-
-
front page
-
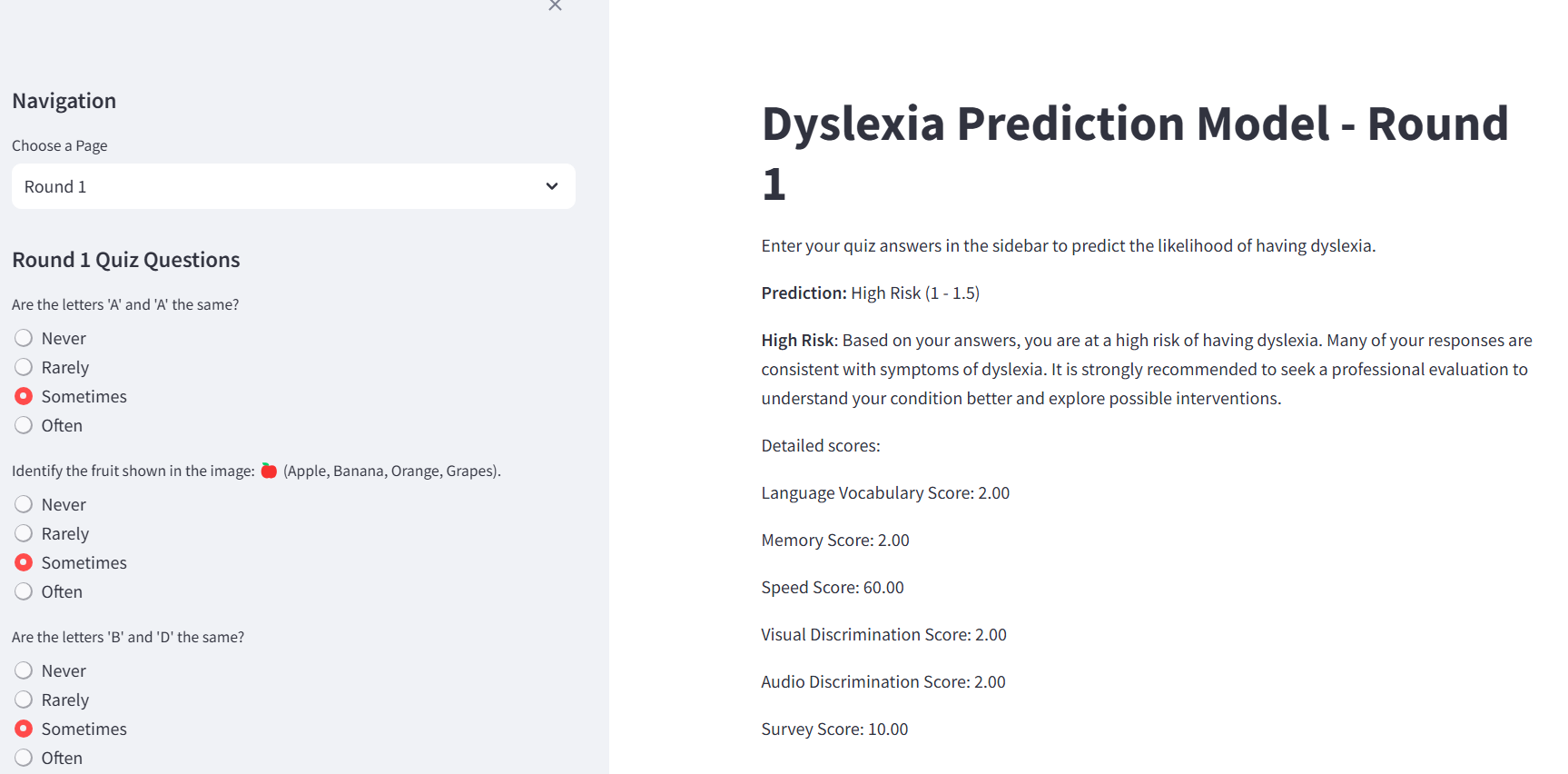
round 1
-
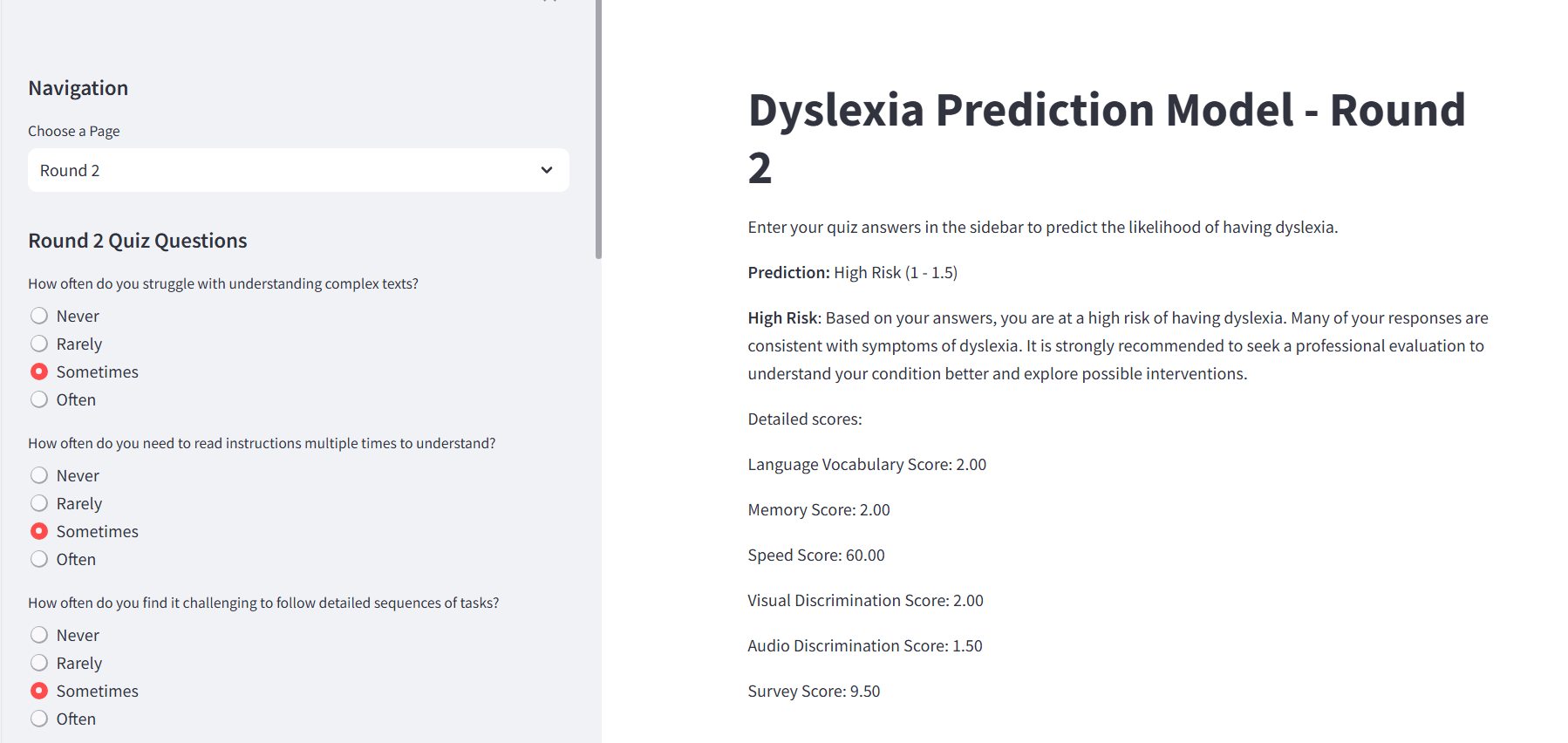
round 2
-
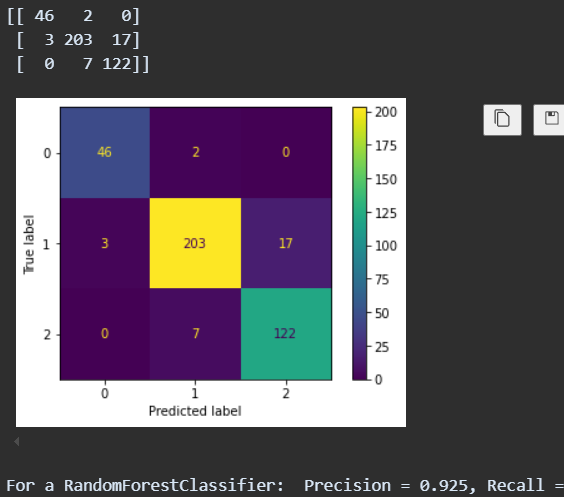
random forest classifier confusion matrix
Inspiration
Dyslexia is a complex neurodevelopmental disorder that significantly impacts reading and language processing abilities. Despite its prevalence and profound effects on individuals' lives, dyslexia often goes undiagnosed until later stages of education, leading to prolonged difficulties and a lack of appropriate interventions. This research aims to leverage the power of machine learning to develop a scalable, efficient, and objective tool for dyslexia screening. By integrating a web-based data acquisition tool with advanced machine learning algorithms, we seek to create an accessible platform that can rapidly assess dyslexia risk based on behavioral and cognitive patterns.
