-

Opening
-
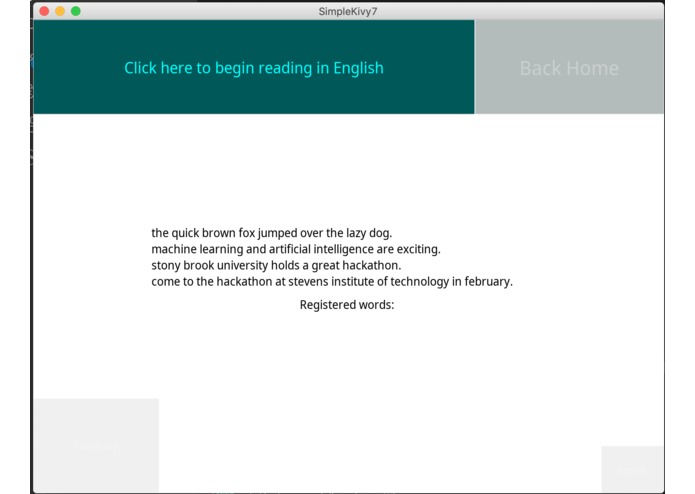
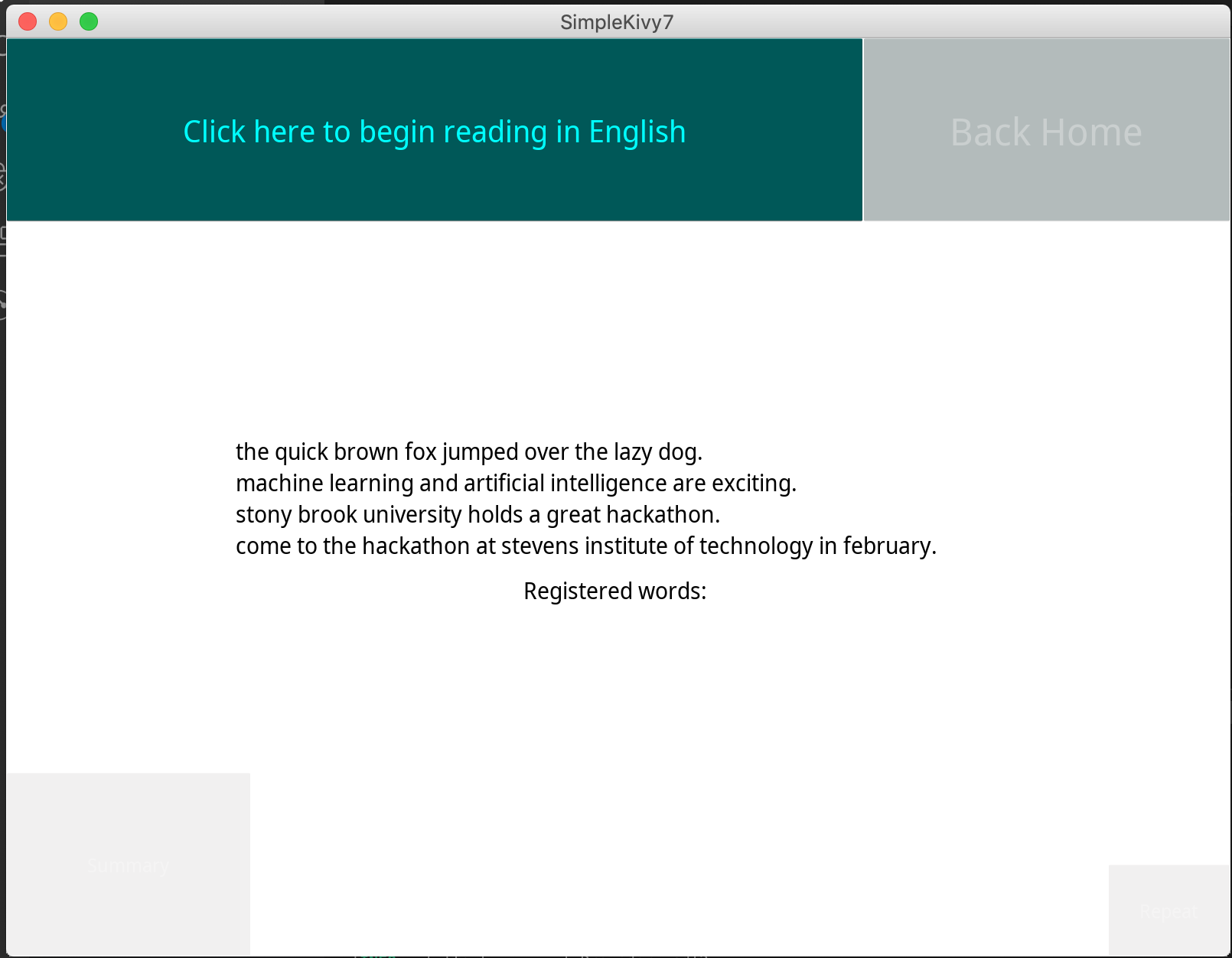
English Learning Section
-
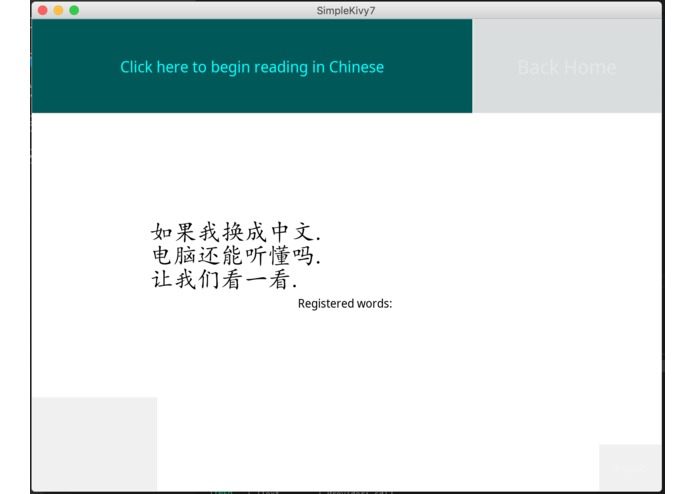
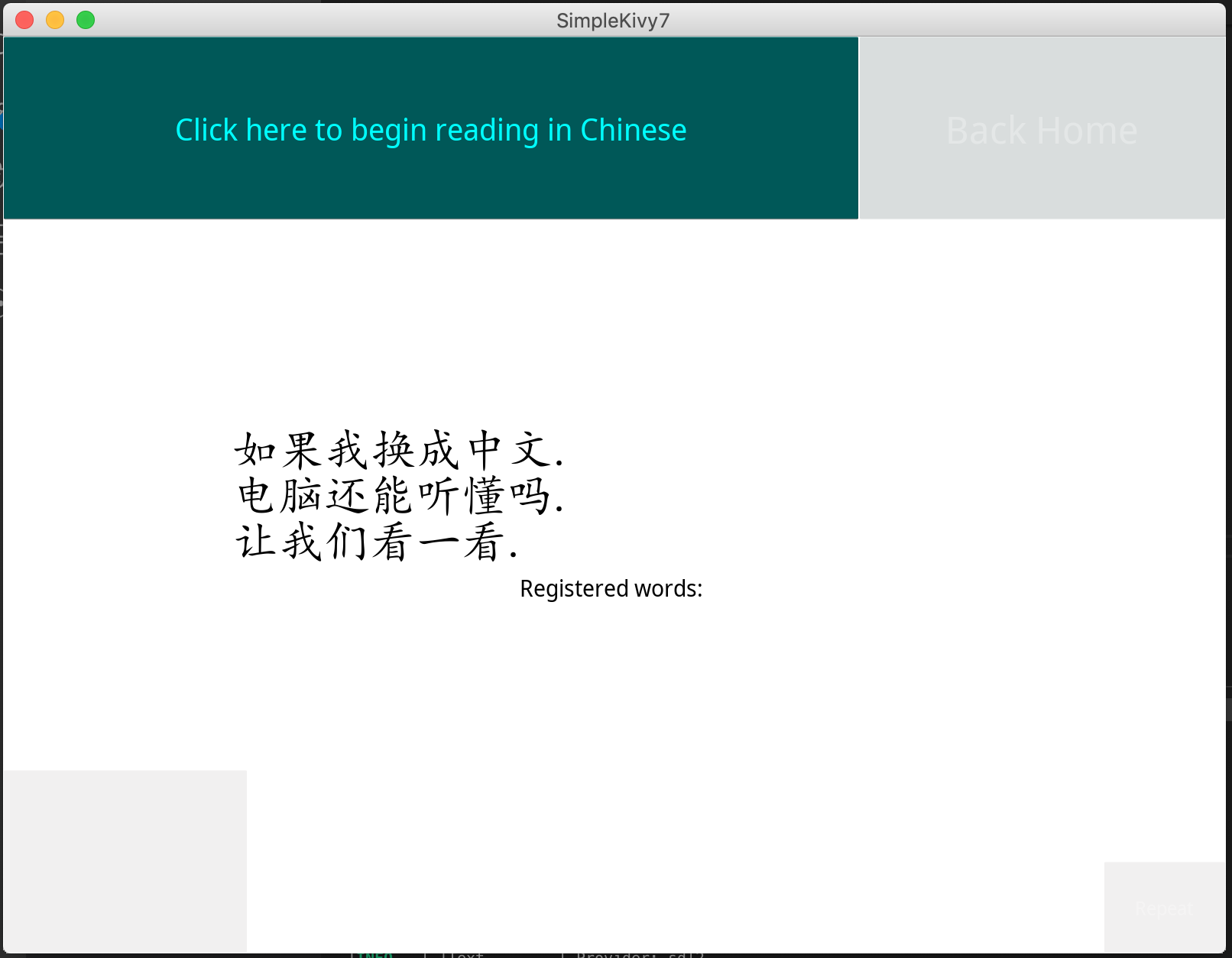
Chinese Learning Section
-
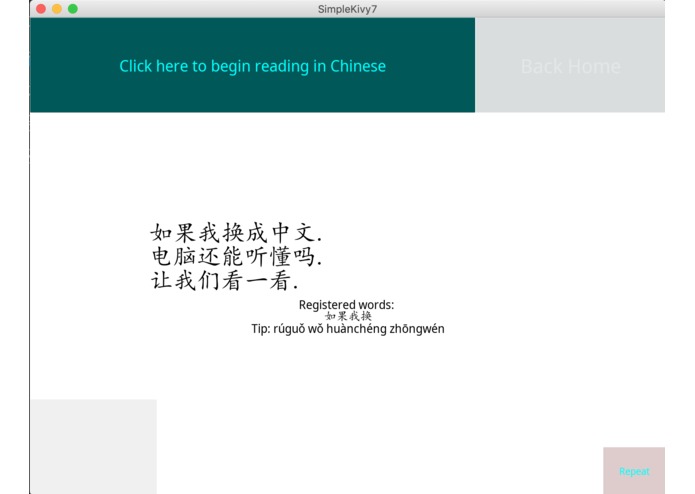
Chinese Learning Section
-
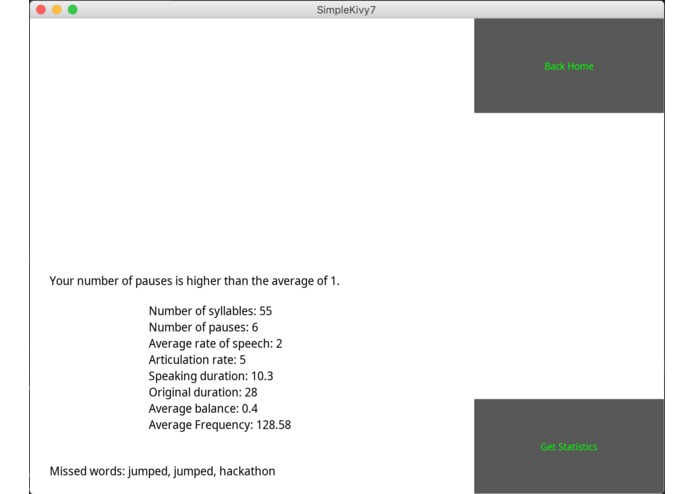
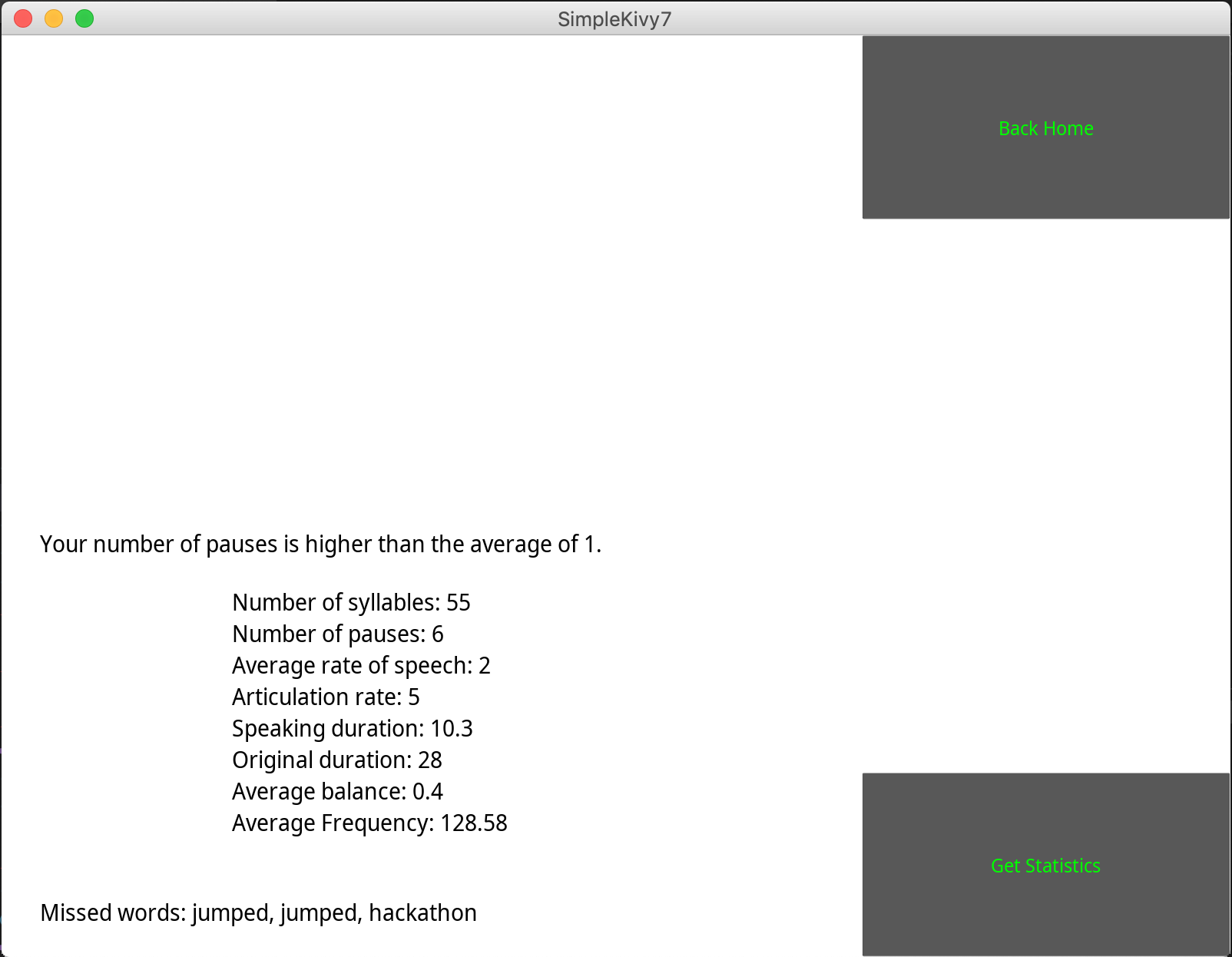
End of Lesson Statistics


Inspiration
The world never possessed a dull sound to creators Max Shi and Hamzah Nizami. Growing up bilingual, they knew the flexibility and richness that lay in the timbre of the human voice. More importantly, it enriched their lives with a far more humanistic element - the power of human connection. Language is often used as the social glue that binds a society and when used to it's highest caliber, can illuminate the darkness of ignorance and catapult those disadvantaged into better states. This highway of opportunity