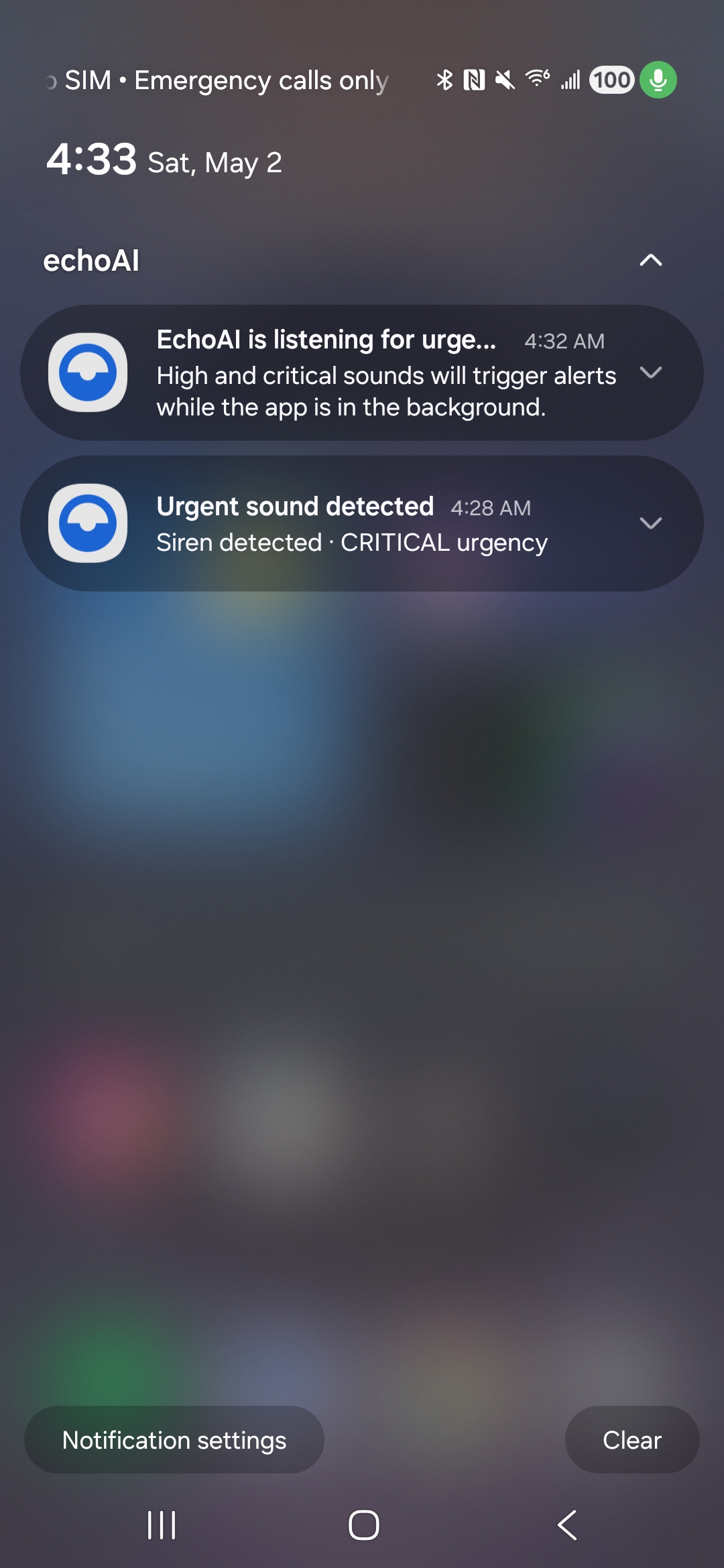
background notifications for passive listening
Inspiration
Deaf and hard-of-hearing individuals face significant challenges when relying on hearing to detect environmental hazards like sirens, car horns, alarms, or approaching footsteps. While hearing aids offer a solution, they are not universally accessible. According to the NIH, among US adults who could benefit from hearing aids, only a small proportion have ever used them (16% for adults ages 20–69, and 30% for adults 70+). Furthermore, studies indicate that hearing aids can distort spatial localization, be physically uncomfortable to wear if not perfectly calibrated, and remain financially inaccessible for many.
In the absence of hearing aids, traditional device accessibility alerts (such as screen flashes or device vibrations) signal that a sound occurred, but they fail to convey what the sound is or where it is coming from. Knowing that a sound occurred is helpful, but knowing its identity and origin in a fast, convenient fashion is an equally crucial factor for safety. Existing external solutions often require dedicated hardware (smartwatches, custom hearing aids) or constant cloud connectivity—compromising privacy and failing completely offline.
