-
-
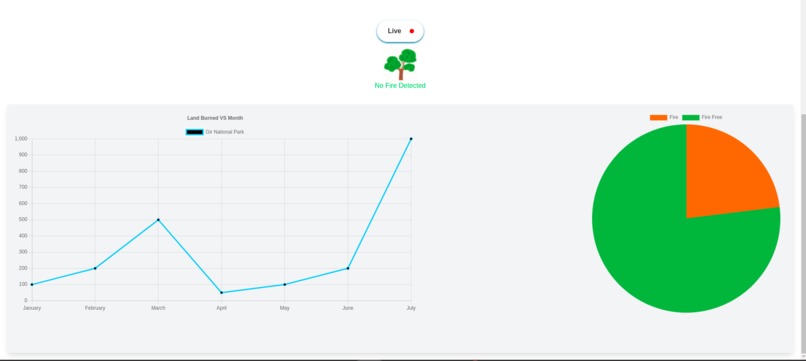
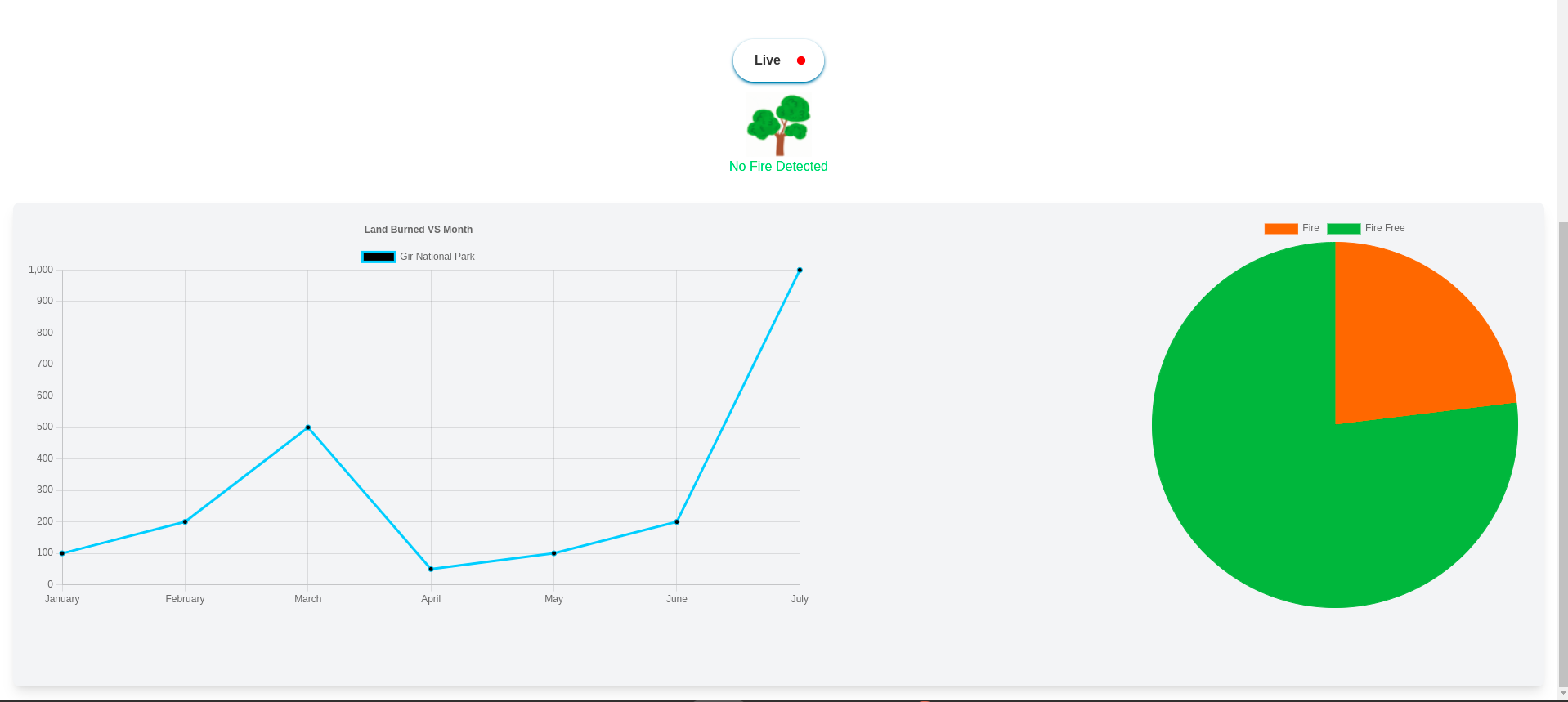
Data showing the area of forest burned and saved from burning.
