-
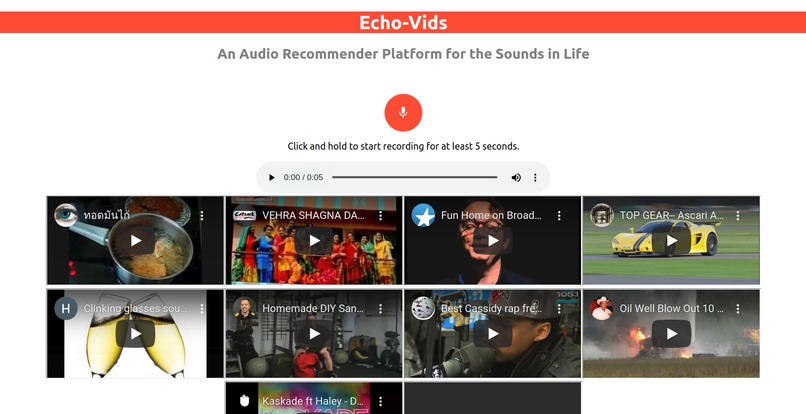
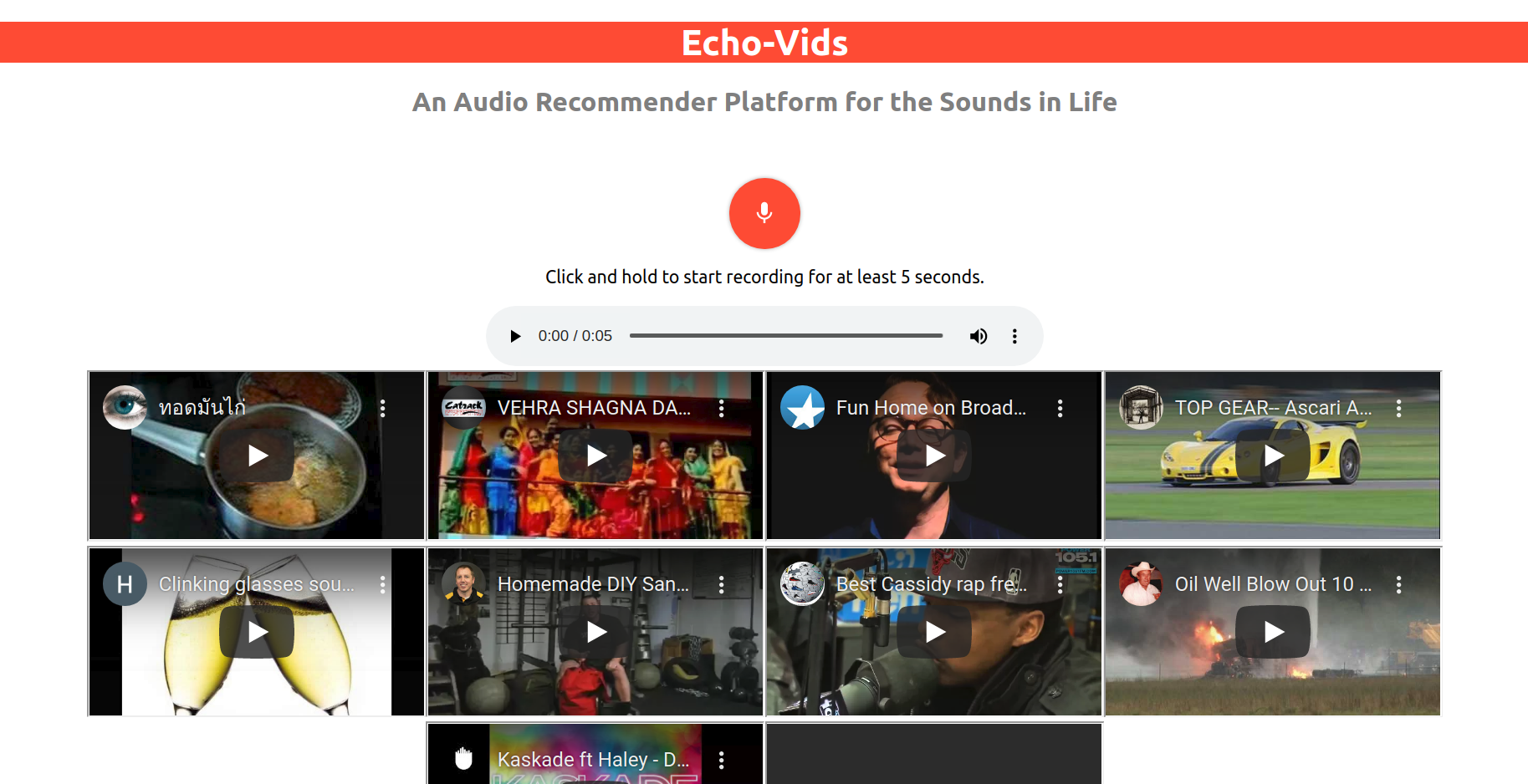
Screenshot of Application
Inspiration
Our team understands the importance of recommendation systems and the desire of the industry to research, develop, and deploy a strong, reliable recommender system for its users. Any contribution to the recommendation engines research is a good step forward for computer science.
Additionally, our application will allow video editors to find and obtain audio sounds to make their cinematic visions a reality.
