-
-
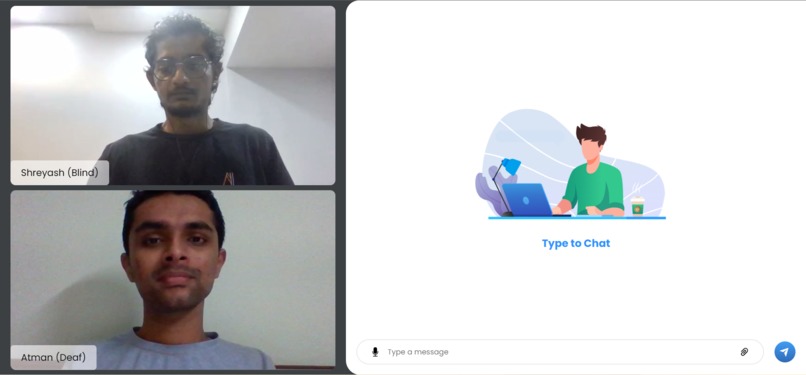
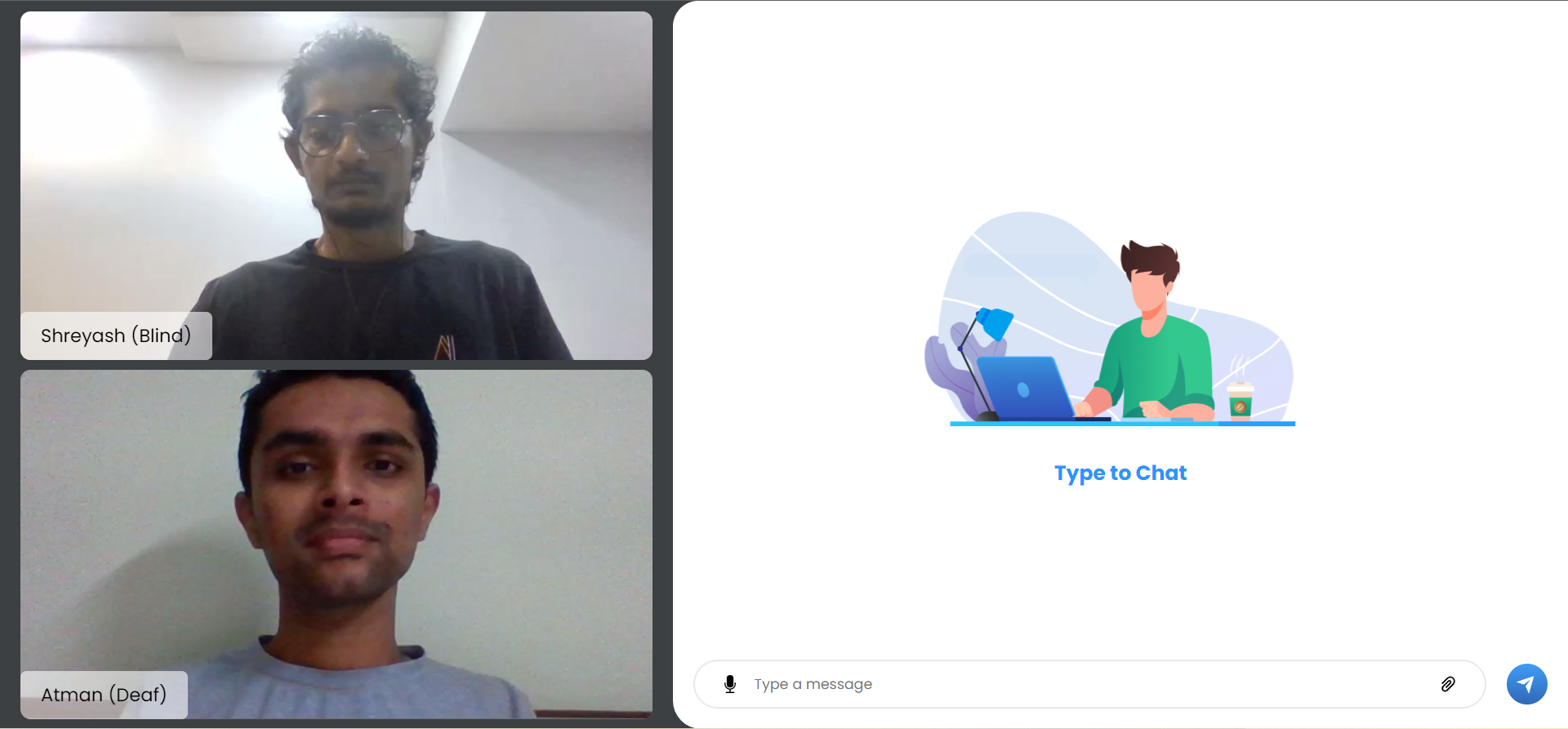
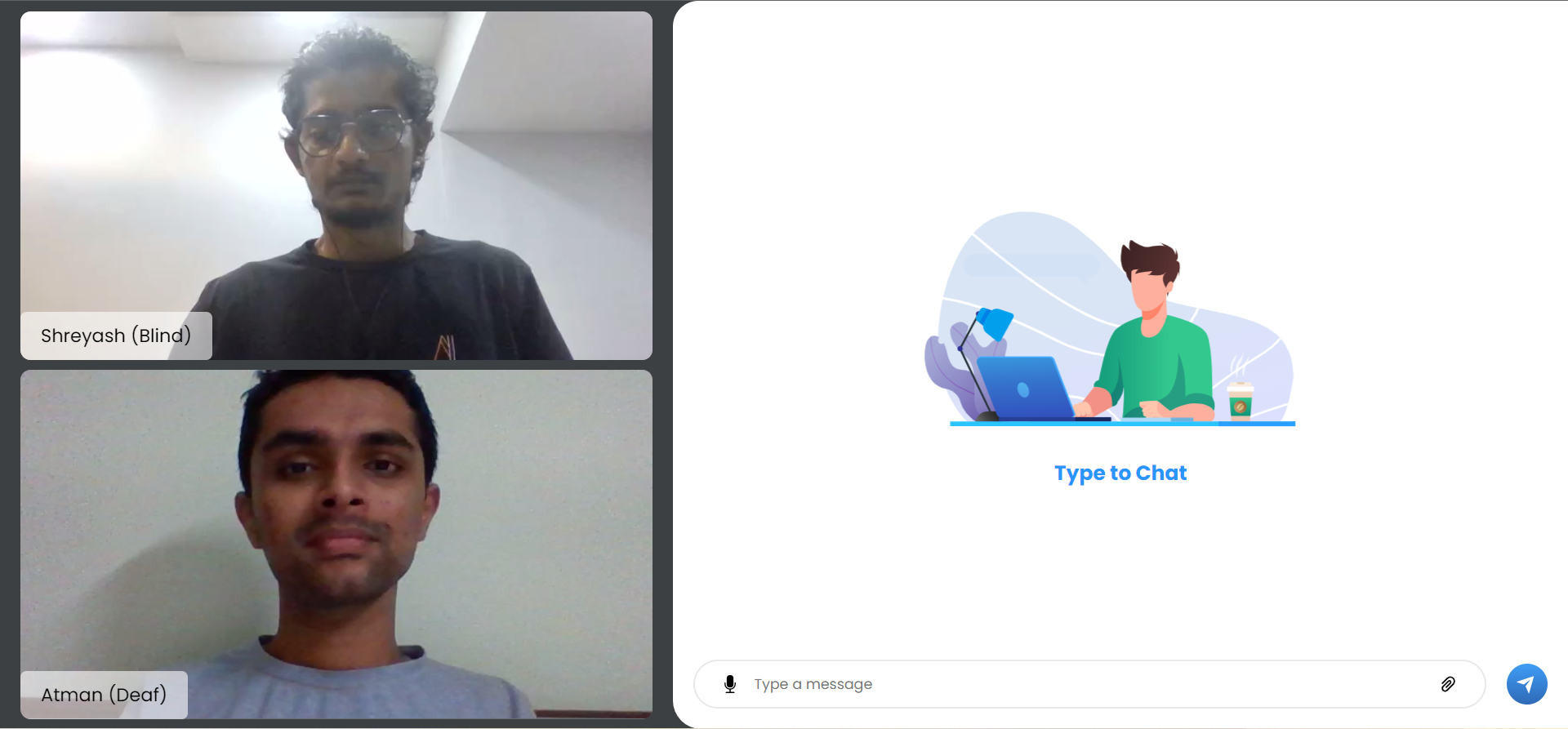
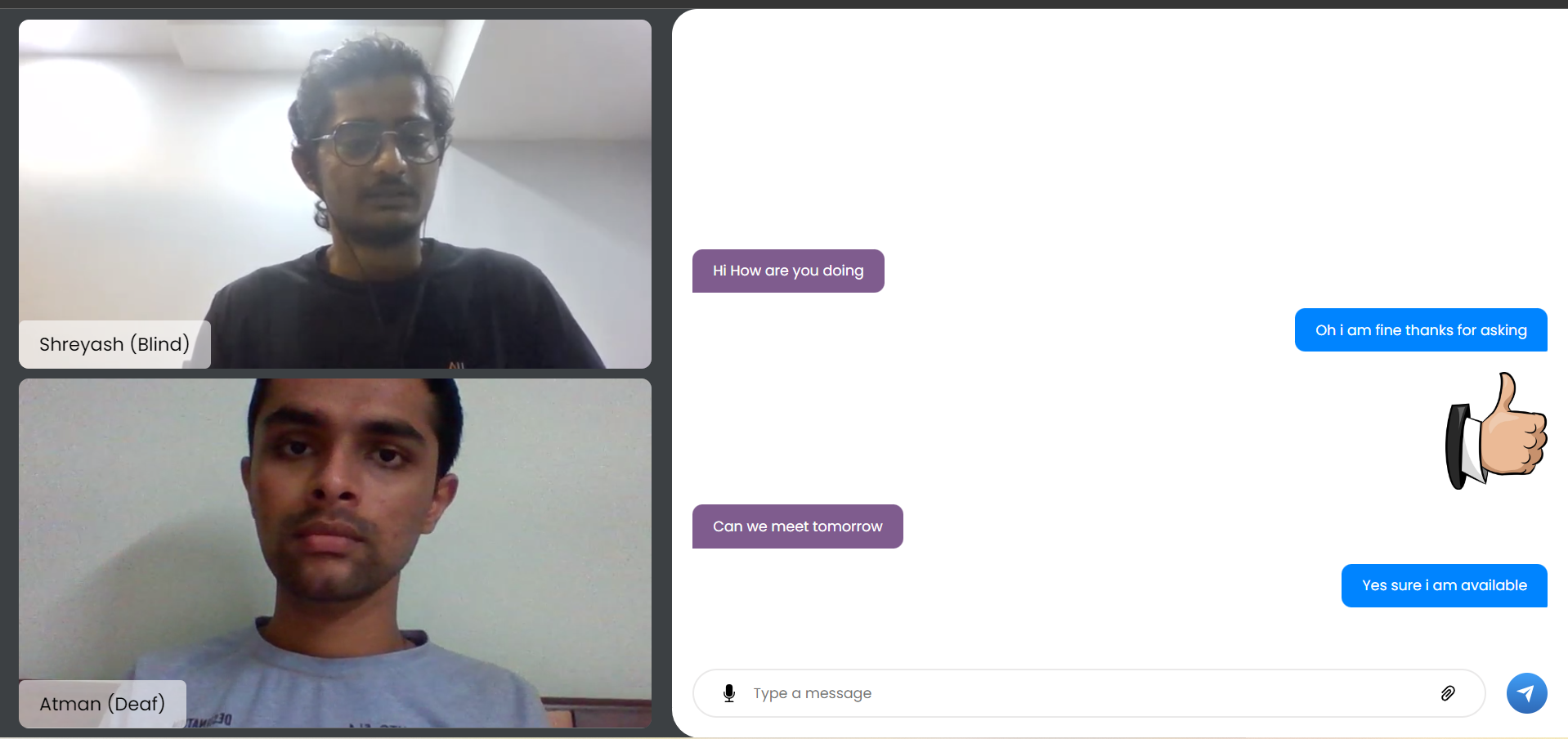
chat application
-

Quotes
-

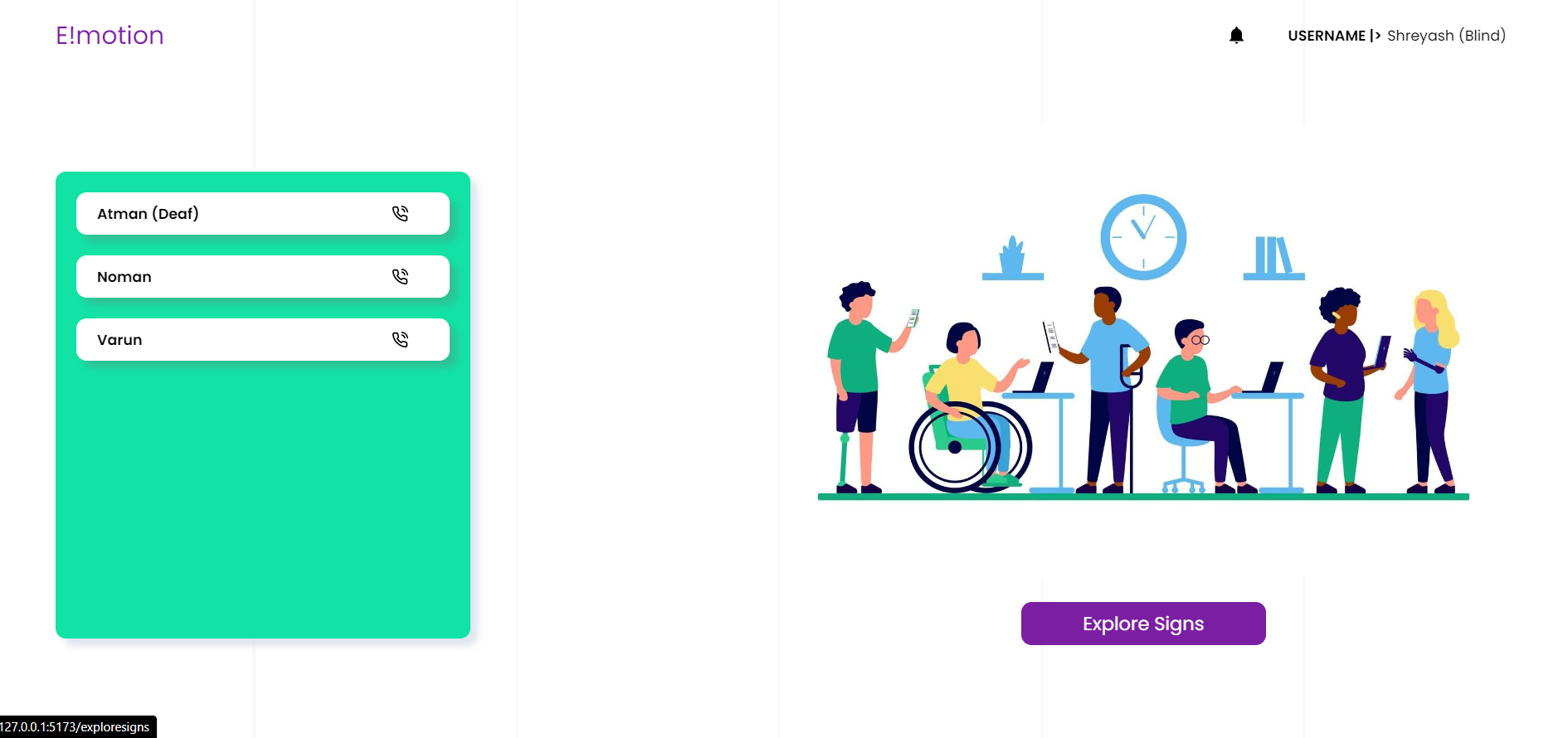
Homepage
-
Login/Logout
-
chat application
-
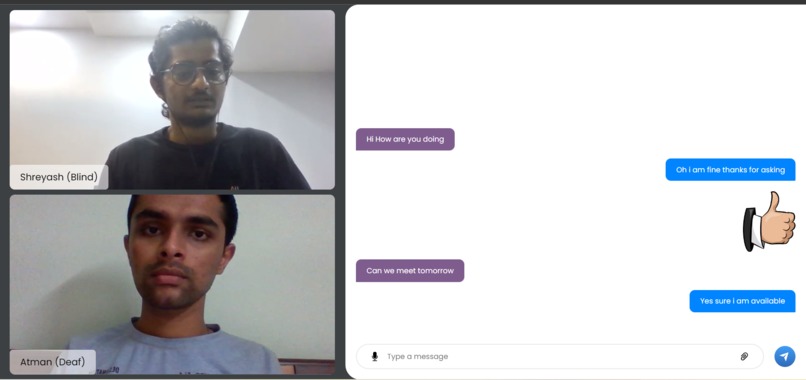
Chat application
-

Sign Language Signature

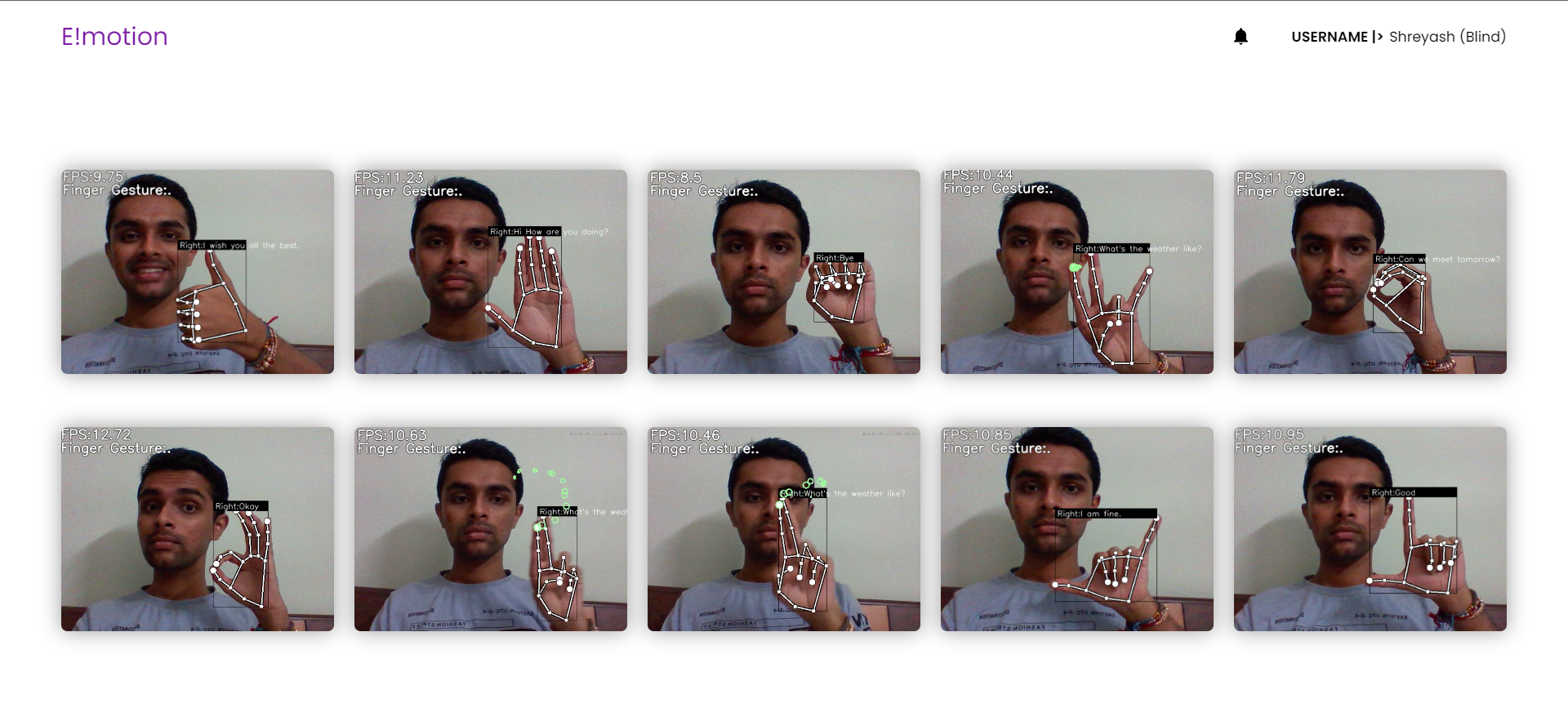
Inspiration
We once went to Mirchi and Mime, a restaurant that allows mimes to earn their livelihood by working at the restaurant. We noticed at the time that although we had several platforms to interact with our friends worldwide, there were none for the mime or the