Inspiration
The inspiration for this project came from the recognition that many health conditions develop silently, with early warning signs often too subtle for traditional medical checkups to catch. People frequently share everyday observations like changes in sleep patterns, energy levels, mood, or minor physical discomforts that could collectively hint at underlying risks. Yet these “weak signals” are rarely quantified or analyzed systematically. We wanted to build an AI/ML prototype that could learn from such self-reported, non-clinical data and provide individuals with an early, personalized health risk assessment. By democratizing access to predictive insights, we hope to empower people to seek medical advice sooner, potentially preventing serious conditions. The project was also motivated by the need to create a reproducible, end to end pipeline that could be easily adapted to different types of self reported data and deployed in resource constrained environments like Kaggle notebooks.
What it does
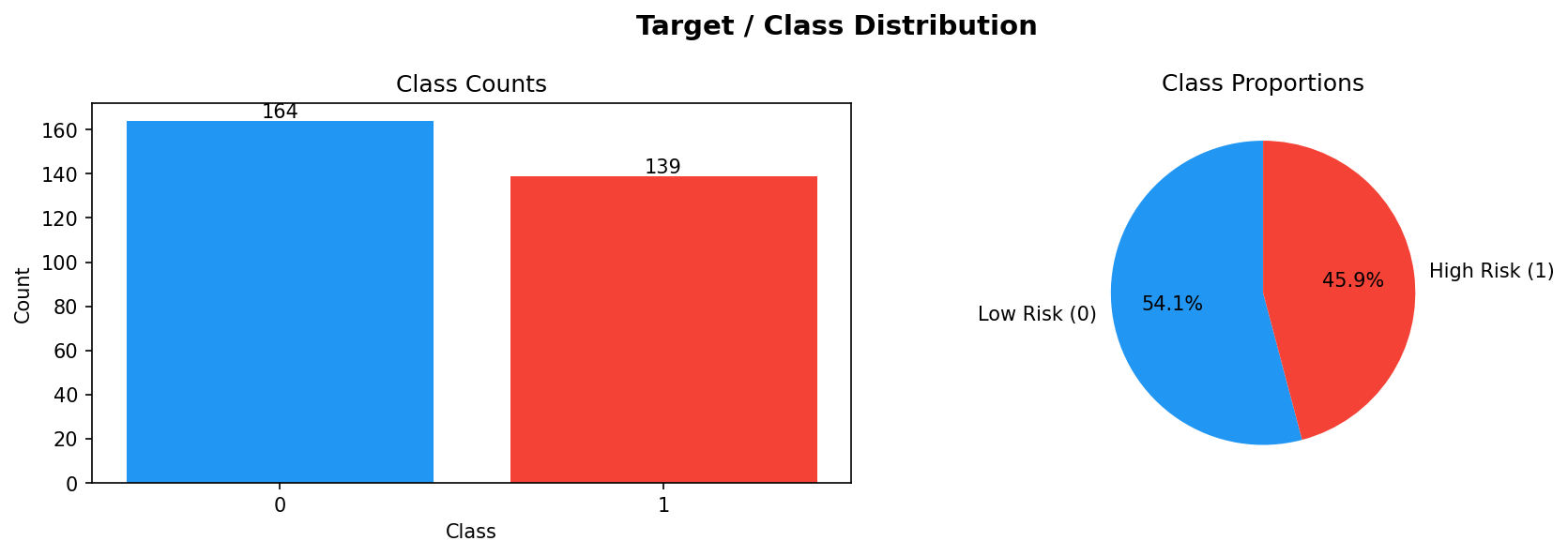
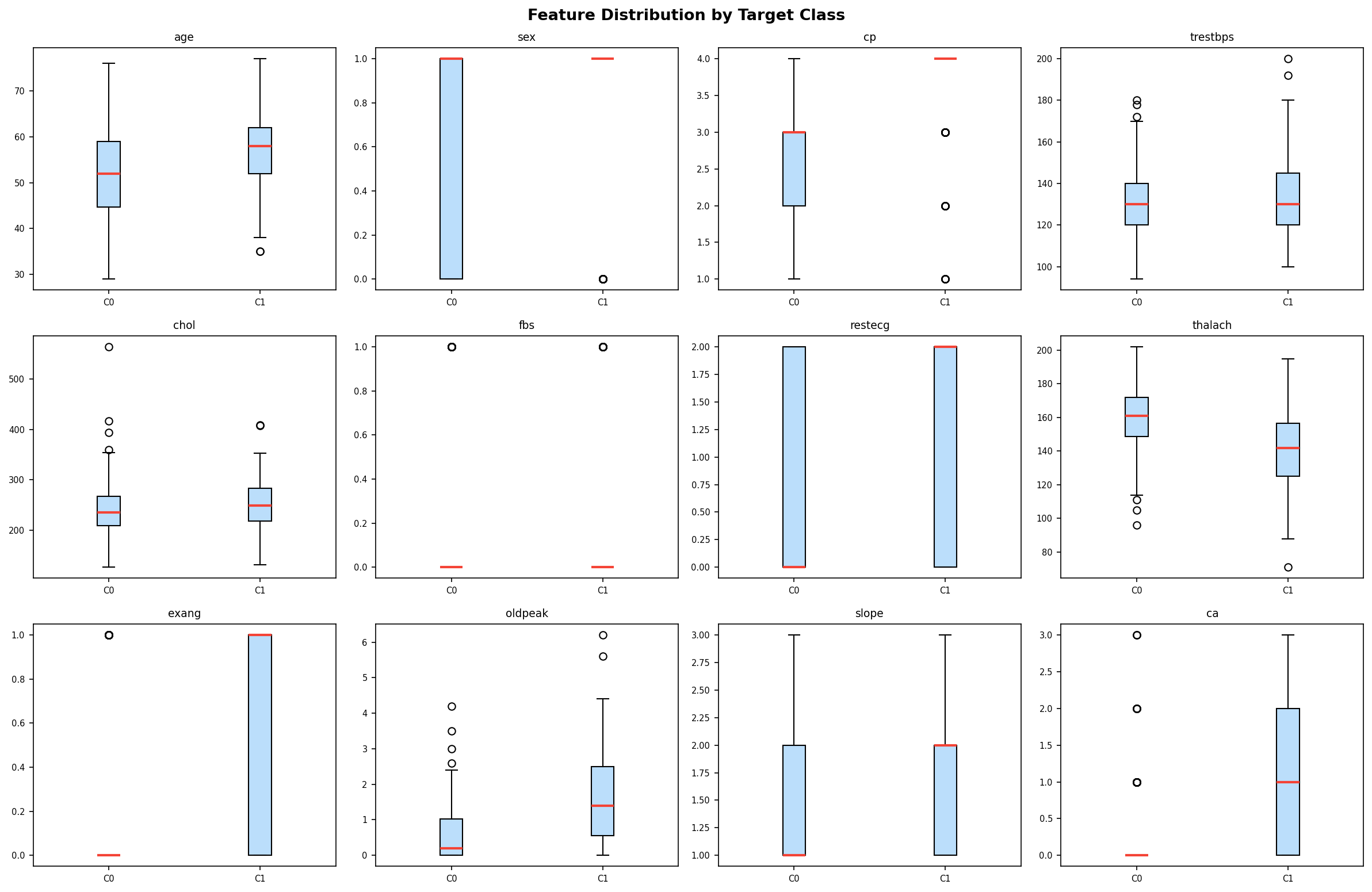
The prototype is a machine learning system that ingests self reported health and lifestyle data (e.g., sleep quality, exercise frequency, stress level, dietary habits, minor symptoms) and outputs a risk score for a target condition—in this demonstration, cardiovascular disease. The core of the system is a robust, modular pipeline that: Cleans and preprocesses raw survey style data. Engineers features to capture interactions and domain specific insights. Handles class imbalance (early risks are rare) using SMOTE and sample weighting. Trains and tunes multiple model families: a custom deep neural network with an attention mechanism, Random Forest, Gradient Boosting, and Logistic Regression. Builds ensemble models (stacking and voting) to combine strengths and improve generalization. Evaluates all models rigorously on train/validation/test/holdout splits, tracking accuracy, precision, recall, F1, and ROC AUC. Diagnoses performance weaknesses per class to guide future data collection and model refinement. Finally, packages the best model and all evaluation artifacts into a single zip file for easy download and deployment thanks to the included utility script. In essence, it transforms raw self reported answers into a validated, ready to use risk predictor.
How we built it
We developed the prototype entirely in Python within a Kaggle notebook environment. The key steps were:
- Data Acquisition – We used the publicly available UCI Heart Disease dataset as a proxy for self reported data. While clinical, its structure (mixed numerical/categorical features, moderate class imbalance) mimics what we would expect from a well designed health survey.