is only possible due to the connection that language provides. It provides a mechanism for understanding the plight of understanding, a catalyst for empathy.
With the power of language ever-present in their minds, and a growing distaste in the lack of empathy that is encroaching on modern society, Max and Hamzah decided to create echo, a software that teaches and sharpens people's secondary language skills by making them read passages in their respective secondary language and providing them with useful information to increase their fluency with speaking in a different language so that they can eventually sound like a native.
What it does
Using computer speech recognition and state of the art natural language processing techniques, echo provides people with the ability to learn and sharpen their secondary language skills by reading passages in the respective secondary language. Once accurately done, echo provides with useful statistical information such as the average pause rate of native speakers in the language compared to your average pause rate when speaking. The hope of providing all this information is to use it to better align the rhythm of their speech to that of a native of the language so that they can speak like a native.
How we built it
We used Python, Kivy, and the Google Cloud Speech platform to build echo.
Challenges we ran into
- Understanding and finding useful ways to use state of the art NLP libraries. Turns out NLP is very hard!
- Being able to parse the entire byte stream of audio data so that we can use user inputted speech and compare it with a native.
Accomplishments that we're proud of
To work around Google Cloud not allowing us to access the full byte stream of audio data, we built our own buffer parser! This allowed us to get the full .wav file recording of user speech and thus allowed us to incorporate a host of new information and capabilities into the product such as pause rate, speech duration, and more! This information can hopefully help users find the rhythm at which people speak their native languages and allow them to work towards a level of competency in the language that makes them sound like a native.
Using the Google Speech Recognition software to track what words have been spoken and what words users are having difficulties with and providing appropriate tips.
What we learned
- How to use Kivy
- Basics of NLP and things like Praat's Algorithm
- Google Cloud Platform
- Multi-threading in Python
What's next for echo
- Becoming the de-facto language learning app in the world!
Built With
- google-cloud
- google-speech-to-text
- google-text-to-speech
- kanjialive
- kivy
- merriam-webster-dictionary
- multi-threading
- my-prosody
- pyaudio
- python



Log in or sign up for Devpost to join the conversation.