Inspiration
In the Pacific Northwest, the "Big One" earthquake is bound to hit sometime in the future, so we thought it would be useful to create a predictive model to help determine when earthquakes happen. As a result, we thought this would be a great opportunity to learn more about the realm of data science, data analysis, and predictive modeling.
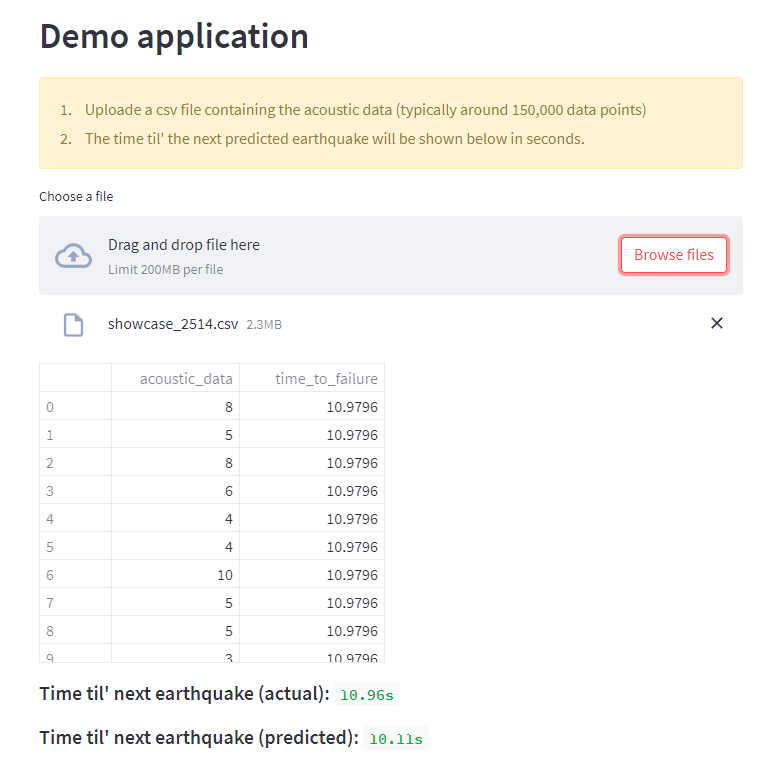
What it does
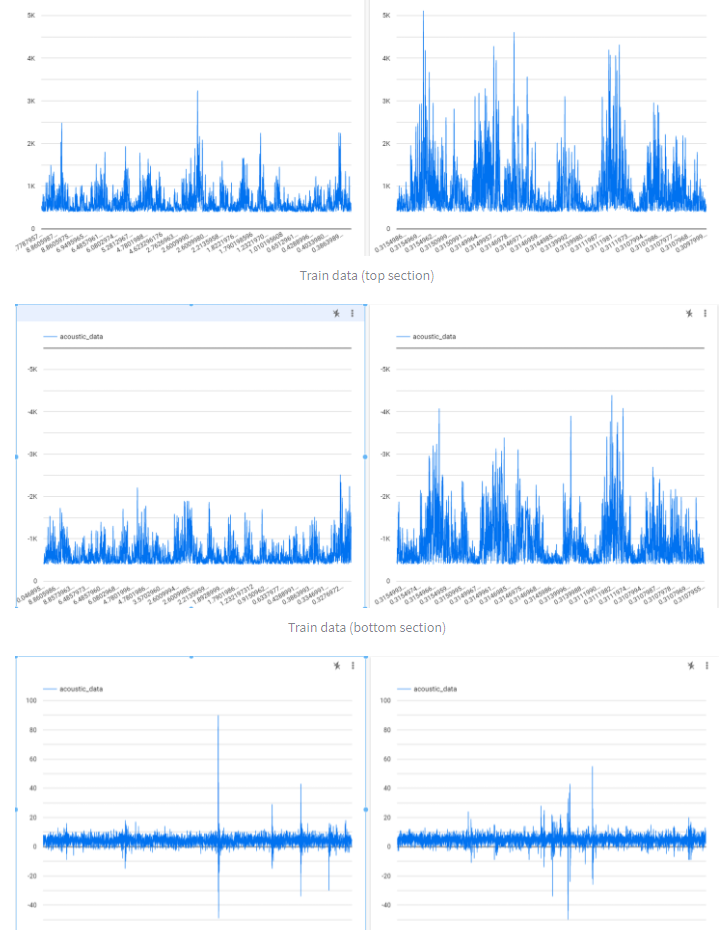
This project trains a regression model to predict the time in seconds from an earthquake to occur. The training is done using seismic data that is publicly available and labeled with real time delta from simulated earthquakes.
