-
-
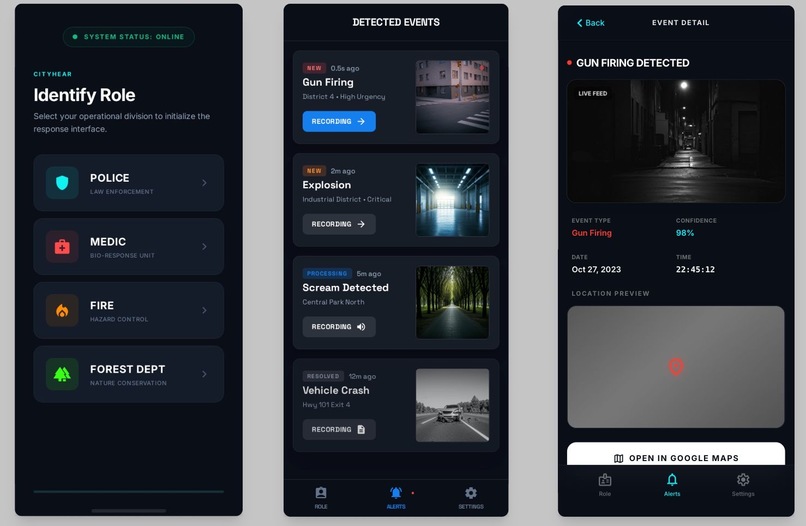
Mobile App
-
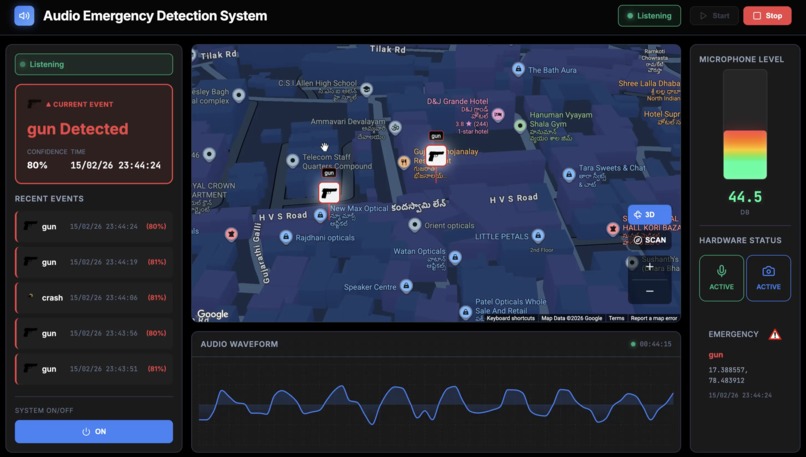
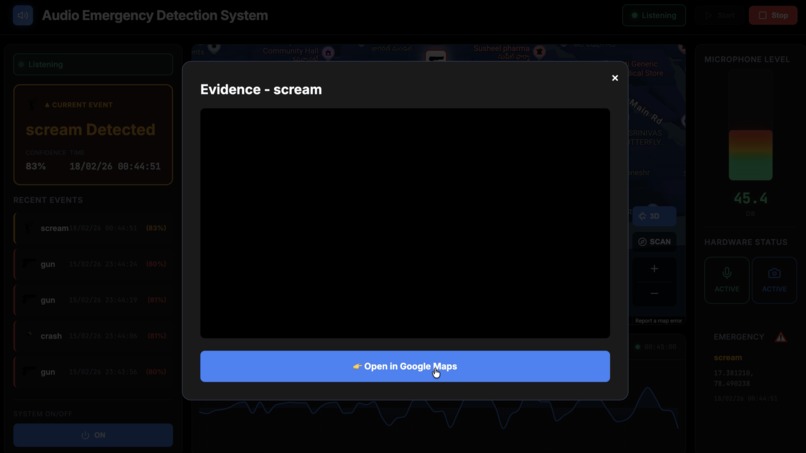
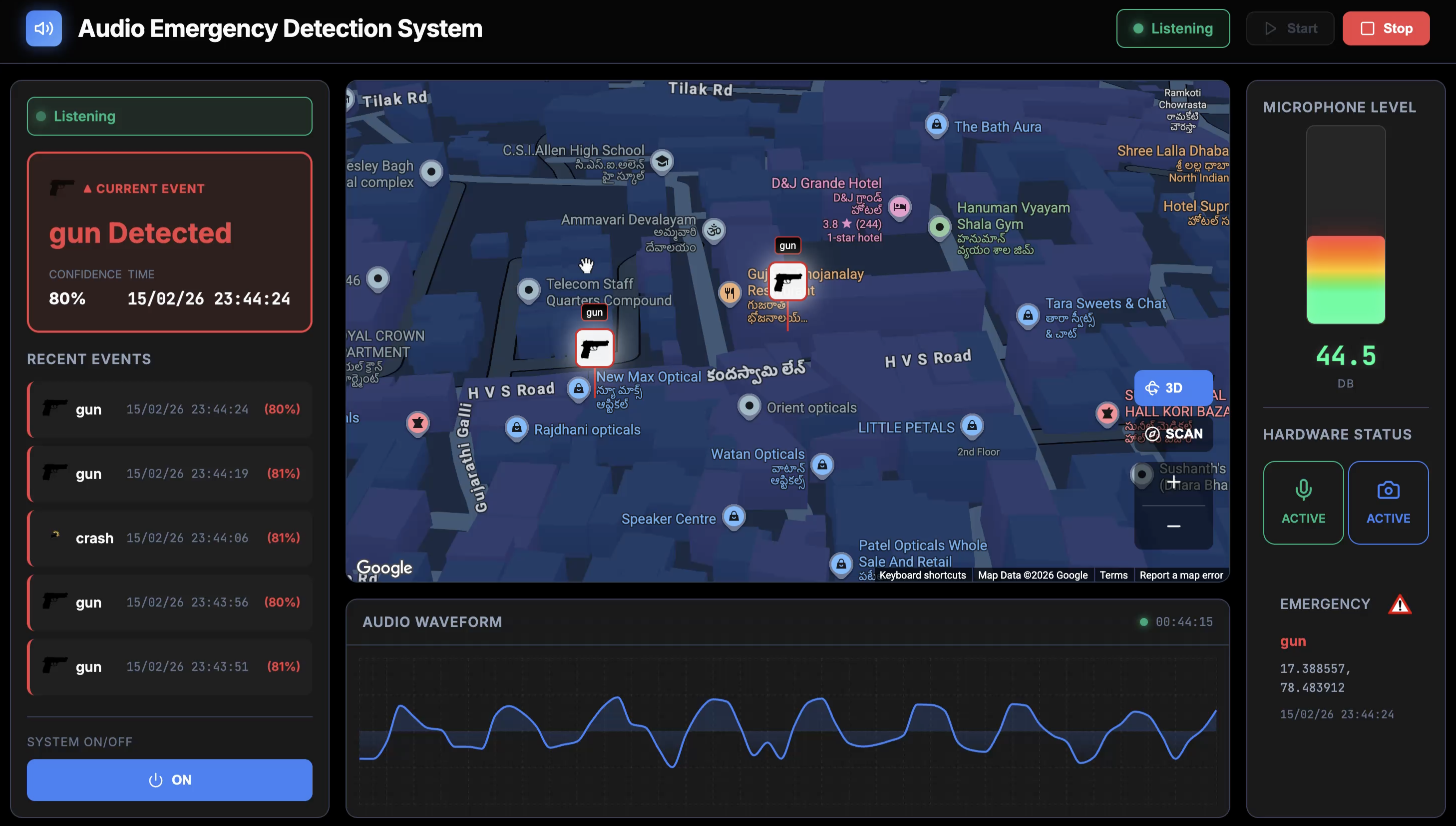
Dashboard
-
Detected Event Details Screen
Inspiration
Modern surveillance systems have a critical flaw: they are passive. They record thousands of hours of video, but they don't "understand" what is happening until a human is monitoring the footage continuously..... often too late. We realized that in emergencies like active shooter situations, car crashes, or assaults, sound travels faster than visual confirmation. A scream or a gunshot is an immediate indicator of danger that a camera might miss if the event is out of frame. We wanted to build a system that doesn't just watch, but listens and reacts in real-time, turning passive surveillance into active protection.
