-
-
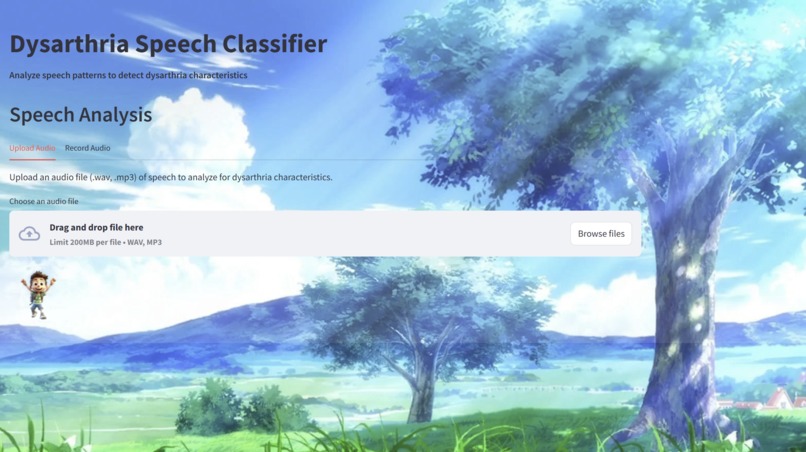
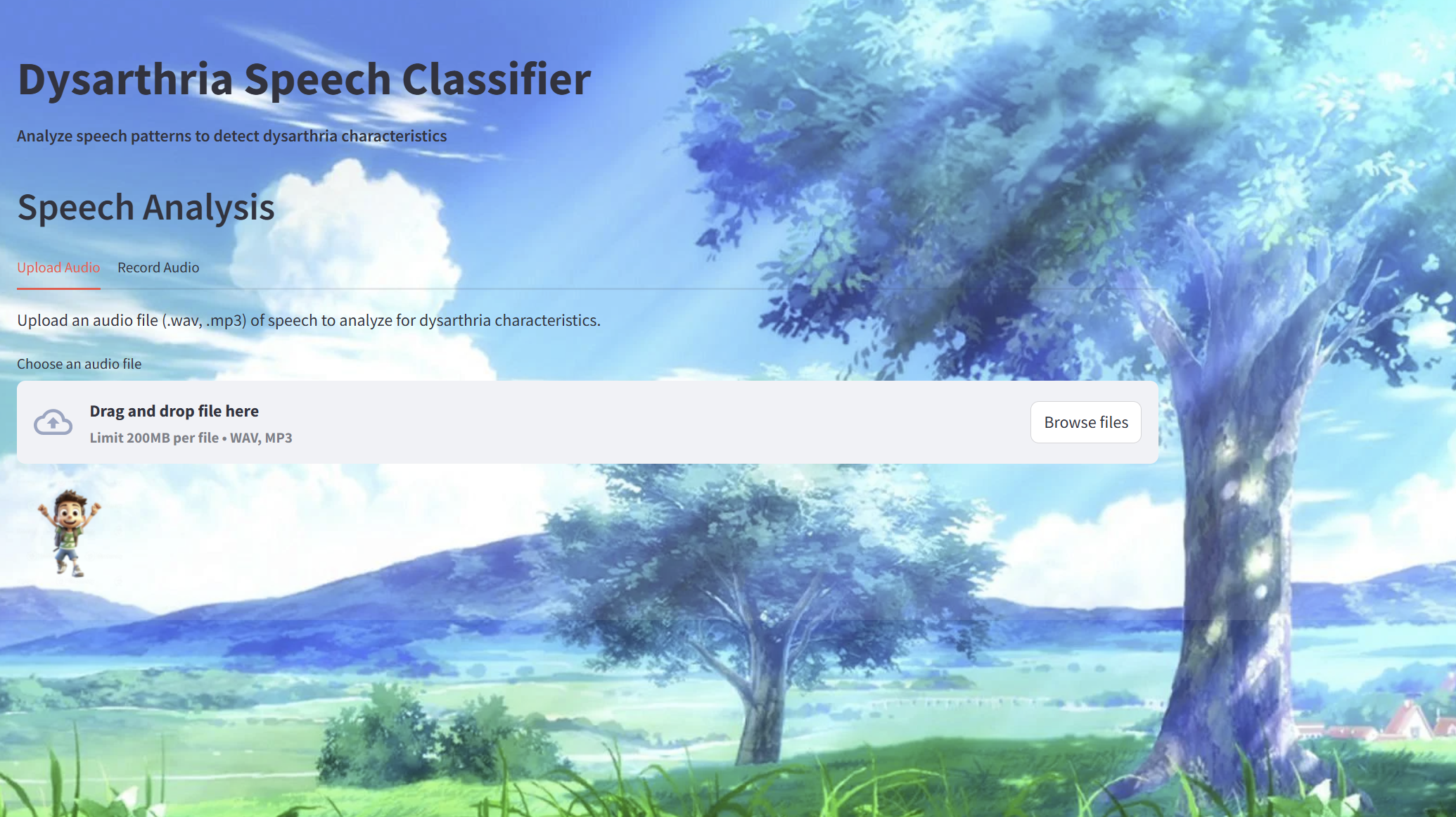
Project Web App
-
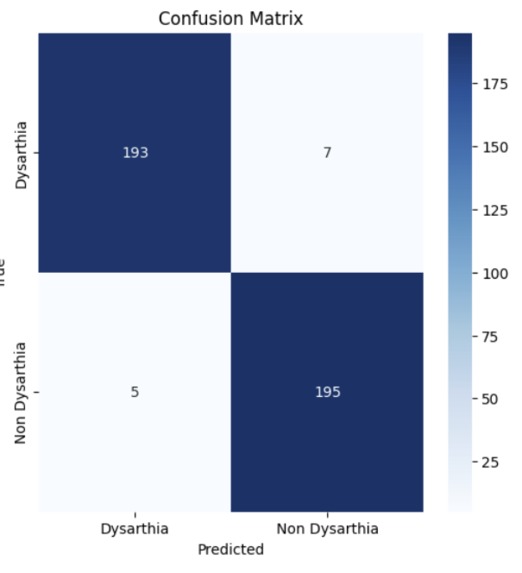
Confusion Matrix
-
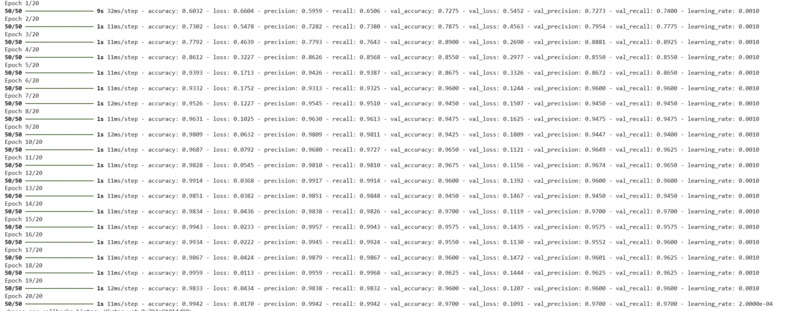

Inspiration
Many people who have difficulty pronouncing words often face the dilemma of whether they need a speech evaluation. However, getting an assessment is very expensive, especially in 2025, and these high costs can hinder certain individuals. Our project will allow users to record their voices and will give them instant results on the percent chance that they have dysarthria.
What it does
Our project allows users to record their voice for 5 seconds. After 5 seconds, the recording stops on its own, and the system automatically analyzes the voice in the recording and provides an instant result, indicating the percentage likelihood of the user having dysarthria.