How we built it
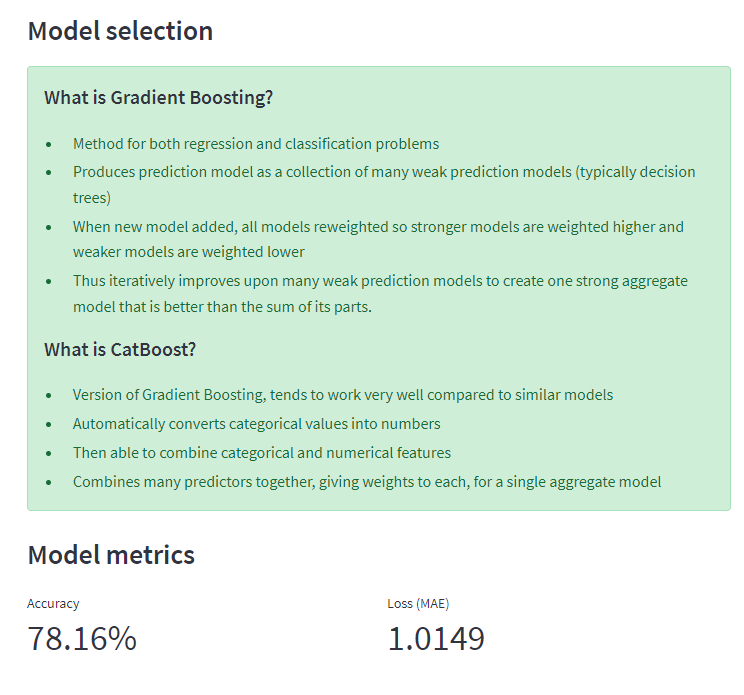
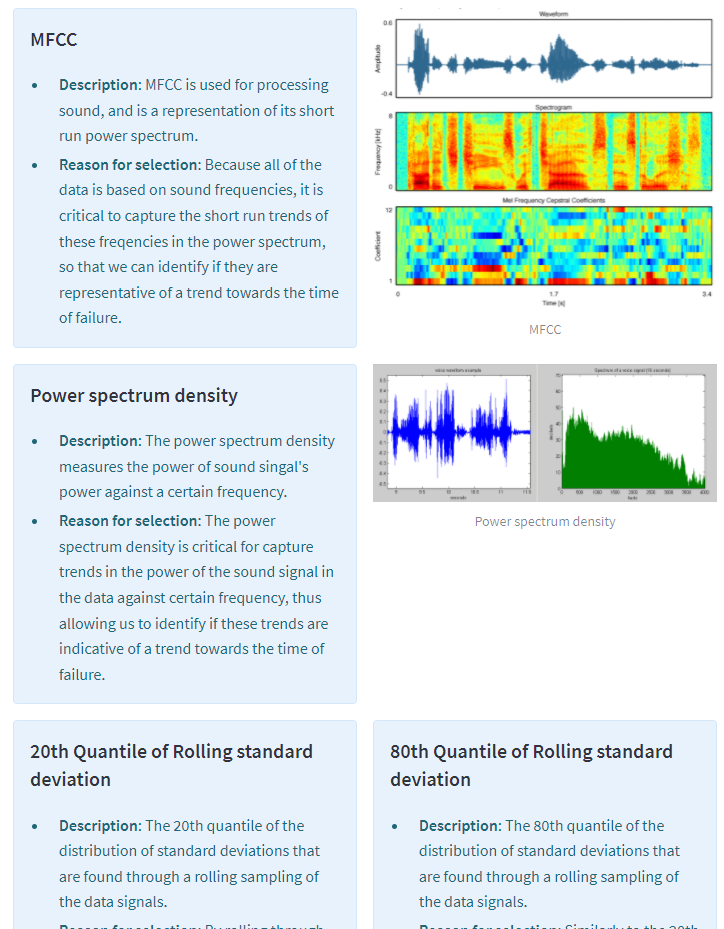
The Catboost imported library was very useful in encapsulating the regression model framework and letting us train and predict at a high abstraction. The features selecting model was also provided by Catboost. Numpy and many other data-focused libraries were used to engineer the features that were being determined from the subsets of raw acoustic data signals.
The website was developed with the opensource framework called Streamlit, which is used to create data-science app very seamlessly using python code.
Challenges we ran into
Some of the features that we have researched and deemed as important for model training were very difficult to learn. After learning, we had to also implement them in python through the limited amount of libraries that are available for the field of signal processing.
The dataset that was used for training was extremely large (in the order of gigabytes), so repeatedly training and testing the model was very time consuming. By the end of development, we came up with ideas to better the model but did not have the time to repeatedly reload the dataset and retrain the model.
Accomplishments that we're proud of
We are really proud that we not only able to create a reasonably accurate predictive model within the time frame, but also a web page to go along with it. We are also really proud of the amount of research and testing we had to do to not only learn about each of the features we wanted to implement in our model, but also implement them in code.
What we learned
We learned a lot about data analysis and statistical inference in this process, the features engineering portion involved a lot of research about sample parameters, data distributions, and signal processing statistics. Machine learning is a very esoteric field and it was fun for all of us to learn even more about the type of models that we used in development, and on the model choices that need to be made such as loss functions.
What's next for Earthquake Prédicteur
The next steps would include refining the model further to increase its overall accuracy. In addition, we could experiment with other types of predictive models as opposed to just gradient boosting.
Built With
- big-query
- catboost
- datastudio
- jupyter-notebook
- python
- streamlit


")
Log in or sign up for Devpost to join the conversation.