What it does
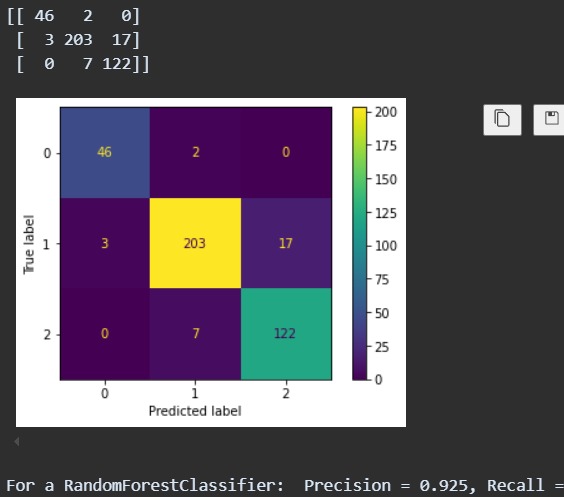
The Dyslexia Risk Assessment Tool utilizes various machine learning models to predict dyslexia risk based on cognitive and behavioral traits. Key features include: performance comparison of multiple models (Decision Tree, Random Forest, SVM), comprehensive metrics analysis (Precision, Recall, F1-score, Error Rate), Random Forest model with grid search optimization emerged as the top performer, web-based survey tool for data collection, and user-friendly interface for displaying assessment results and recommendations.

How we built it
The architecture of the dyslexia risk assessment system integrates various components seamlessly, from data acquisition to final prediction and storage. The process begins with open source data acquisition, where public datasets containing cognitive and behavioral traits are collected. This data is crucial for training the machine learning models. The training phase involves using several algorithms, including Decision Trees (DT), Random Forests (RF), Support Vector Machines (SVM), k-Nearest Neighbours (k-NN), and Logistic Regression. These models are trained on the collected data to predict dyslexia risk.
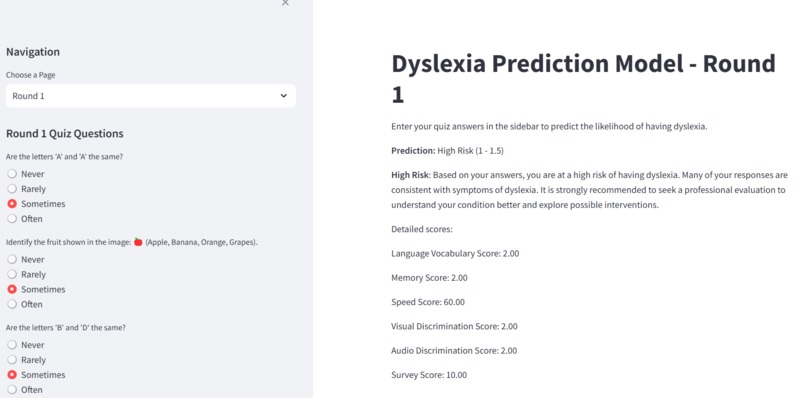
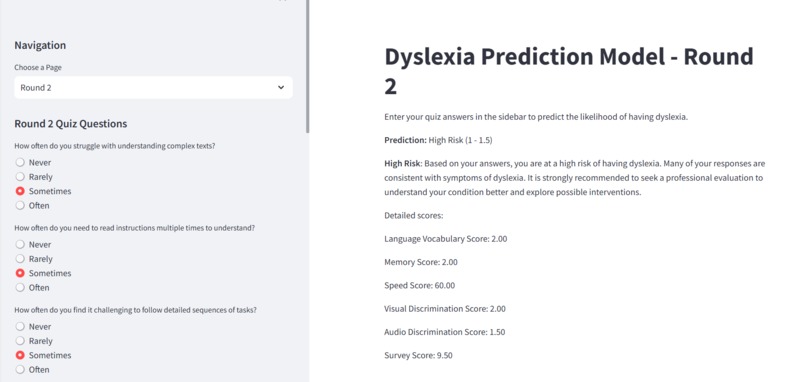
Following the training phase, Grid Search Optimization is employed to fine-tune the hyperparameters of the Decision Trees and Random Forests, aiming to minimize error and enhance performance. The tool used for this optimization is Grid Search. After optimization, the system proceeds to collect survey data via a web-based survey tool. This tool gathers responses to questions designed to assess cognitive and behavioral traits, including language vocabulary, memory, speed, visual discrimination, and audio discrimination.