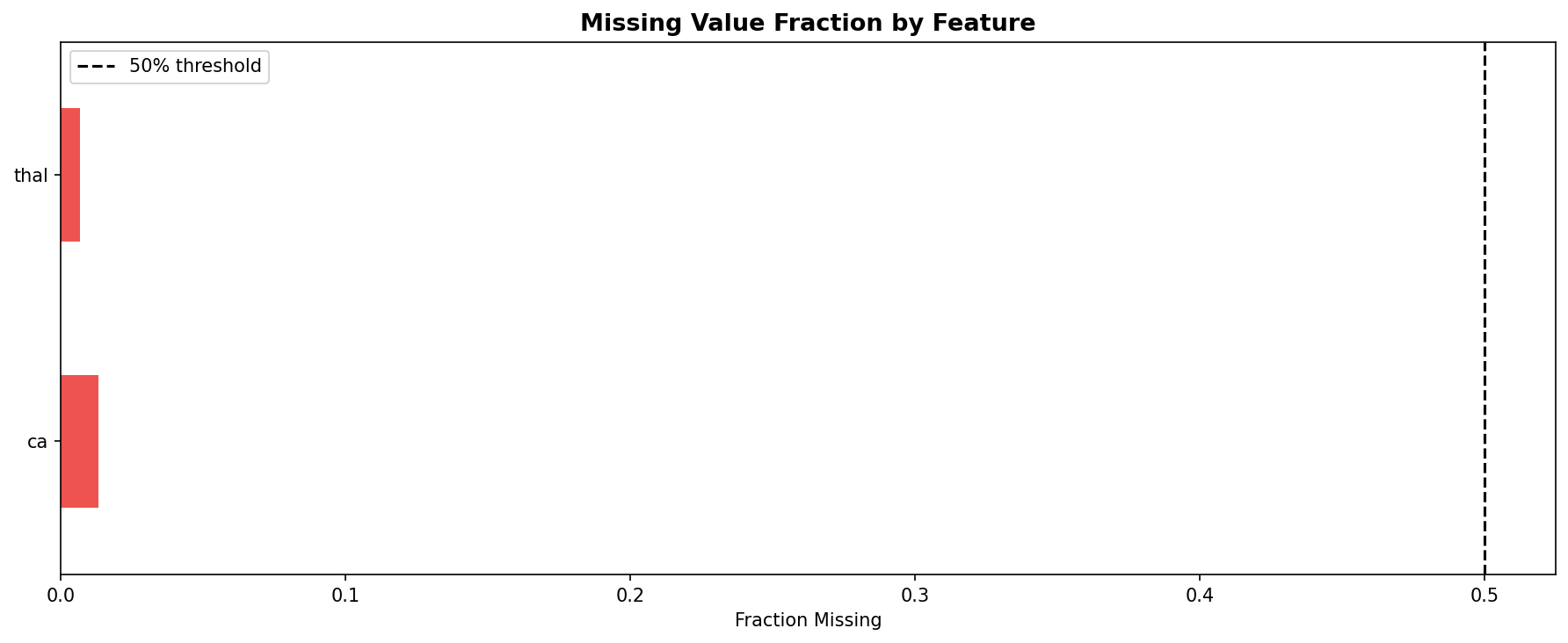
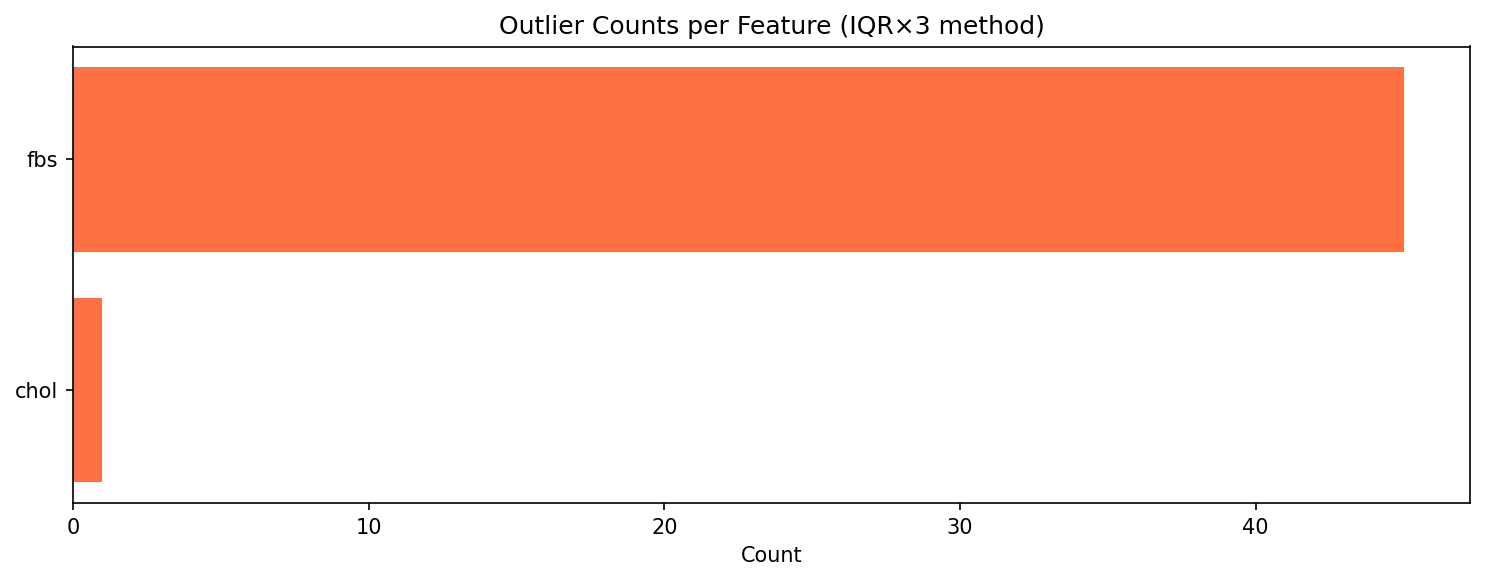
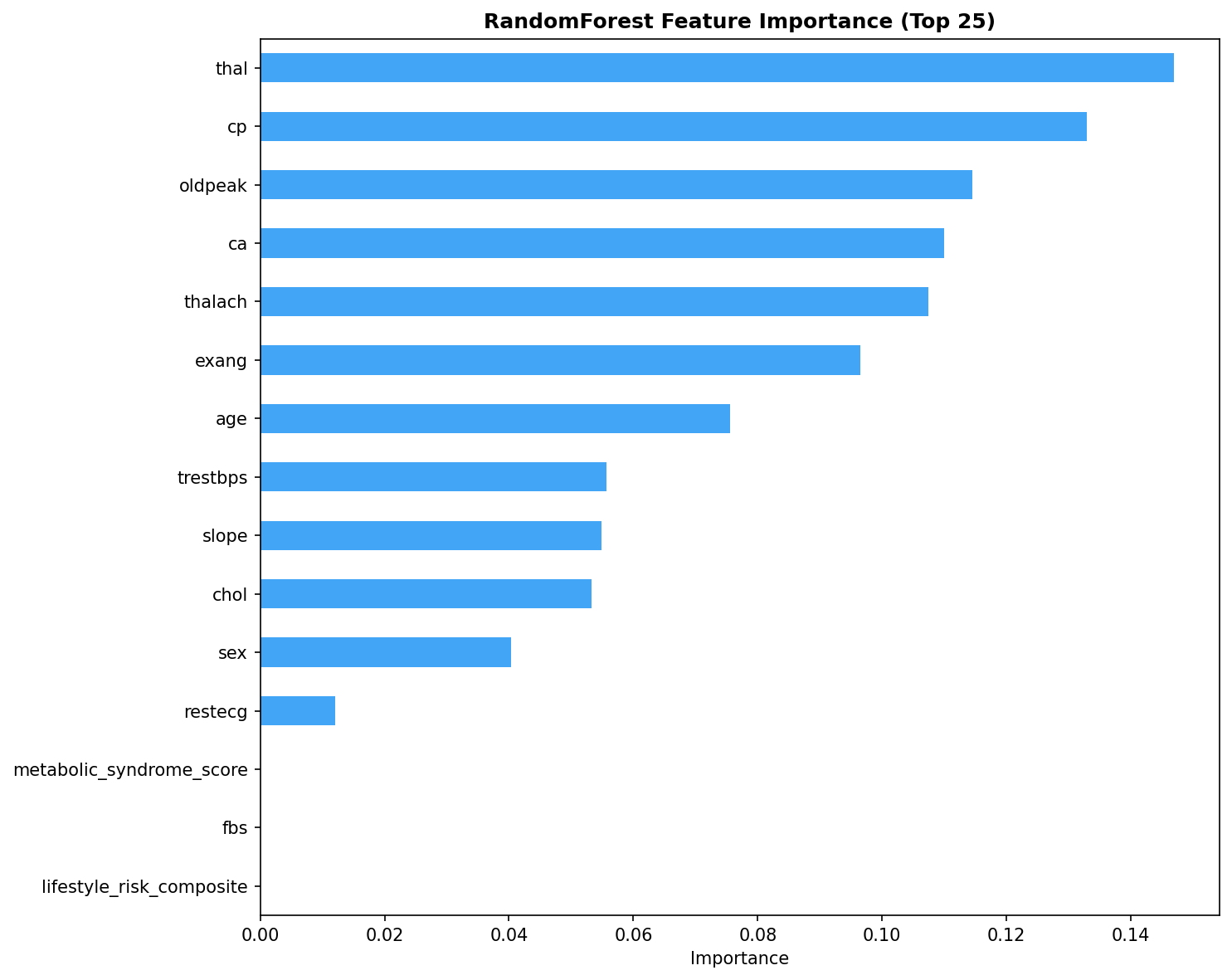
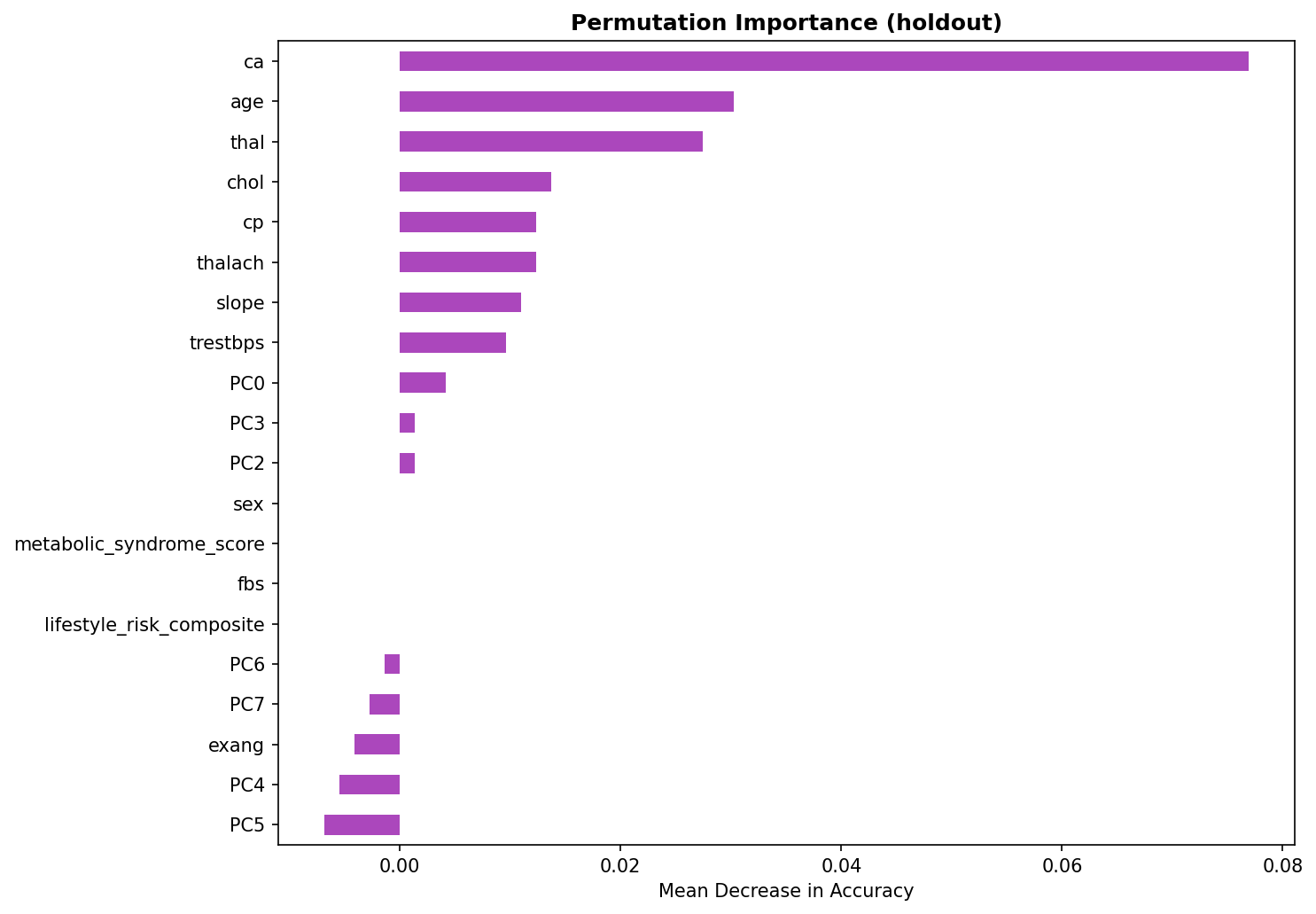
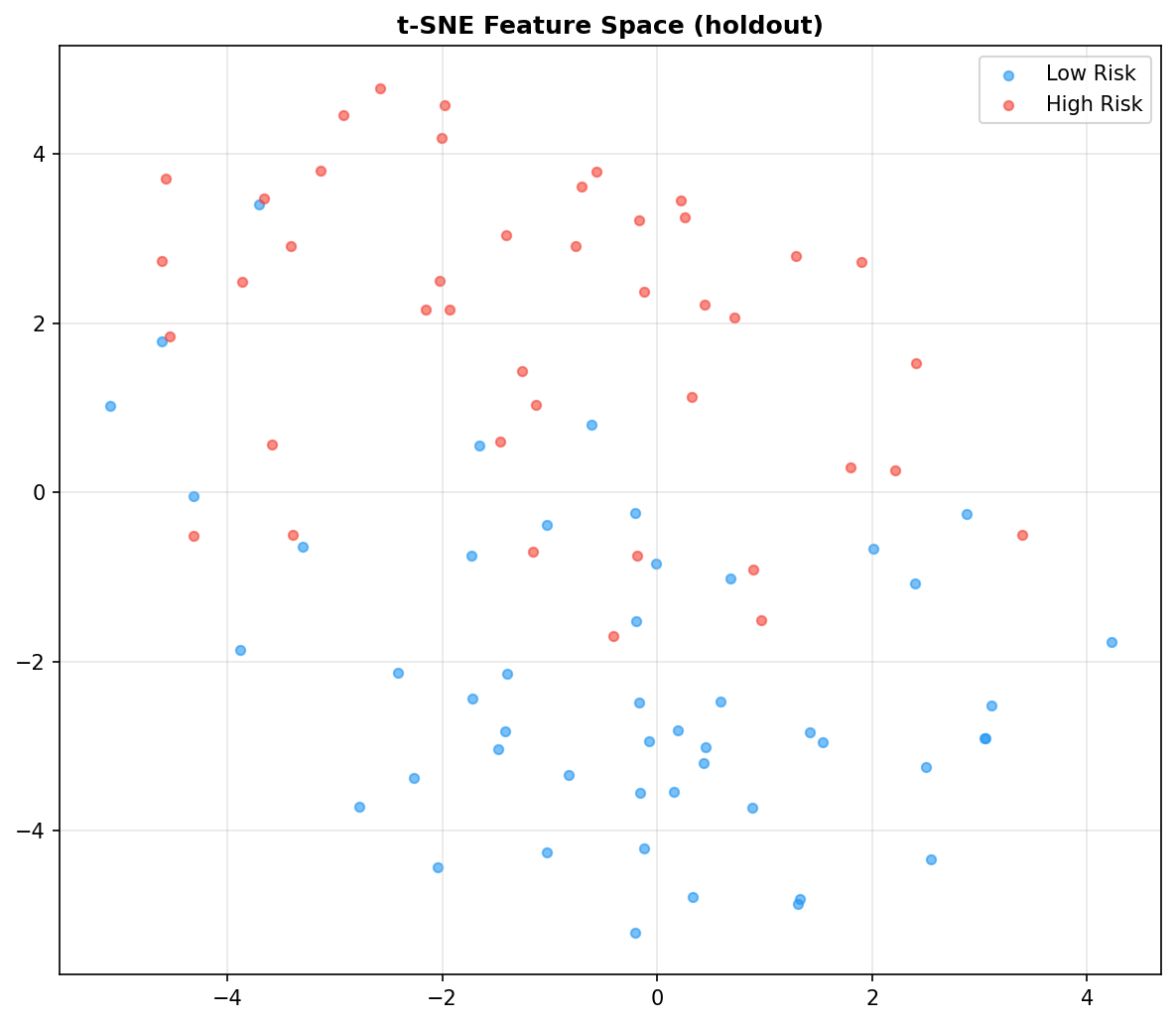
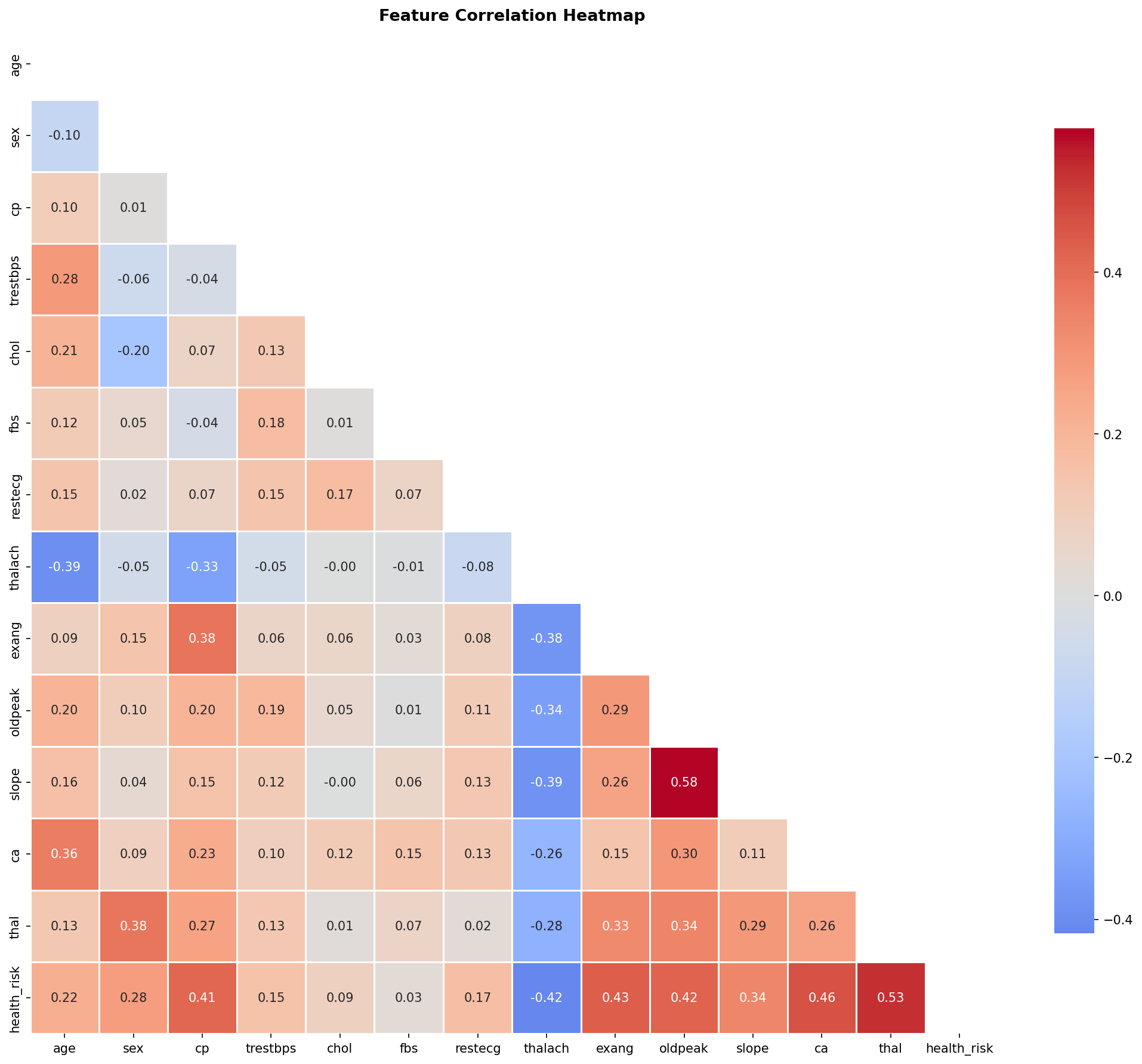
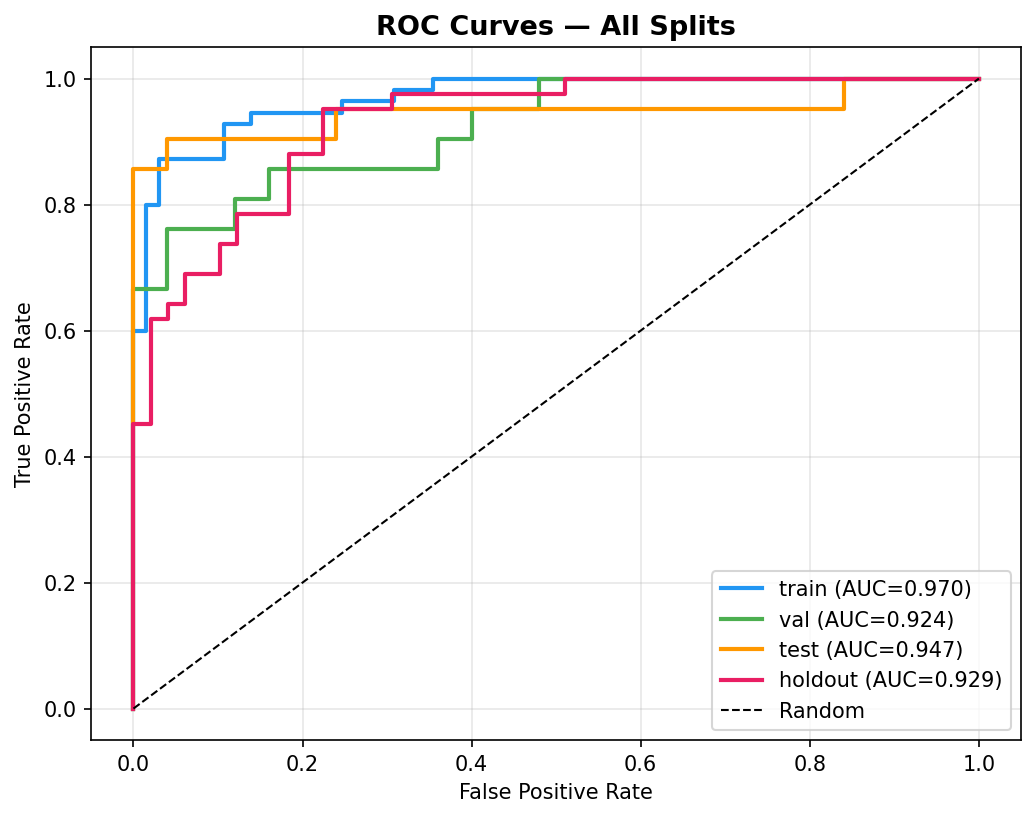
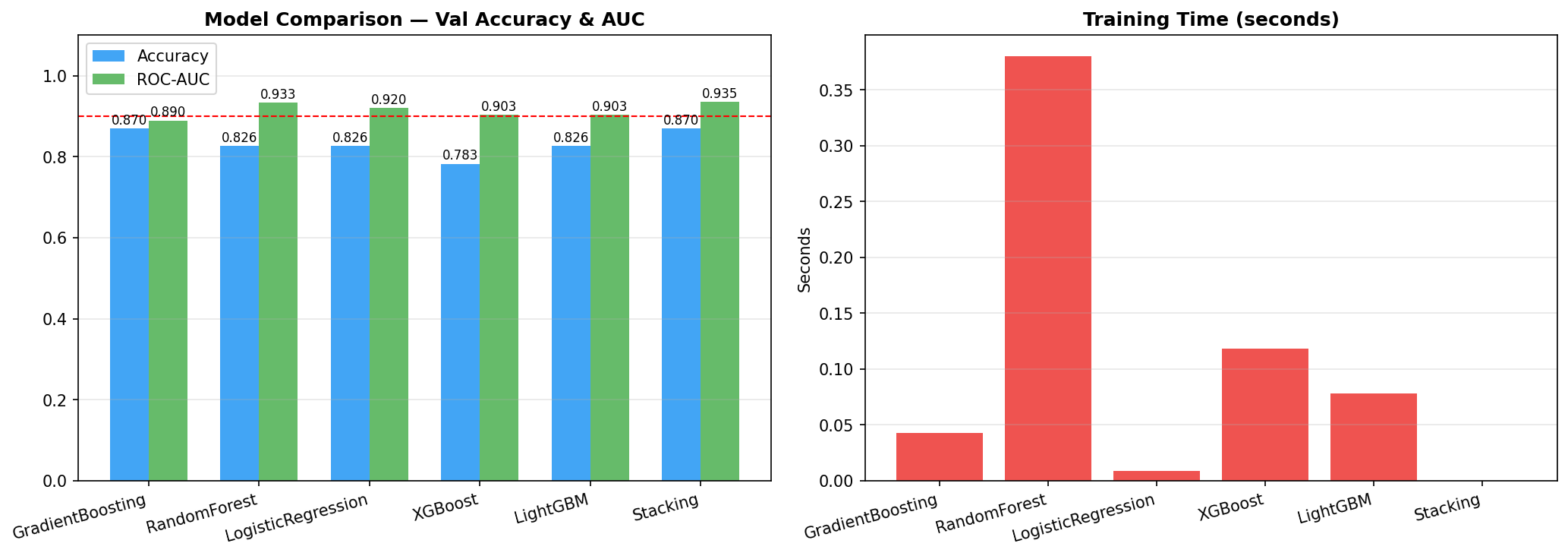
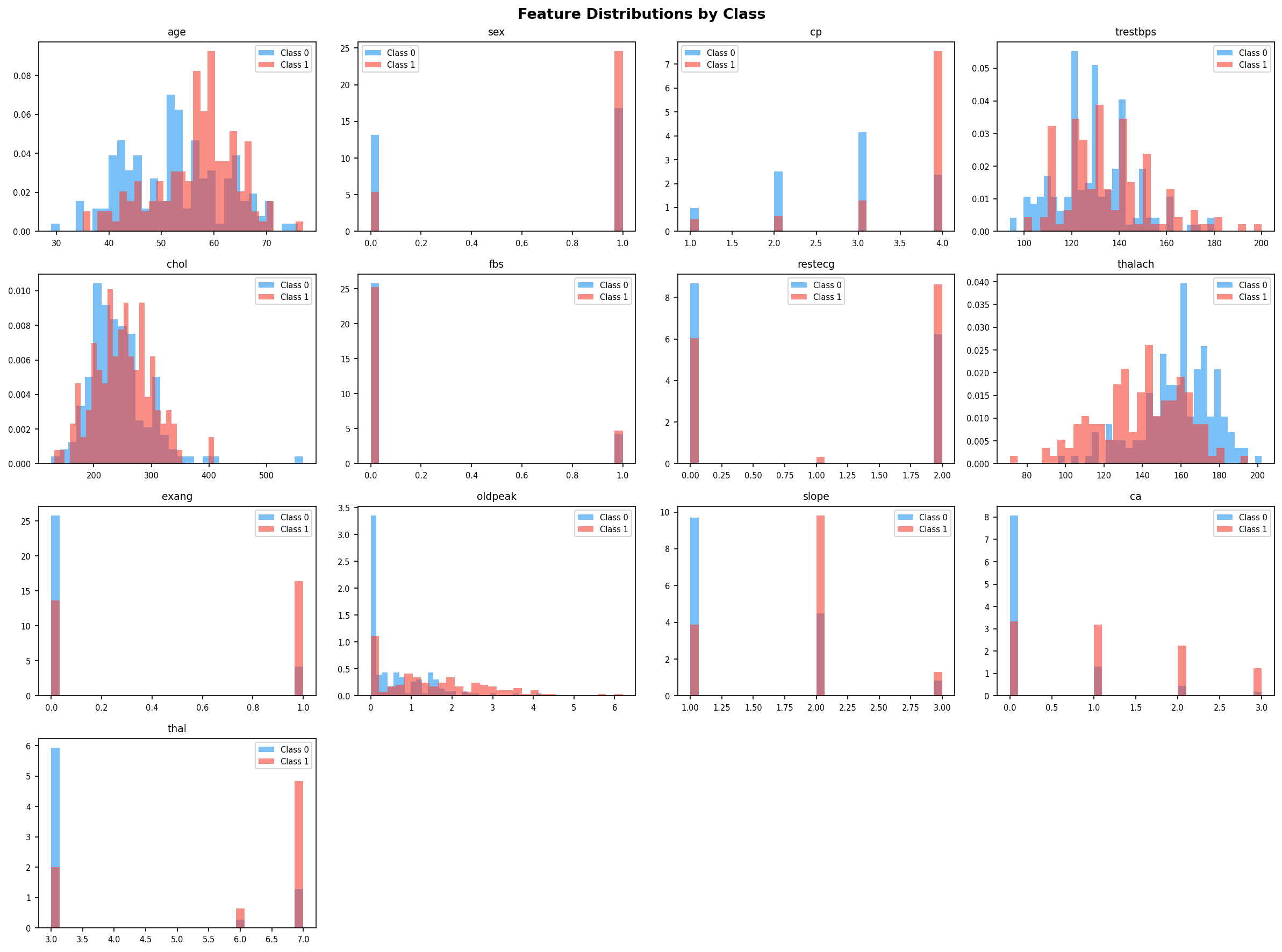
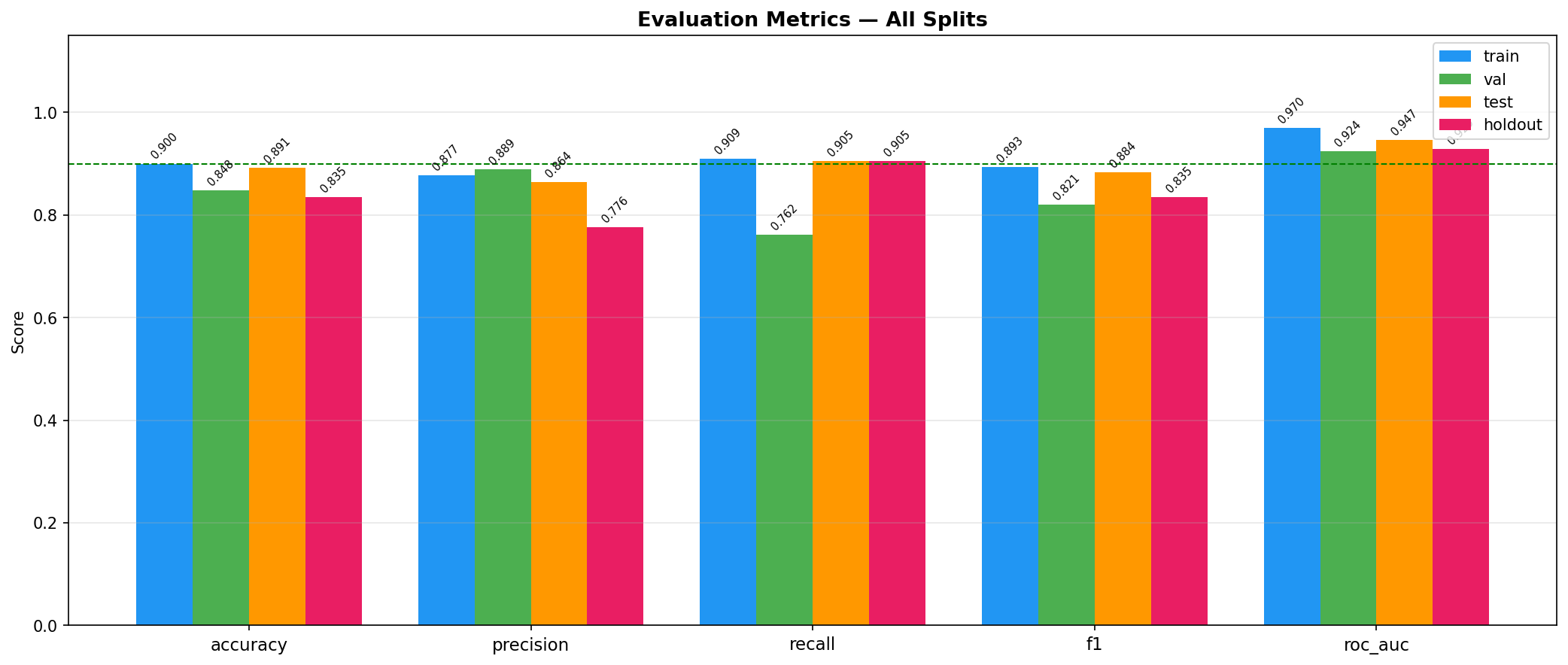
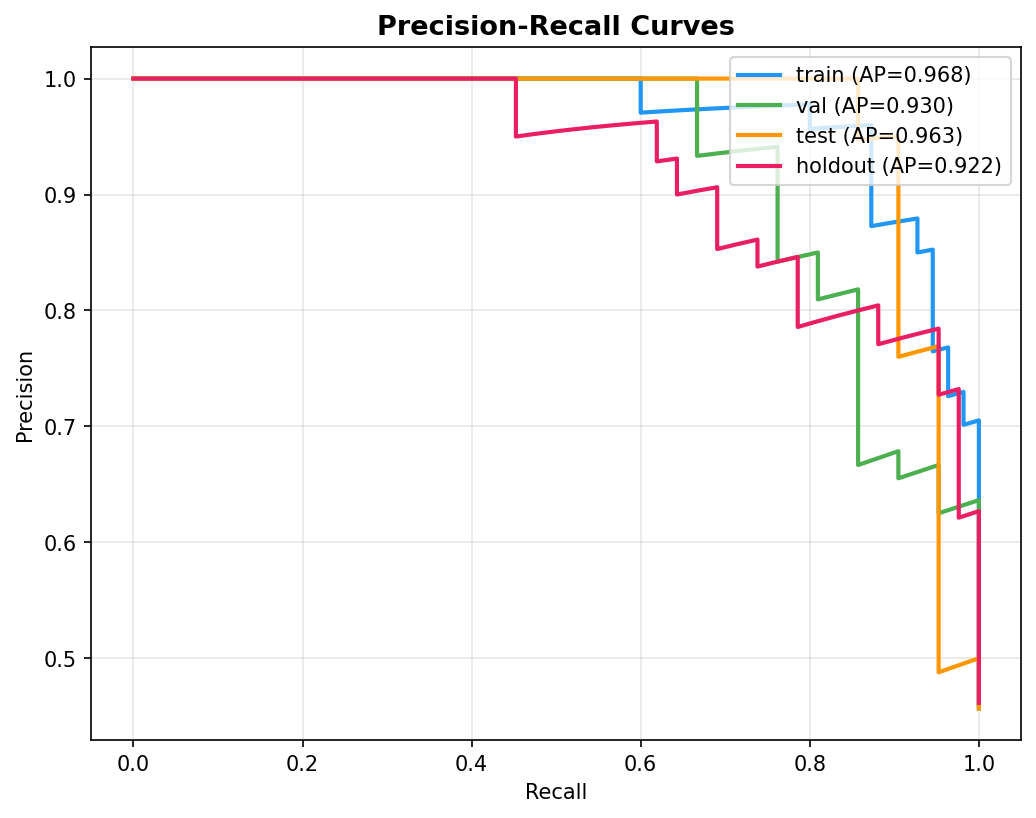
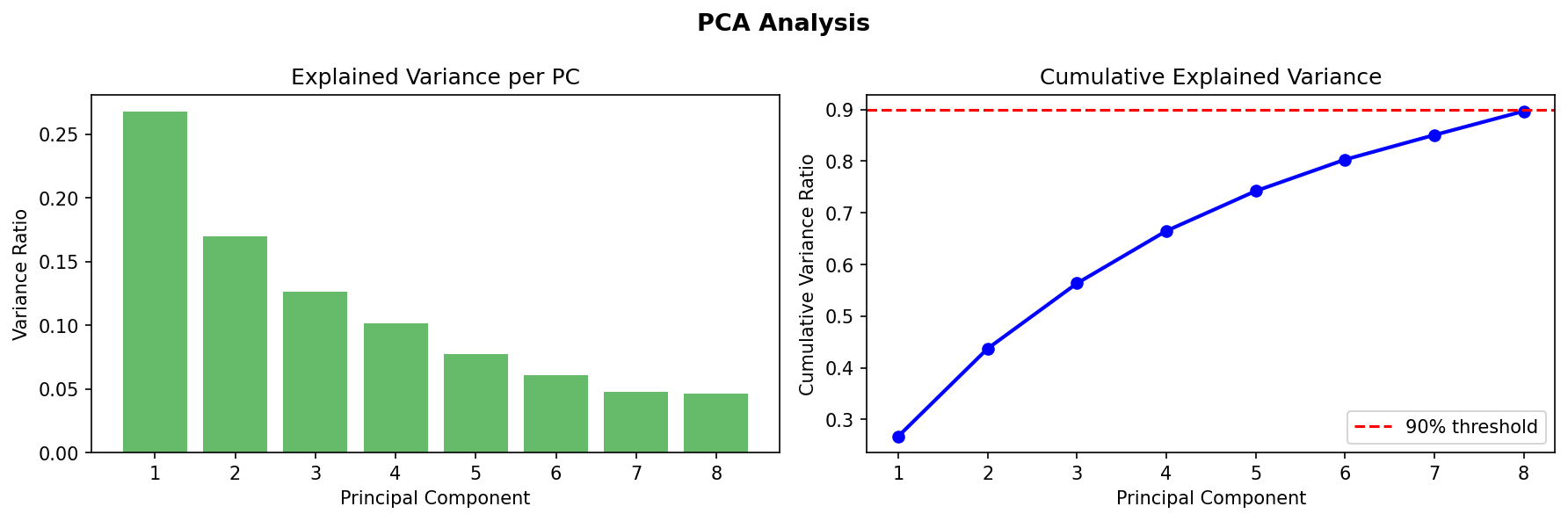
