Inspiration
Your team uses AI agents every day — code reviews, pipeline fixes, code generation. But nobody can answer: What exactly did your AI agents do? How much did they cost? Are they getting better over time?
DuoLens is the missing governance layer. Inspired by Readout.org — a unified AI agent dashboard — we set out to build the same observability experience natively within GitLab, using nothing but the Duo Agent Platform.
What it does
DuoLens provides three custom flows on the GitLab Duo Agent Platform:
| Flow | Purpose |
|---|---|
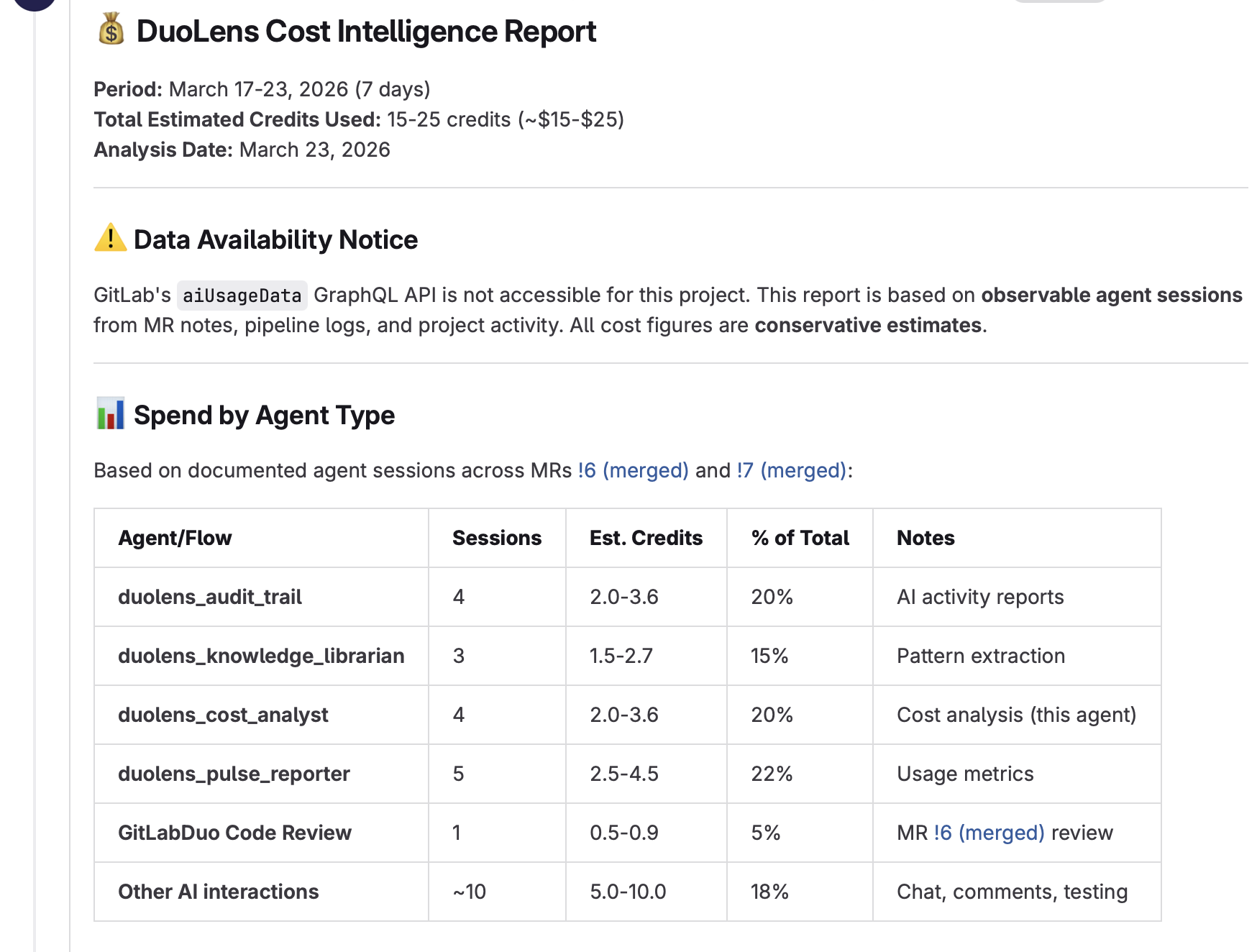
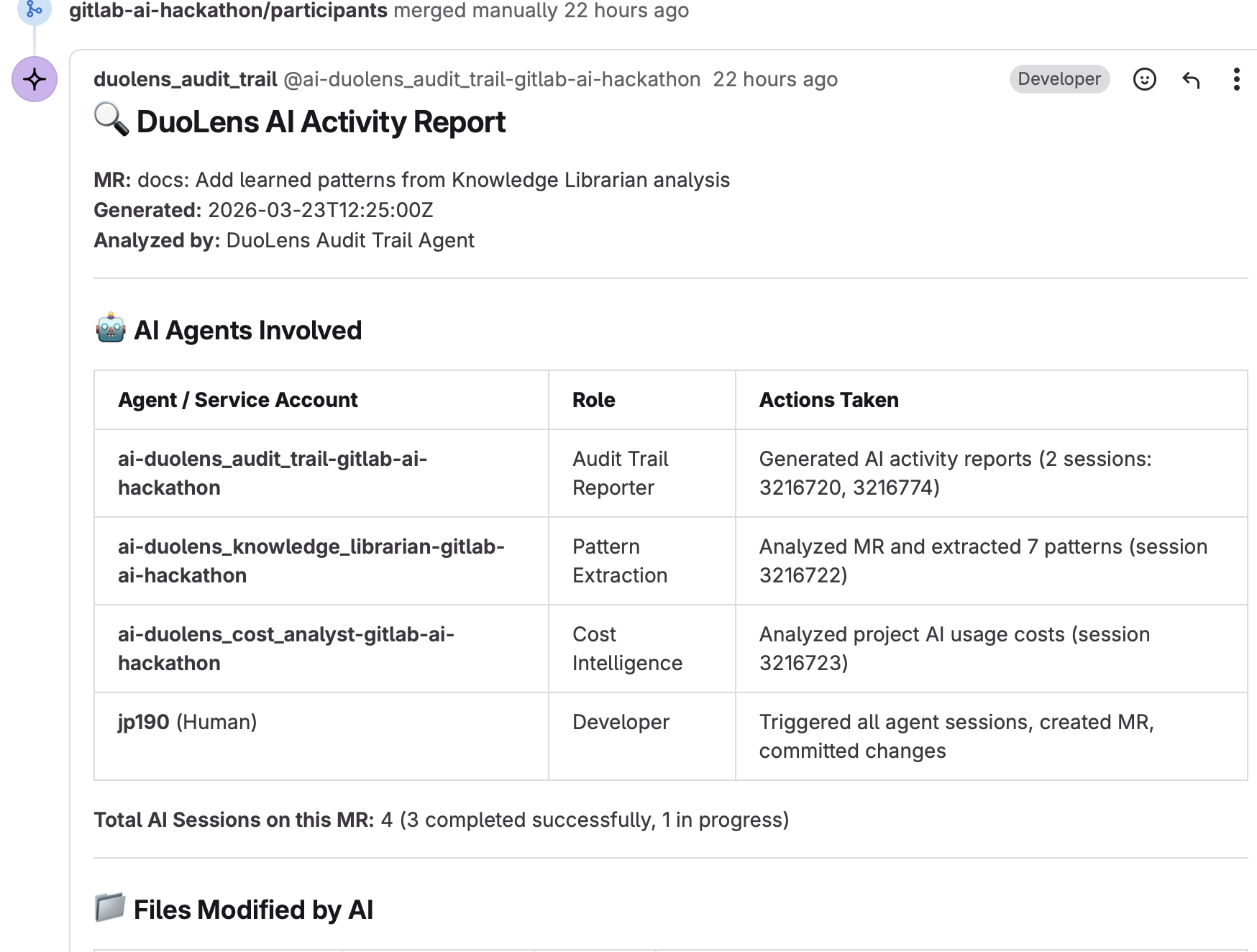
| 🔍 Audit Trail | Generates compliance-ready AI Activity Reports — documenting what agents did, files changed, and decisions made |
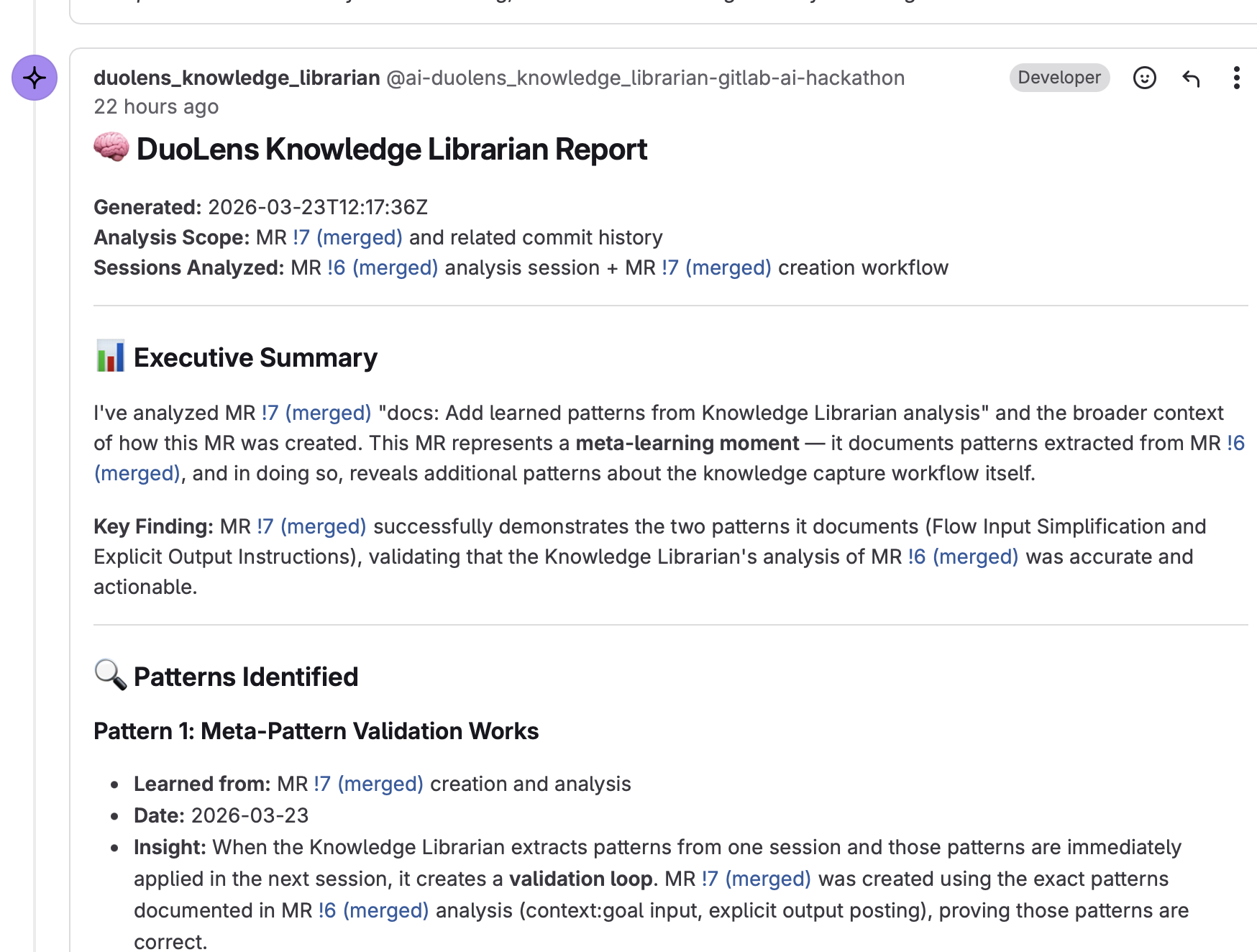
| 🧠 Knowledge Librarian | Extracts patterns from agent sessions and builds institutional memory in AGENTS.md |
| 💰 Cost Analyst | Tracks AI credit consumption, forecasts spend, and recommends cost optimizations |