-
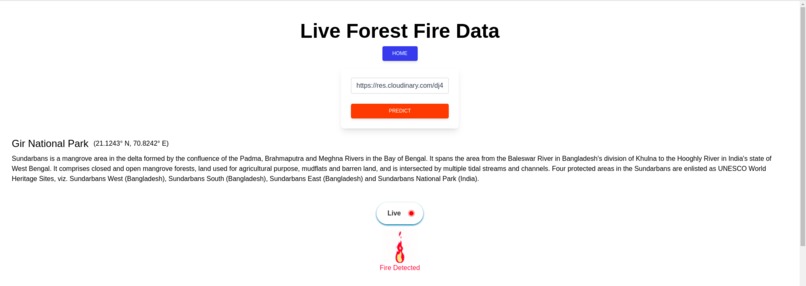
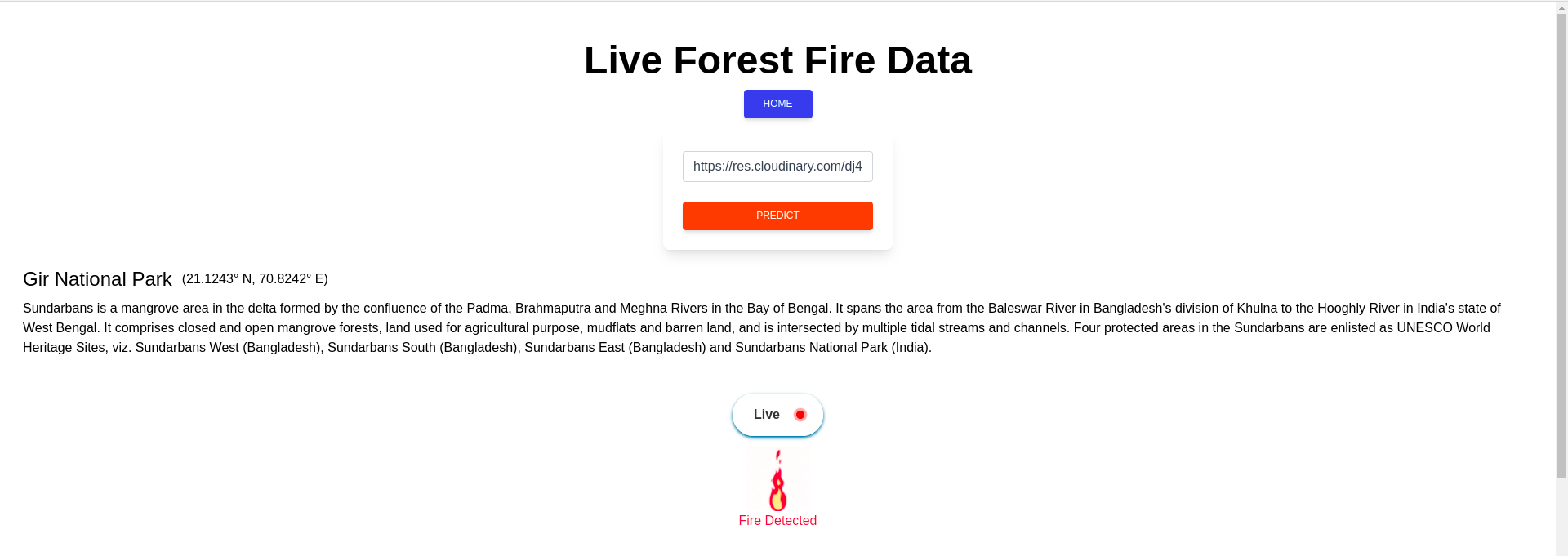
When smoke image is used , it shows the Fire signal on the webpage.
-

When an image from any class other than smoke is used , No Smoke is detected and shown.