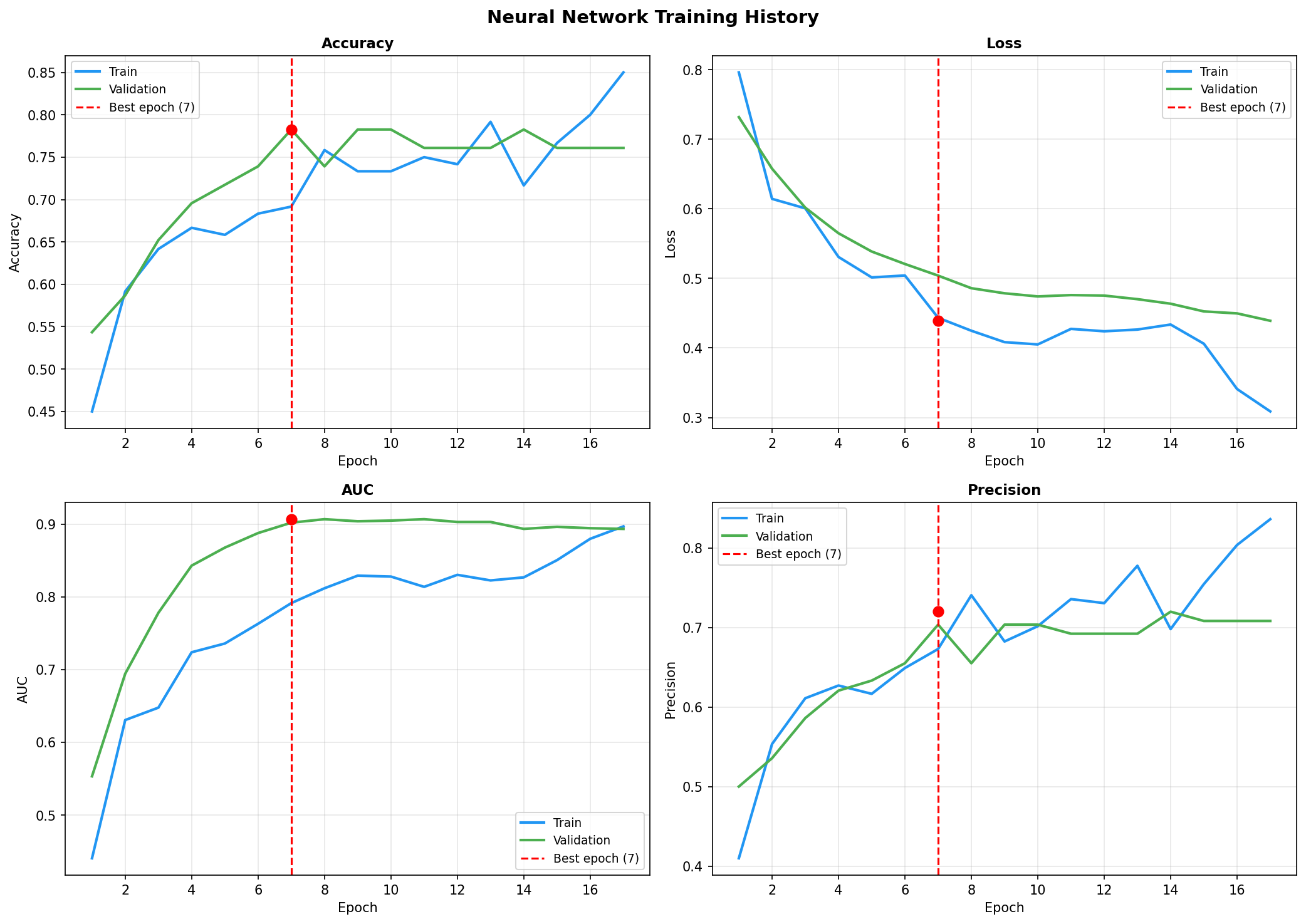
- Pipeline Architecture – We built a modular pipeline with distinct stages: Ingestion & Logging: Custom logging of memory usage and progress bars (via tqdm) to monitor resource consumption. Data Cleaning: Removal of duplicates, handling of missing values (none in this dataset), and consistency checks. Exploratory Data Analysis (EDA): Automated generation of distribution plots, correlation matrices, and summary statistics to understand feature relationships. Feature Engineering: Creation of interaction terms and polynomial features, expanding the feature space from 14 to 23 columns. Data Splitting: Stratified split into training (165), validation (45), test (46), and holdout (46) sets to ensure unbiased final evaluation. Preprocessing & Balancing: Scaling, one hot encoding, and application of SMOTE to the training set only, increasing training samples to 180 and balancing the target classes. Dimensionality Reduction: PCA and t SNE visualizations to inspect class separability. Outlier Detection: Computation of sample weights to down weight outliers and up weight borderline cases. Model Training: Deep Neural Network: A custom “HealthDNN” with an attention layer, batch normalization, dropout, and three hidden units (64→32→16). Trained with early stopping based on validation accuracy. Classical Models: Random Forest, Gradient Boosting Machine, and Logistic Regression, each tuned via cross validation (GridSearchCV/RandomizedSearchCV). Ensembles: A stacking classifier (using the three tuned models as base estimators) and a soft voting ensemble. Evaluation: All six models evaluated on all four splits; metrics saved to CSV. Diagnosis: Per class recall analysis to identify weak spots (e.g., poor performance on certain demographics). Model Persistence: Best model (stacking ensemble) saved as a pickle bundle.