EchoAI bridges this gap. By consolidating a vast range of sound identification with visual urgency cue localization, it provides a fully on-device, phone-native accessibility tool. EchoAI empowers users who have difficulty accessing or using hearing aids with an everyday assistant that not only instantly identifies urgent sounds, but directs the user right to the source to address them.
What it does
echoAI continuously listens to the world around the user, classifies what it hears, tracks where each sound is coming from, ranks each one by safety urgency, and alerts the user through visual indicators and haptic feedback — all running entirely offline on the phone, with model inference accelerated on the Qualcomm Hexagon NPU via Google LiteRT.
How we built it
To build the application, we engineered a fully offline, coroutine-based Android architecture centered around on-device machine learning and advanced spatial audio processing. At its core, the system utilizes a LiteRT YAMNet model—hardware-accelerated via the Qualcomm Hexagon NPU using the NNAPI delegate—to continuously stream and classify audio into 42 distinct categories via multi-label noisy-OR pooling, ensuring absolute privacy since no audio ever leaves the device. To achieve precise spatial tracking despite hardware constraints, we implemented a dual-stream stereo capture pipeline that feeds into a multi-scale GCC-PHAT cross-correlation algorithm. This data is then fused with device IMU rotation vectors to power a custom rotational-aperture Bayesian belief system, which dynamically anchors concurrent sound sources to a smooth, custom-drawn 60fps 2D radar UI. We balanced this heavy processing with strict battery efficiency and user-centric design; the app intelligently throttles classification to 2Hz, allows for deep personalization through custom scene profiles and tiered haptic alerts, and seamlessly transitions to a background foreground service that pauses the heavy localization math while still delivering critical notifications and logging a 24-hour persistent history.
Challenges we ran into
Throughout the development process, we encountered a multitude of significant technical hurdles that complicated our localization efforts. Primarily, we lacked direct access to pure, raw audio data; instead, the data we did retrieve was heavily post-processed and prone to duplication. This issue was exacerbated by system constraints that limited us to streaming only two channels into the buffer simultaneously, with any additional channels triggering further data duplication. Compounding these software limitations was a severe physical constraint regarding our microphone geometry. Because our array consisted of a 1D line of closely spaced microphones—unlike the highly specialized, dedicated geometries typically relied upon in academic research—it was impossible to achieve greater than 1D localization natively. This ultimately forced us to integrate an IMU and rotational tracking as supplementary data sources to map the space. Finally, beyond our specific system constraints, we had to navigate the broader challenges of acoustic localization—which remains a complex, open research problem—particularly when contending with difficult environmental factors like background noise and overlapping sound sources.
Accomplishments that we're proud of
We are incredibly proud to have engineered EchoAI into a highly unique and intuitive accessibility tool that genuinely empowers deaf and hard-of-hearing individuals by addressing a critical real-world pain point: providing not just real-time background alerts, but precise directional localization and classification for 42 distinct sound classes. A major technical accomplishment was achieving this complex functionality with exceptional system efficiency; by intelligently caching our expensive YAMNet machine learning inferences, reusing additive audio signals, and decoupling the heavy background audio processing from our smooth 60fps UI rendering, we delivered a low-latency, battery-friendly experience that successfully runs even when the device is locked. Furthermore, we successfully designed custom algorithmic optimizations—most notably a highly performant Bayesian belief estimation loop executing in mere microseconds—to ingeniously bypass severe physical microphone limitations on our target hardware without resorting to heavy, battery-draining ARCore camera tracking. Ultimately, we transformed a formidable open research problem into a seamless, highly customizable mobile application that gives users immediate, actionable awareness of the urgent sounds in their environment.
What's next for echoAI
Moving forward, our primary focus is expanding device compatibility and integrating external acoustic hardware—such as USB-C mic arrays or wearables—to enable true, rotation-free spatial localization. Alongside this, we plan to enhance our software pipeline by incorporating deep learning-based Direction of Arrival (DOA) estimation and multi-device sensor fusion to improve tracking accuracy in complex, noisy environments. Finally, we will conduct extensive field testing with the deaf and hard-of-hearing community to ensure our environmental alerts remain as intuitive and accessible as possible.
Built With
- android-studio
- gradle
- kotlin
- litert
- tflite









Log in or sign up for Devpost to join the conversation.