-
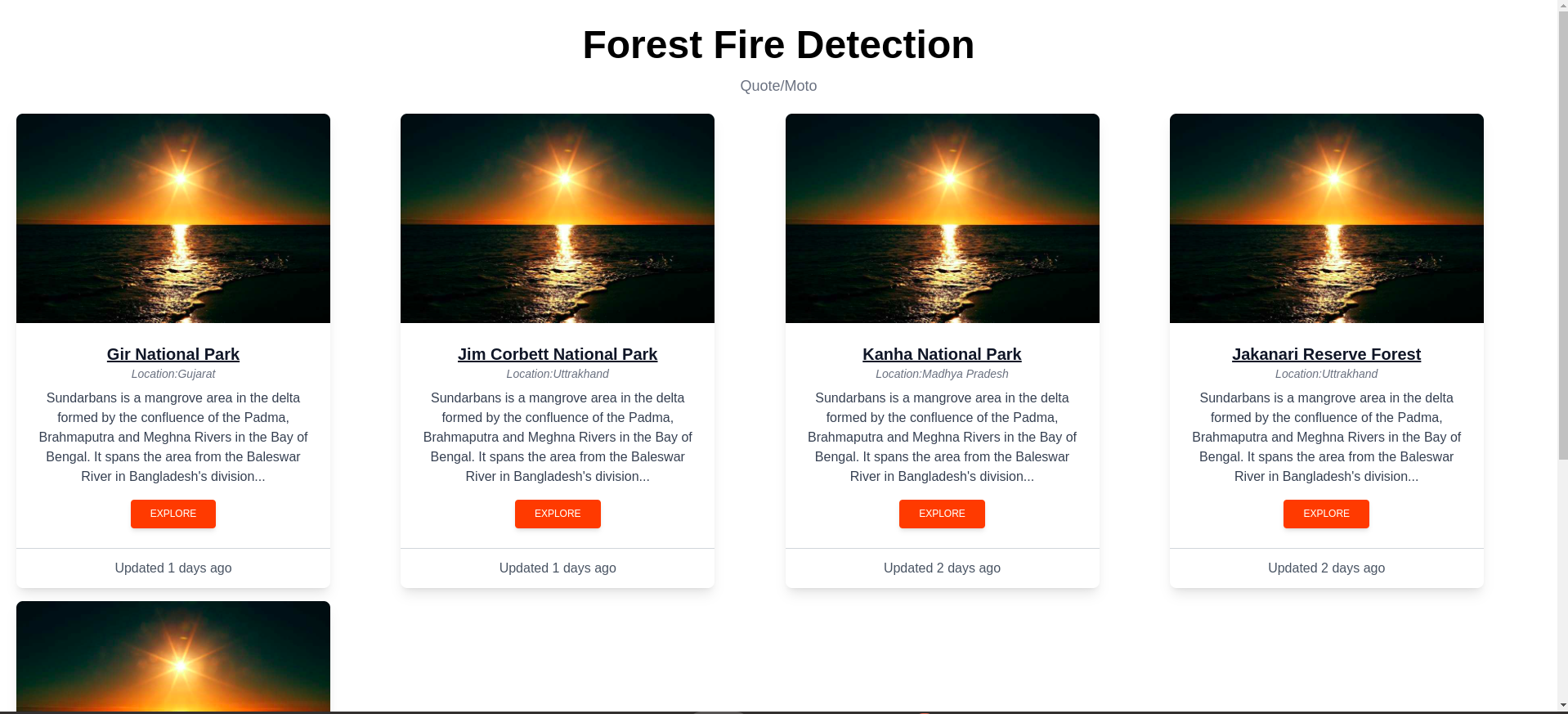
Home page showing all the famous forests in the country.

Inspiration For Us
Forest fires, wildfires and bushfires are serious environmental problems that cause many health-related issues. Forest fires are responsible for massive global damage every year. In spite of being classified as a “natural phenomenon” by the International Union for Conservation of Nature (IUCN) Report “Global Review of Forest Fire 2000”, 90% of wildfires are caused by human activity. Wildfires lead to significant forest loss (6–14 million hectares of forest per annum) and contribute to 30% of atmospheric CO2. This gives rise to massive loss of life, global warming, destruction of various environmental and essential resources. “In India 37,059 fires were detected in year 2018 using MODIS sensor data”. Precious resources from forests including carbon locked in the biomass is lost due to forest fires every year. The most effective way to prevent a large-scale forest fire is to detect it at an early stage through smoke, since smoke is the first sign of a wild spreading fire. And thus our idea is based on the concept of detecting smoke through satellites images.