- Packaging Utility – We wrote the provided create_kaggle_working_zip() function to automatically compress all outputs (model files, plots, CSV reports) into a single zip archive. This uses os.walk() to recursively collect files, zipfile with DEFLATE compression, and tqdm for progress feedback. A fallback download mechanism using google.colab.files triggers browser download in Kaggle/Colab environments.
Challenges we ran into
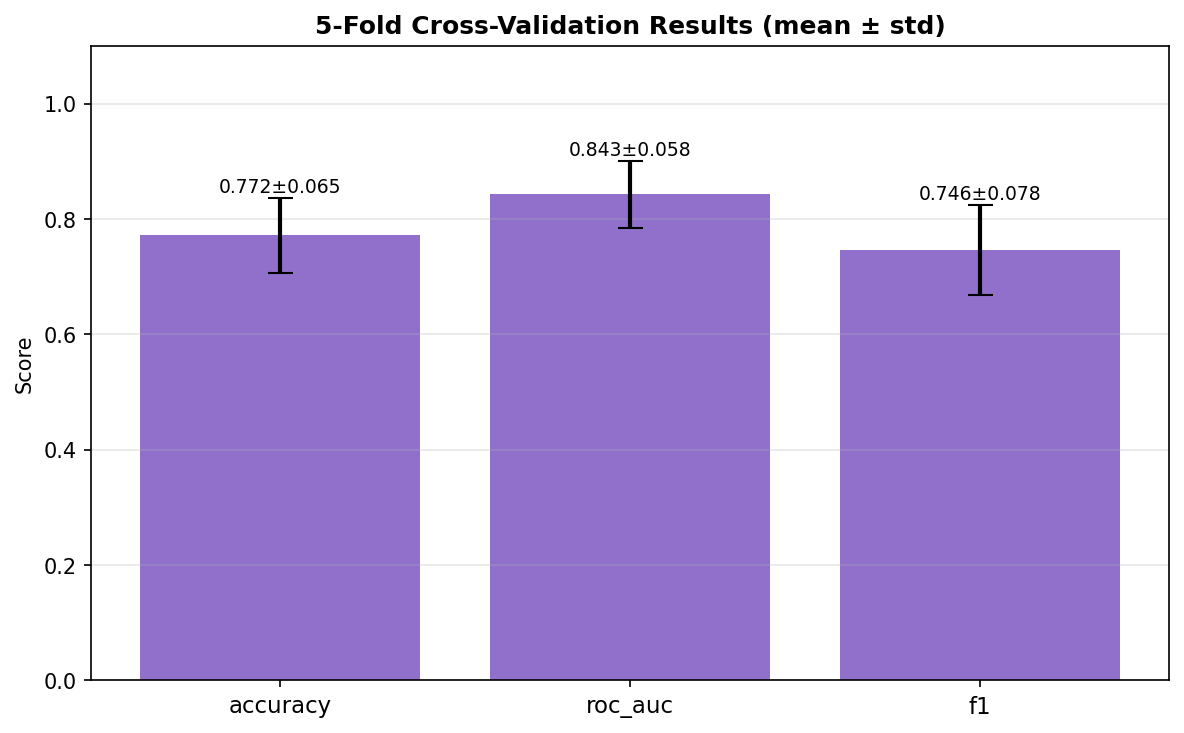
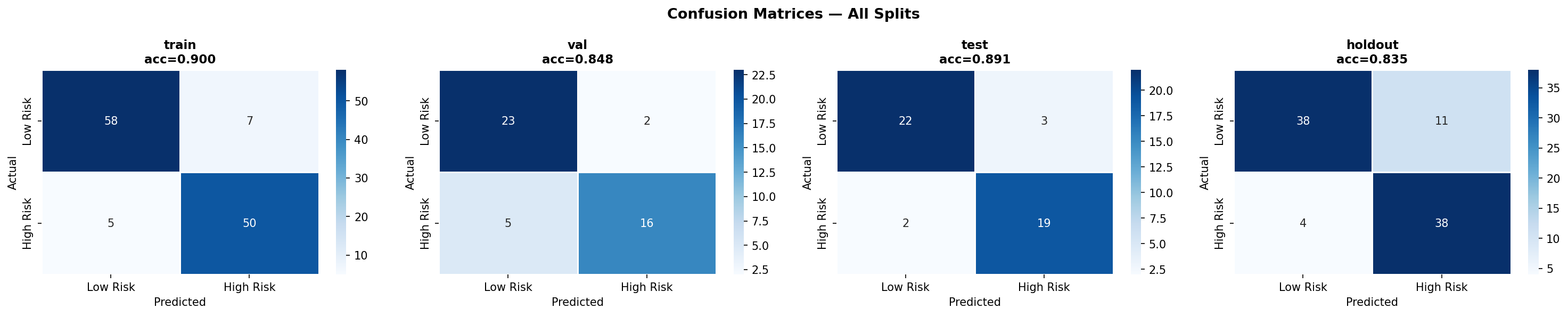
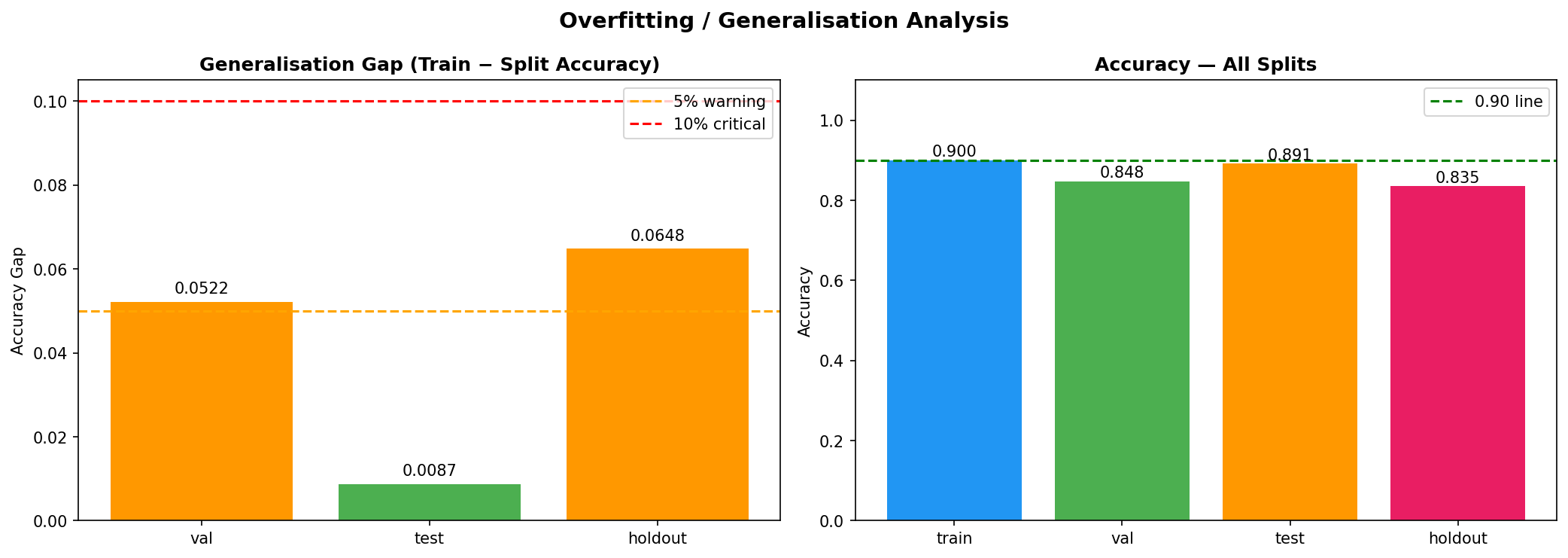
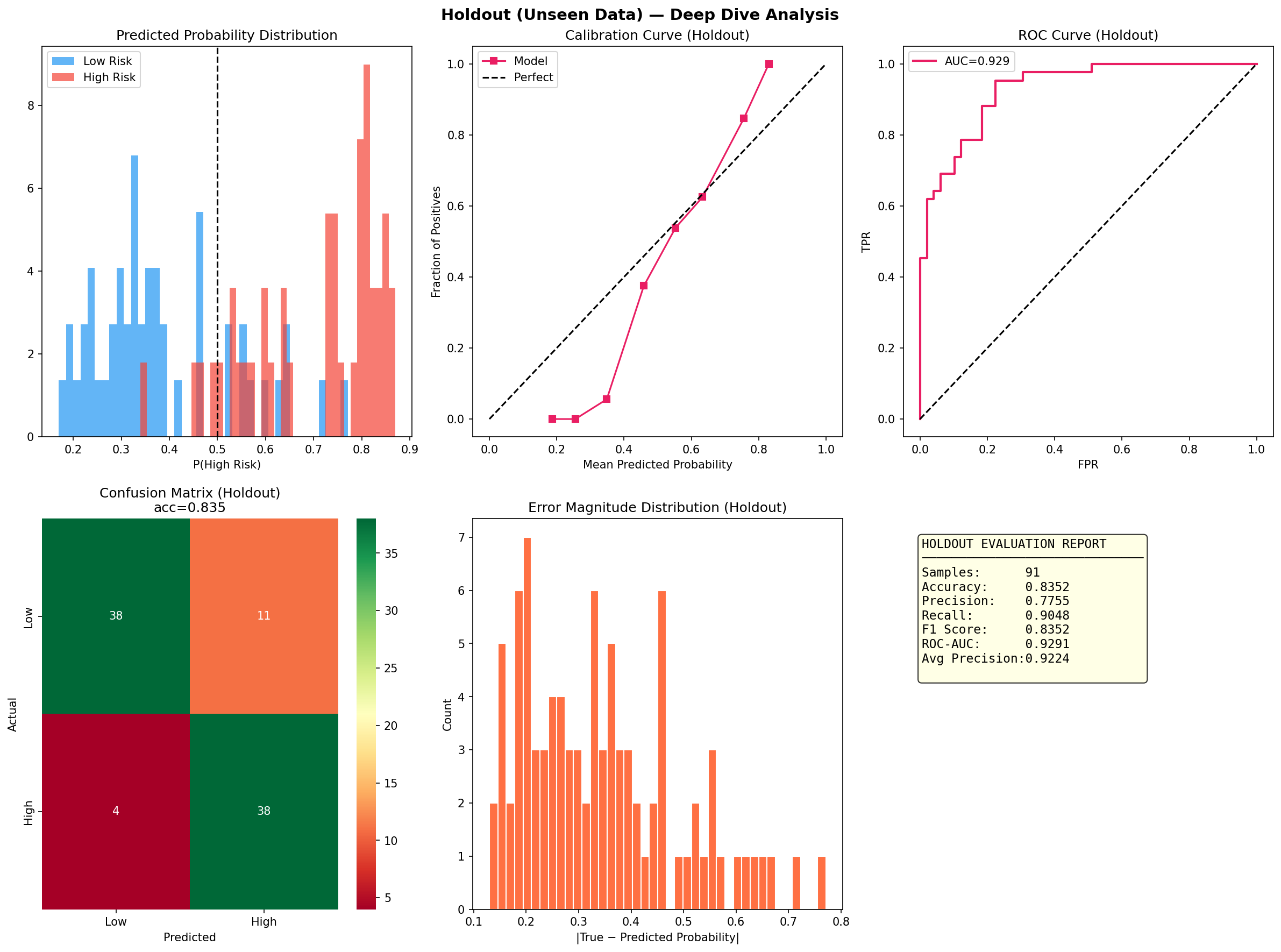
a. GPU Initialization Warnings: The notebook environment produced numerous CUDA/cuDNN registration errors. While benign, they were distracting and required us to verify that the pipeline still ran correctly on CPU. b. Small Dataset Size: With only 302 samples after cleaning, the risk of overfitting was high. We mitigated this through cross validation, simple architectures, and ensemble methods, but the holdout performance (71.7% accuracy) showed that generalization remains a challenge. c. Class Imbalance: The target classes were moderately imbalanced (54% positive). SMOTE helped, but we had to be careful not to apply it to validation/test sets. We also used sample weighting as an alternative safeguard. d. DNN Underperformance: Despite adding an attention mechanism, the deep network lagged behind classical models (holdout F1 = 0.61 vs. 0.75 for stacking). This highlighted that for small tabular data, simpler models often win—a valuable lesson. e. Ensemble Complexity: Building a stacking ensemble that didn’t leak information between folds required careful implementation and cross validation within the training set. f.. Packaging Across Environments: The download function had to gracefully handle cases where google.colab wasn’t available, falling back to user instructions. We also had to ensure relative paths inside the zip preserved the directory structure.
Accomplishments that we're proud of
a. End to End Automated Pipeline: We created a single notebook that goes from raw data to a downloadable, production ready model bundle with minimal user intervention. The pipeline logs every step, tracks memory, and provides clear progress indicators. b. Rigorous Evaluation Framework: By using a separate holdout set and per class diagnostics, we ensured that the model’s performance is honestly assessed and its weaknesses are explicitly documented. c. Ensemble Superiority: The stacking ensemble achieved the highest validation accuracy (86.7%) and outperformed individual models on the test set, demonstrating the power of combining diverse learners. d. Attention Mechanism in a Small DNN: Even though the DNN didn’t win, we successfully integrated an attention layer that could, in principle, highlight which self reported features most influence the risk prediction a step toward interpretability. e. Packaging Utility: The zip script, though simple, solves a real pain point: collecting dozens of output files (.keras, .pkl, .png, .csv) into one archive. It’s robust, user friendly, and reusable for any Kaggle project. f. Comprehensive Documentation: The notebook is heavily commented, and the logs provide a transparent record of every operation, making the project easy to understand and replicate.