What it does
Given a live recording of audio, our application will recommend audio files timestamped at the part most similar to the provided live recording. For this iteration, our project focuses on YouTube videos but the underlying audio recommendation system can be adapted and scaled upwards for a variety of platforms and services. Companies or individual users would have the ability to upload their own audio database for audio recommendations. For example, if you are a video-sharing social network company that allows users to include music/audio in their videos and don't want to get copyrighted, this serves as a means to finding similar sounding audio clips for users.
How we built it
On a high level, our team utilized a publically available TensorFlow model that encodes audio from YouTube videos and an incoming audio file and uses that embedding to determine YouTube videos that are similar to that uploaded audio recording.
The following is a description of the machine learning back-end. The pattern learning aspect of our project references methodologies used in deep retrieval. In this application, the audio is embedded using the following procedure: (1) the time-domain audio files are acquired, (2) those files are converted into the frequency domain and represented as a mel-spectrogram, (3) the audio files are converted into 128-dimensional embeddings, and lastly (4) the Euclidean distance is calculated between each indexed audio embedding and the user's audio query. Imagine an embedding space (a simple XY coordinate system, for instance) where audio files of crying babies are near the origin and audio files of revving engines are at the upper right corner. The uploaded audio file will be plotted in this space and top-K nearest neighbors are located by closest distance to the uploaded audio file. Our system uses ScaNN, a state-of-the-art approximate nearest neighbor (ANN) search algorithms, yielding the highest queries per second for a given accuracy as compared to 11 other vector similarity search libraries (https://ai.googleblog.com/2020/07/announcing-scann-efficient-vector.html). In general, ANNs are highly optimized search algorithms used by many popular search engines and recommendation systems.
We have used a subset of Google's AudioSet dataset to train our model. The original AudioSet dataset contains 2 million, 10-second clips of YouTube videos. The data is labeled into 527 classes (single labels) and other noted features are the start time of the audio from the YouTube dataset. VGGish is the embedder and our underlying encoder model (https://github.com/tensorflow/models/tree/master/research/audioset/vggish).
Our team utilized a React framework programmed in JavaScript to develop a front-end interface. To record the audio files we used a publically available library (react-mp3-recorder). A Flask server was used on the backend to handle queries by the frontend.
Challenges we ran into
Our team coded an operational back-end Python server that successfully produced a list of YouTube video recommendations based on a provided audio recording. However, we struggled to connect our front-end React application with the Flask server (aka send audio files from the front-end to the back-end ). For hours, we tested and debugged various audio capture libraries and HTTP requests examples. This problem required all hands on deck, and ultimately a solution was reached through collaboration.
Another large challenge was developing a React application given our team's limited experience with the framework. Many small and large problems and frustrations arose due to the collective unfamiliarity. Our solution to this problem was to start at the very beginning and fully understand the foundations of React. As a team, we watched a 2-hour React tutorial together (React watch party!) and worked collectively in deconstructing and address each member's questions. We came together and helped each other out.
We also had difficulties with the engine recommending unavailable videos. These videos are unavailable because the dataset was released in 2017 and some videos have been deleted since the creation of the dataset. A solution we implemented was to ping YouTube for the status of the video and only show available videos.
Lastly, another challenge (possibly the most critical challenge) was the accuracy of our model and the performance of the recommender. We tested various sounds ranging from laughs, yells, claps, and songs and noticed that the engine's recommendation would not be entirely reliable. Another important aspect to note is that the subset training dataset is chosen randomly from the larger, complete set. As such this subset is mostly unbalanced between the labels and categories and bias arises. Our first solution was to increase the size of the training dataset. We hypothesized that an enlarged dataset would gather a larger range of sounds and classifications, and reduce the potential for bias. The performance did improve with a larger training subset. Another solution we implemented was testing various similarity calculations. We looked at the performance of calculated Euclidean distance and Dot Product distance. In our project, we saw that Euclidean distance performed better. We believe that the poor recommendation results may be the result of overlapping clusters. Meaning, too many sounds in the dataset that are too generalized and not distinguishable enough.
Accomplishments that we're proud of
Our team was highly motivated and interested in implementing a recommendation engine. Recommendation systems have applications that span across all sectors of business whether it be media entertainment, tourism, or product. In addition to being an important function to many platforms, many complex questions such as the cold-start problem or biased datasets result in establishments spending copious amounts of time and labor to create a strong and reliable recommender. It was extremely exciting learning about, understanding, and ultimately implementing such a crucial application that is desired by so many companies. Our team truly believes we developed a project with transferable skills that transcend beyond this hackathon and will propel our career aspirations. We are so proud of our progress.
What we learned
Firstly, our team discovered the complexities of recommendation engines. The basis of any good machine learning solution, especially recommendation, is LOTS of refined data. Currently, classic datasets have established applications. For instance, large movie datasets are used by Netflix for movie recommendations. Novel recommendation solutions are difficult because of a lack of large datasets.
Our team was also exposed to feature engineering. We learned a lot about audio feature extraction dealing with audio capturing technology in the front-end. Additionally, the team's knowledge of React was strengthened because of our front-end development.
What's next for Echo-Vids
Our application currently searches by recorded audio clips. The next step would be to search by description. In May 2021, a paper detailing two datasets for natural language processing was released. Our team envisioned applying those datasets to TensorFlow Recommenders which is a library that allows for easier deep retrieval.
Built With
- flask
- googlecolab
- javascript
- jupyternotebook
- python
- react
- tensorflow
- vscode


Log in or sign up for Devpost to join the conversation.