All flows are triggered by simply @mentioning a service account on any MR or Issue.
How we built it
- Designed flow YAML configs with system prompts for each agent persona
- Synced to AI Catalog via CI/CD pipeline with semantic versioning
- Iterated on prompts based on real agent behavior — learning that agents need explicit instructions to post output
- Tested across 30+ pipeline runs and 17+ agent sessions on real MRs
Tech stack: GitLab Duo Agent Platform, Custom Flows (AI Catalog), Anthropic Claude Sonnet 4, GitLab GraphQL & REST APIs, Python (FastAPI backend), YAML configurations
Challenges we faced
- API Limitations:
aiUsageDataGraphQL returns null in the hackathon environment (requires Duo Enterprise). We adapted with activity-based cost estimates. - Token Scope Bug: Composite identity tokens lack
read_api, causing 403 errors on startup — a known GitLab issue (#592015). Flows still work despite this. - Prompt Compliance: Agents sometimes ignored instructions to auto-fetch context. We strengthened prompts with "CRITICAL" directives.
- Platform Issue: Pulse Reporter flow has a WebSocket issue we couldn't resolve — documented for future work.
What we learned
- Use
context:goalas primary input — let agents fetch context dynamically - Make "post your findings" a mandatory final step — agents won't post unless explicitly told
- Every prompt action needs a matching tool in the toolset
- Users prefer transparent approximations over false precision when data is unavailable
What's next
- 📊 Readout-Style Dashboard — Unified observability UI
- 🔧 Pulse Reporter Fix — Resolve platform-level issue
- 📈 Token-Level Cost Tracking — When usage APIs become available
- 🔄 Scheduled Reports — Automatic weekly reports via pipeline schedules
Built With
- claude
- duo-agent
- fastapi
- gitlab
- python
- yaml

Log in or sign up for Devpost to join the conversation.