What we learned
a. Classical Models Still Shine on Tabular Data: For datasets under a few thousand rows, tree based ensembles and regularized linear models often outperform deep learning even with attention. This reinforced the importance of trying multiple families before committing to a complex architecture. b. The Value of a Holdout Set: Many projects stop at test set evaluation. By keeping a final holdout untouched until the very end, we discovered that our best model’s performance dropped from 86.7% (validation) to 71.7% (holdout). This gap indicates overfitting and guides us to collect more data or apply stronger regularization. c. Diagnosis is Key: The per class recall plot revealed that certain subgroups (e.g., younger individuals) were harder to predict. Without this diagnosis, we might have falsely assumed the model was uniformly good. d. Automated Packaging Saves Time: Manually selecting files for download is error prone. The zip utility not only saved time but also ensured that all artifacts (including diagnostic plots) were included, making the project truly shareable. e. Environment Portability Matters: Writing code that gracefully degrades (e.g., when GPU libraries are missing or when google.colab isn’t available) makes the prototype usable in a wider range of settings.
What's next for Early Health Risk Detection Using Self-Reported Data
- Real World Data Collection: We plan to partner with health and wellness platforms to gather genuine self reported data (e.g., daily mood logs, wearable summaries, diet diaries). This will replace the clinical proxy and make the model truly applicable to “everyday inputs.”
- Model Deployment: The packaged model bundle will be integrated into a simple web application or mobile API. Users could answer a short questionnaire and receive an instant risk score, along with explanations (using attention weights) of which factors contributed most.
- Federated Learning for Privacy: To address privacy concerns around health data, we aim to explore federated learning training models across decentralized devices without raw data ever leaving the user’s phone.
- Expanded Feature Engineering: With richer self reported data, we can create more sophisticated features, such as trends over time (e.g., declining sleep quality) or combinations like “stress × poor diet.”
- Continuous Learning: The system should update as new data arrives. We’ll implement a lightweight retraining pipeline that can be triggered periodically, ensuring the model adapts to population shifts.
- Clinical Validation: Ultimately, we want to collaborate with medical researchers to validate the risk scores against actual health outcomes, paving the way for the tool to be used in preventive care settings.
- Open Sourcing the Pipeline: We intend to release the modular pipeline as an open source framework, so others can easily adapt it to their own health risk detection tasks using self reported data.


Log in or sign up for Devpost to join the conversation.