What it does
EchoAlert is an Edge-AI powered acoustic surveillance system.
- Listens: It continuously monitors audio using a Raspberry Pi.
- Detects: It identifies specific dangerous sound signatures (Gunshots, Screams, Explosions, Car Crashes) locally on the device using a custom AI pipeline.
- Alerts: Within seconds of detection, it pushes an alert to a central Command Dashboard and a Mobile App for security personnel.
- Verifies: It automatically captures and uploads a video clip of the event for immediate evidence, while filtering out non-emergencies to protect privacy.
How I built it
We built a full IoT-to-Cloud pipeline:
- Hardware: Raspberry Pi 4 Model B acting as the edge node.
- AI/ML:
We used Custom Trained Model and TensorFlow Lite to run a quantized YAMNet model (a deep neural network
for audio event classification). - The "Secret Sauce":
Raw model predictions were noisy, so we implemented a Few-Shot Learning "Memory Bank". We extract 1024-dimensional embedding vectors from the model and compare them using "Cosine Similarity"
against known danger signatures. This drastically reduced false positives. - Backend: A Python Flask server handles data aggregation, video uploads (Cloudinary), and logs events to Firebase.
- Frontend:
Dashboard: Built with React.js + Vite and Google Maps API for a real-time "Command Center" view.
Mobile App: Built with React Native + Expo for field responders, featuring role-based alerts (e.g., Firefighters get
fire alerts, Police get all alerts, etc).
Challenges I ran into
1. **Reducing False Positives**:
Initially, the model would confuse loud claps with gunshots. We solved this by moving from simple
classification to Embedding comparison, which acts like a "digital fingerprint" match for sound.
2. **Latency vs. Accuracy**:
Running deep learning on a Raspberry Pi is heavy. We had to optimize the audio preprocessing
(fasr downsampling from 48kHz to 16kHz) and use TFLite to get inference times under 200ms.
3. **Network Complexity**:
synchronizing the Edge device, local backend, and cloud dashboard required robust networking.
We implemented a dual-stack approach (local API for speed, Firebase for remote reliability).
Accomplishments that I'm proud of
- Real-time Inference: Achieving reliable detection on a Raspberry Pi with minimal latency (<200ms).
- Privacy First: Implementing local processing so no raw audio is ever streamed to the cloud, setting a new
standard for surveillance privacy. - Memory Bank System: Creating a flexible system that can learn new sounds without needing to retrain the entire
neural network, making it adaptable to different environments. - Full-Stack Integration: Successfully connecting hardware, web, and mobile platforms into a cohesive ecosystem.
What I learned
- Edge AI Optimization: I gained deep insights into optimizing Python code for ARM processors, specifically using
NumPy vectorization for efficient audio processing. - Audio Engineering: Understanding the nuances of Mel Spectrograms and sample rates was critical for fine-tuning
the model's accuracy. - Resilient System Design: Learning to build a fault-tolerant IoT system capable of handling network interruptions
and recovering gracefully.
What's next for Echo Alert
- Sound Triangulation: Implementing a multi-device setup to pinpoint the exact 3D location of a sound source.
- Drone Integration: Automating the deployment of camera drones to the coordinates of a detected event (e.g., a gunshot) for rapid visual assessment.
- Mesh Networking: Developing a mesh network capability to allow devices to communicate directly, ensuring
system functionality even during internet outages.
Built With
- cloudinary
- css
- firebase
- google-maps
- javascript
- python
- react
- react-native
- tailwind
- vite
- yamnet




Log in or sign up for Devpost to join the conversation.