blind. Since that day, our mission has been to make the developmentally challenged feel more included as a community.
What it does
In a nutshell, it breaks the barrier to communicate with another individual via text alone. A deaf individual can gesticulate in front of a video camera using our technology. Our backend machine learning model would collect it, recognize it properly, and deliver it to the other end. If there is a blind person on the other end, the text will be converted to voice. If a blind person desires to respond, the procedure will be repeated, with the end product being a sign language display.
How we built it
After deciding upon the problem statement, we brainstormed a few ideas for different Machine Learning models which can be implemented to achieve the required output with the provided inputs. One solution was to use a machine learning model which takes the key points marked on the hands as the input. The model was trained based on the relative distance between the key points and then a sign is correctly identified. The client side of the application is built using ReactJS and the serverside is employing Django REST Framework.
Challenges we ran into
There were two major challenges faced during the hacking phase by our team.
- Streaming the Data for Model to the Frontend using Django Channels
- Streaming the video to the model in the form of frames from the frontend using asynchronous Django channels took a lot of time to execute.
- Text-to Speech Navigation of website
- Initially we tried implementing text-to-speech on the server side using gtts.py but this caused an additional performance reduction on the client side due to which we switched to SpeechSynthesisUtterance javascript constructor
- ML Challenges
- We had difficulty finding the dataset of signs corresponding to phrases. Hence, we made our own dataset. We also tackled different compatibilities of different python libraries. Integration of the machine learning model with the web app was another obstacle that we came across.
Accomplishments that we're proud of
We were able to implement more than we thought we would be able to implement during the start of the hackathon. The following objectives were achieved & implemented :
- An elegant UI which provides a smooth user experience and touchless workflow implementing text-to-speech.
- Consistent APIs for optimised performance and sockets for consistent connectivity with clients.
- Machine learning Model to identify hand gestures in the form of signs.
- Clean Code & good coding practices were followed.
- A step towards normalising chat for physically challenged users.
What we learned
We stumbled upon many challenges as mentioned above through these challenges we were successful in equipping ourselves with new skills like implementing and using WebSockets, learning and implementing new concepts and technologies, and also strengthened our existing skills like teamwork, UI/UX development, and pair programming.
What's next for E-Motional Quotient
We would love a future collaboration with Mirchi and Mime, our inspiration for this venture. We wish to add a feature of the group chat to increase the communication spectrum. We were also thinking of adding an image captioning technology for users to share media so that even blind people can appreciate the media sent to them.











Log in or sign up for Devpost to join the conversation.