How we built it
Data Preprocessing: We began by reading all the .wav files from a zip file and processed them using the librosa library to extract MFCC (Mel-Frequency Cepstral Coefficients) features for each file. After extracting the MFCCs, we created a Pandas DataFrame containing the MFCC features, and their corresponding category labels based on the file path. We handled any corrupted or problematic files by catching exceptions like EOFError, ensuring the program continued without interruption. Once the valid audio files were processed, we compiled the extracted MFCC features into a list and removed any corresponding category labels for invalid files. Then, we converted the features into a DataFrame and appended the category labels, resulting in the final dataset ready for training.
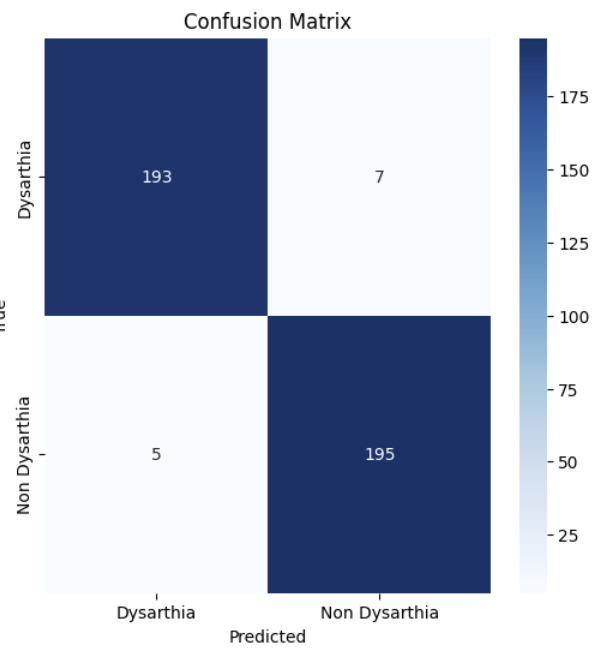
Model Training: We ran sklearn train_test_split to split the data into train and test set. To ensure that there is a balance between Dysarthria, we stratified the response column (category label column). Once sklearn train_test_split was completed, we trained the model through CNN, MaxPooling1D, LSTM layers. The model was able to achieve a validation accuracy, precision, and recall of 97.00%.
UI Design: Used the trained model to create a streamlit app that allows users to record their voice for 5 seconds and determine the percent chance they have Dysarthria.
Challenges we ran into
Initially, our web app wasn't able to record our voices. When we clicked stop recording, it would just refresh and not capture anything. To fix that, we first removed the stop button and instead decided to incorporate 'time' function in python, where if time.time() was greater than 5, we would stop the recording and analyze the voice. This helped fix our error and make prediction through our voice.
Accomplishments that we're proud of
We are proud that we achieved a validation accuracy, precision, and recall of 97%. This means that our model correctly predicted dysarthria or non-dysarthria 97% of the time (accuracy). Additionally, the model's precision of 97% indicates that when it predicted dysarthria, it was correct 97% of the time, minimizing false positives. The recall of 97% shows that the model was able to identify 97% of all actual dysarthria cases, minimizing false negatives. These numbers make our model reliable.
What we learned
We learned how to design a streamlit app and make predictions through our voices. To make predictions, we process our voice into a wav file and then extract the MFCC features of the wav file through librosa and then use the model to make predictions.
What's next for Dysarthria Detector
We plan to incorporate features that can provide therapy for individuals with Dysarthria. Firstly, we would like to incorporate some fun games like Charades, and Pronunciation Challenge, which will allow the users to practice their speech in a fun way. In Pronunciation Challenge, the user will be asked to pronounce some words by the AI. If they correctly pronounce it, they get a point. If they miss it, they will get thorough feedback on what they can do to improve next time. Their goal is to get the highest possible score. For Charades, the AI will describe an object, and the user will say the name of the object. They get a point for correctly guessing and pronouncing the object.
In addition to games, we plan to incorporate a one-on-one session, where the user and the AI work through some exercises to enhance the user's speech. It will operate like a mini speech therapy session.
Built With
- cnn
- lstm
- maxpooling1d
- sklearn
- streamlit
- tensorflow

Log in or sign up for Devpost to join the conversation.