What it does
Our project takes image provided from a sun-synchronous satellite of a specific location and tries to detect the presence of smoke and display the fire signal on the website to alert alert the authorities concerned immediately allowing them to take action before the fire becomes uncontrollable.
How we built it
We divided the building phase into three steps and our main goal was to get a MVP, since its a project which can be improved at every stage and will never be counted as full complete.
Three steps were (not in sequence but parallel execution)->
Setup the environment and train the model using different CNN architectures:
- We had the dataset to start with as we already searched it, the dataset we used is USTC_SmokeRS
- We started with the LeNet-5 architecture, I was already having a template to setup LeNet-5 here the challenge was to preprocess data, after training was complete(it didn't took a long time) the test accuracy we achieved was something around 53%.
- Since above architecture uses grey scale image we were sure that an architecture with colored image would give the better result and we tried AlexNet (it took a long time to get it right) and viola we got an accuracy of about 93% on validation set.
Build Backend API - Our plan was to use the above trained model in a python based framework(Django!!!!!) and make a API that will accept the image in a POST request and will give response as the predicted class.
- Why python based? since we trained model on TensorFlow python library hence it was easier and faster to use same language for setting up API.
Build Frontend - We used react and tailwind UI to quickly build a basic frontend for our project.
- Since when we were building frontend our model and backend wasn't ready it was a challenge to get the frontend right.
Challenges we ran into
There were many challenges in this project, I am highlighting the most frustrating(and most brainstorming) challenges we faced:
Setting up AlexNet
The dataset we used consists of 6225 RGB images from six classes including Cloud, Dust, Haze, Land, Seaside, and Smoke, loading all these images at once in Google Collab was not possible since the available ram is only about 8GB, so we had to find a way of loading images that are currently being used only. After a lot of searching we came across lazy loading and TensorFlow object data preprocessing pipeline, we had to watch many YouTube tutorials and many medium blogs before getting it right, but finally it was done and it felt very rewarding after knowing the accuracy we have achieved.
Using the model
We had the model but now it was a more challenging task to actually use it, we both were not experienced with actually deploying AI model, so we thought of going with the same language so that we can copy paste the code we have used in our model training and will predict using it, we watched some tutorials and blogs about doing it right and finally we had the model inside the Django directory, next task was to setup the API route, it was comparatively easy, finally we had the working API.
Getting the frontend right
Since our model training was taking a long time we had to start with frontend to complete the MVP on time, but since we didn't have any backend so it was a challenge to get everything approximately correct and what we wanted, we were using the imagination of what every click we can do and and how will the result be displayed.
Accomplishments that we're proud of
The accuracy of Validation Data results: loss: 0.3719 Accuracy: 0.9107, Train Data results: loss: 0.3506 Accuracy: 0.8943 achieved on the model, coming up with a informative yet interactive UI for the webpage with a fire signal in a short period of time and last but not least is contributing to such a noble cause at our level is what we are really proud of.
What we learned
All the challenges we faced made us learn a new things .
- Working together as a team overcoming the limitations of each other and divide the work equally between us.
- Working on different tech stacks in order to build a fully functioning project.
- Deeper understanding of how a CNN model works.
- The improvement of accuracy after using colored rgb images instead of gray scaled images.
- Learned about lazy loading of dataset in TensorFlow to overcome the limitation of storage
What's next for Early Forest Fire Detection
- Our MVP detects the presence of a smoke with a satellite image manually fed to it from the API, so next would be to integrate continuous satellite data with it from Google Earth at an interval of 24hours.
- We plan to change the graph plot in the webpage to a dynamic graph which shows the actual data regarding the area of forest burned in the past forest fires and maybe some interesting facts about the forests.
Built With
- api
- deeplearning
- django
- javascript
- python
- react
- tailwind
- tensorflow
- typescript


Log in or sign up for Devpost to join the conversation.