The collected survey data is then processed to calculate scores based on the five identified features. These scores are essential inputs for the trained and optimized machine learning models, which predict the dyslexia risk for each individual. The results of these predictions are then presented to users through an intuitive interface. This user dashboard displays assessment results and provides personalized recommendations based on the predictions.
Challenges we ran into
Integrating diverse datasets and ensuring their compatibility was a significant challenge. Optimizing hyperparameters to improve model accuracy required extensive experimentation and computational resources. Designing an intuitive and user-friendly interface for non-technical users posed its own set of challenges, ensuring that the interface was accessible and easily navigable. Ensuring the reliability and robustness of the machine learning models to provide accurate predictions was also a critical aspect of the development process.
Accomplishments that we're proud of
We successfully developed a comprehensive dyslexia risk assessment tool that combines data acquisition, machine learning model training, and an intuitive user interface. Our tool not only performs well in predicting dyslexia risk but also democratizes access to early screening and intervention strategies. From the combined results, it is evident that higher scores in language vocabulary, memory, speed, visual discrimination, and audio discrimination generally correlate with a lower risk of dyslexia. Applicants who scored higher in these areas are more likely to receive a label of '2', indicating a low possibility of dyslexia. Conversely, those with slightly lower scores tend to be labelled as '1', indicating a moderate risk. This pattern suggests that the model effectively captures the nuances of cognitive and perceptual abilities in its predictions. The integration of detailed survey data with the prediction model allows for a nuanced assessment of dyslexia risk, reinforcing the importance of comprehensive evaluations in identifying individuals who may benefit from targeted interventions. The analysis confirms the model's robustness in utilizing survey metrics to accurately predict the likelihood of dyslexia, providing a valuable tool for early identification and support.
What we learned
Throughout this project, we learned the importance of early intervention and accurate diagnosis for dyslexia. We discovered the potential of integrating machine learning with web-based tools to enhance the accessibility and efficiency of screening processes. Optimizing machine learning models was crucial for improving performance and reliability, and we gained valuable insights into balancing model complexity and interpretability.
What's next for Dyslexia Risk Assessment Tool
For future studies, several enhancements can be considered to improve the dyslexia prediction model and its application:
- Expanded Dataset: Increasing the dataset size and diversity would help in training a more robust model that generalizes better across different populations.
- Feature Expansion: Including additional cognitive and perceptual metrics, such as working memory, attention span, and phonological processing, could enhance the model's predictive accuracy.
- Longitudinal Studies: Conducting longitudinal studies to track changes in cognitive and perceptual abilities over time would provide deeper insights into the progression and intervention outcomes for dyslexia.
- Intervention Suggestions: After detecting dyslexia, incorporating a suggestions column in the analysis can guide users towards appropriate interventions. For instance, a chatbot could be integrated to provide personalized recommendations for educational resources, therapy options, and coping strategies based on the detected risk level.
- Real-time Feedback: Implementing real-time feedback mechanisms within the survey platform could engage users more effectively and provide immediate insights into their cognitive strengths and areas needing improvement.
- User Interface Improvements: Enhancing the user interface to make it more intuitive and user-friendly would improve the overall user experience, making the survey and prediction process more accessible.
- Cross-disciplinary Collaboration: Collaborating with educators, psychologists, and neuroscientists can help refine the model by incorporating expert knowledge and ensuring that the predictions are practically applicable and beneficial in educational settings.
Built With
- machine-learning
- python
- streamlit


Log in or sign up for Devpost to join the conversation.